This is a Plain English Papers summary of a research paper called IberBench: Benchmark for Spanish, Portuguese, Catalan, Basque, Galician LLM Evaluation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introducing IberBench: A New Benchmark for Iberian Languages
Large Language Models (LLMs) have revolutionized natural language processing with their ability to understand and generate text across various tasks. However, evaluating these models remains challenging, particularly for languages beyond English. This gap is especially pronounced for languages spoken across the Iberian Peninsula and Ibero-America—Spanish, Portuguese, Catalan, Basque, and Galician—despite these languages being spoken by over 800 million people worldwide.
Existing benchmarks primarily focus on English, overlooking the rich linguistic diversity of Iberian languages. When non-English languages are included, the benchmarks tend to prioritize fundamental language capabilities over industry-relevant tasks and remain static rather than evolving with new data and tasks.
To address these limitations, researchers have developed IberBench, a comprehensive benchmark designed to evaluate LLMs across both fundamental and industry-relevant tasks in Iberian languages. IberBench integrates 101 datasets from evaluation campaigns and recent benchmarks, spanning 22 task categories from sentiment analysis to toxicity detection and summarization.
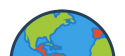
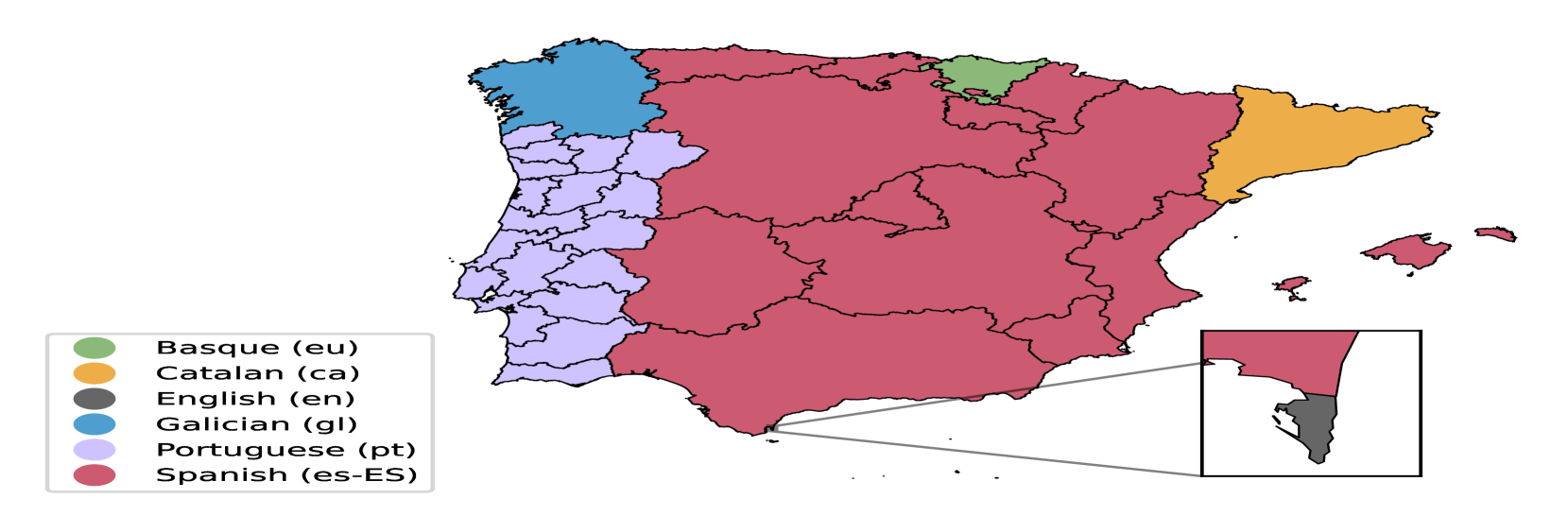
Maps showing the languages of the Iberian Peninsula and Spanish varieties in Ibero-America included in IberBench.
What sets IberBench apart is its focus on linguistic diversity, industry relevance, and extensibility. The benchmark enables continual updates through community-driven model and dataset submissions, moderated by an expert committee. This approach ensures IberBench remains relevant and comprehensive over time, unlike static benchmarks that quickly become outdated.
The Landscape of LLM Evaluation Methods
LLM evaluation typically follows two main approaches: human evaluation and automatic evaluation. Human evaluation, while insightful for measuring user preferences and ethical aspects, is subjective, costly, and potentially biased. In contrast, automatic evaluation offers faster, more cost-effective, and reproducible assessment of model capabilities.
Early automatic benchmarks like GLUE and MMLU measured fundamental language understanding and reasoning capabilities. More recent efforts such as LM Eval Harness, HELM, and the Open LLM Leaderboard expanded coverage to include industry-relevant tasks like sentiment analysis and toxicity detection.
While most evaluation work has focused on English, recent efforts have emerged for other language families. For Iberian languages specifically, initiatives like La Leaderboard, IberoBench, and Odesia have made important contributions. However, these efforts still fall short in capturing the full range of linguistic variation in Iberian languages, typically focus on fundamental rather than applied tasks, and lack mechanisms for continuous evolution.
IberBench builds upon these foundations by integrating both fundamental and industry-relevant tasks from established workshops (IberLEF, IberEval, TASS, PAN), including not only Spain's co-official languages but also varieties from Ibero-America, and implementing a framework that can grow over time with new datasets and languages.
Unlike most existing benchmarks that primarily focus on classification or generation tasks, IberBench also incorporates sequence labeling tasks such as Named Entity Recognition (NER), which are crucial for industrial applications but often overlooked in current evaluation frameworks.
The Architecture of IberBench: A Four-Component System
IberBench consists of four key components that work together to create a comprehensive evaluation ecosystem: the leaderboard UI, organization, datasets, and LLM evaluation pipeline.
IberBench overview showing how users interact with the system, review results, request model evaluations, and propose new datasets.
This architecture supports multilingual LLM evaluation through a user-friendly interface, expert-led quality control, standardized datasets, and a consistent evaluation methodology.
The User Interface: A Window into Model Performance
The IberBench leaderboard, hosted on HuggingFace Spaces, provides a comprehensive, interactive interface for exploring model performance. Users can view rankings across different task types, languages, and language varieties. The interface includes detailed metadata about each model, such as parameter size and evaluation scores, aggregated by various dimensions.
Visualization tools enable users to analyze performance trends across model sizes, types, and tasks. These visualizations help identify which models excel in specific tasks or languages, providing valuable insights for both researchers and practitioners.
The interface also includes a request portal for submitting new models for evaluation. Users must provide details like the model name, description, weight precision format, and whether it's pre-trained or fine-tuned. These requests undergo review by the organization to ensure compatibility and significance before evaluation.
For transparency, the leaderboard provides comprehensive information about each dataset, including source, task type, language, variety, and proper attribution to creators. Task categories are explicitly documented to ensure users understand how evaluations are organized and aggregated.
The Organization: Ensuring Quality and Integrity
The IberBench organization comprises seven experts from academia and industry with backgrounds in NLP, engineering, language ethics, and gender bias. Many have previously served as shared-task organizers or committee members in workshops like IberLEF and PAN, bringing valuable domain knowledge to guide the benchmark's development.
This committee establishes and enforces acceptance criteria for new models, datasets, and organization members. For models, preference is given to those trained specifically on Iberian languages, multilingual models with substantial Iberian language content, and models developed in Europe or Ibero-America. Similar priorities apply to datasets, with emphasis on Iberian languages, regional workshops, and coverage of underrepresented domains or language varieties.
Beyond governance, the organization handles practical tasks like running evaluations for newly accepted models and processing new datasets. This includes downloading, normalizing, and securely storing datasets in private repositories to prevent contamination of future model training.
The Datasets: A Comprehensive Collection
The 101 datasets in IberBench come from workshops like IberLEF, IberEVAL, TASS, and PAN, as well as from existing benchmarks. The researchers obtained explicit permission from dataset creators for inclusion in IberBench, ensuring proper attribution and ethical reuse.
A custom normalization pipeline processes datasets in various formats (Excel, CSV, HuggingFace datasets, plaintext), standardizing column names, cleaning textual artifacts, and adding language annotations. Processed datasets are uploaded to a private HuggingFace repository with appropriate metadata.
Sequence labeling tasks required special handling with a custom annotation schema. This schema instructs LLMs to produce span-annotated outputs by enclosing each annotated span within corresponding label tags.
| Dataset preparation | |
|---|---|
| Text | Real Madrid lose against Valencia CF in Madrid |
| Reference labels | [B-football.team, I-football.team, O, O, B-football.team, I-football.team, O, B-location] |
| Annotated example | Real Madrid lose against Valencia CF in Madrid |
| Evaluation | |
| Prompt | Your task is to perform Named Entity Recognition by wrapping each entity from the input text with label tags. The set of label tags you can use are: football.team, and location. Wrap all your response between ... . Here are some examples: Text: OpenAI is developing GPT-5. Labels: OpenAI is developing GPT-5 Text: Real Madrid lose against Valencia CF in Madrid. Labels: Real Madrid lose against Valencia CF in Madrid Text: FC Barcelona is playing in Barcelona |
| LLM output | FC Barcelona is playing in Barcelona |
| Parsed output | [B-football beam, I-football team, O, O, O, B-location] |
Example of dataset preparation and evaluation for a Named Entity Recognition task, showing how sequences are annotated and how model outputs are parsed.
The Evaluation Pipeline: Measuring LLM Performance
IberBench evaluates autoregressive LLMs through a systematic process that transforms input texts into prompts, feeds them to models, and compares the generated outputs with reference answers. The evaluation methodology varies by task type:
For classification tasks, the model computes the likelihood of each candidate label and selects the one with the highest probability. For generation tasks, greedy decoding ensures reproducible outputs that can be compared with reference texts using metrics like ROUGE-1. For sequence labeling, the model follows a specific annotation schema that instructs it to mark entities directly in the text.
The evaluation pipeline relies on lm-evaluation-harness, a widely-used open-source tool for LLM assessment. IberBench extends this tool with custom task types and metrics suited to Iberian language evaluation needs.
Comprehensive Evaluation of Iberian Language Models
IberBench evaluates a diverse set of multilingual language models spanning different sizes, architectures, and language specializations. This comprehensive assessment provides valuable insights into model capabilities across Iberian languages.
Models Under the Microscope: From 100M to 14B Parameters
The LLM ecosystem for Iberian languages remains relatively limited compared to English. Most existing models are either multilingual LLMs with some Iberian language support or adaptations of general models to specific Iberian languages through additional training. Few models have been pre-trained from scratch specifically for Iberian languages.
IberBench evaluates 23 LLMs across three categories:
- Multilingual models not specialized in Iberian languages (e.g., phi-4, Llama 3.1/3.2, Qwen 2.5)
- Models pre-trained from scratch for Iberian languages (e.g., Salamandra, EuroLLM)
- Models adapted from existing multilingual models to specific Iberian languages (e.g., RigoChat-7b-v2 for Spanish, Latxa-Llama-3.1-8B-Instruct for Basque)
| Model Name | Type | Num. Params (billions) | Pre-training Languages | Fine-tuning Languages |
|---|---|---|---|---|
| phi-4 [20] | $\checkmark$ | 14.1 | es, en, pt | ? |
| EuroLLM-9B-Instruct [22] | $\checkmark$ | 9.1 | es, en, ca, pt, gl | es, en, ca, pt, gl |
| EuroLLM-9B [22] | 9.1 | es, en, ca, pt, gl | - | |
| CataLlama-v0.2-Instruct-SFT [94] | $\checkmark$ | 8.0 | es, en, pt | ca |
| Llama-3.1-8B-Instruct [3] | $\checkmark$ | 7.5 | es, en, pt | es, en, pt |
| Latsa-Llama-3.1-8B-Instruct [18] | $\checkmark$ | 7.5 | es, en, pt | eu |
| Qwen2.5-7B-Instruct [4] | $\checkmark$ | 7.1 | es, en, pt | ? |
| RigoChat-7b-v2 [93] | $\checkmark$ | 7.1 | es, en, pt | es |
| Mistral-7B-Instruct-v0.3 [90] | $\checkmark$ | 7.1 | es, en | ? |
| salamandra-7b-instruct [21] | $\checkmark$ | 6.7 | es, en, ca, pt, gl, eu | es, en, ca, pt, gl, eu |
| sabia-7b [95] | 6.7 | es, en, pt | - | |
| Aitana-6.3B [96] | 6.3 | es, en, ca | - | |
| Qwen2.5-3B-Instruct [4] | $\checkmark$ | 3.1 | es, en, pt | ? |
| Llama-3.2-3B-Instruct [3] | $\checkmark$ | 3.2 | es, en, pt | es, en, pt |
| phi-4-mini-instruct [89] | $\checkmark$ | 3.8 | es, en, pt | ? |
| gemma-2-2b-it [92] | $\checkmark$ | 2.6 | en | en |
| salamandra-2b-instruct [21] | $\checkmark$ | 1.7 | es, en, ca, pt, gl, eu | es, en, ca, pt, gl, eu |
| EuroLLM-1.7B-Instruct [22] | $\checkmark$ | 1.7 | es, en, ca, pt, gl | es, en, ca, pt, gl |
| EuroLLM-1.7B [22] | 1.7 | es, en, ca, pt, gl | - | |
| Qwen2.5-1.5B-Instruct [4] | $\checkmark$ | 1.5 | es, en, pt | ? |
| Llama-3.2-1B-Instruct [3] | $\checkmark$ | 1.2 | es, en, pt | es, en, pt |
| Qwen2.5-0.5B-Instruct [4] | $\checkmark$ | 0.5 | es, en, pt | ? |
| gpt2 [91] | 0.1 | en | - |
LLMs evaluated in IberBench, showing model name, type (base or instruction-tuned), parameter count, and languages included in pre-training and fine-tuning.
The evaluation uses a zero-shot approach, where models receive task descriptions without examples. This choice reflects real-world usage scenarios where users often lack the expertise or data to provide effective examples.
Performance Analysis: What the Results Tell Us
The evaluation reveals several important insights about LLM capabilities across Iberian languages.
Performance comparison across model sizes, showing how different model families scale with parameter count.
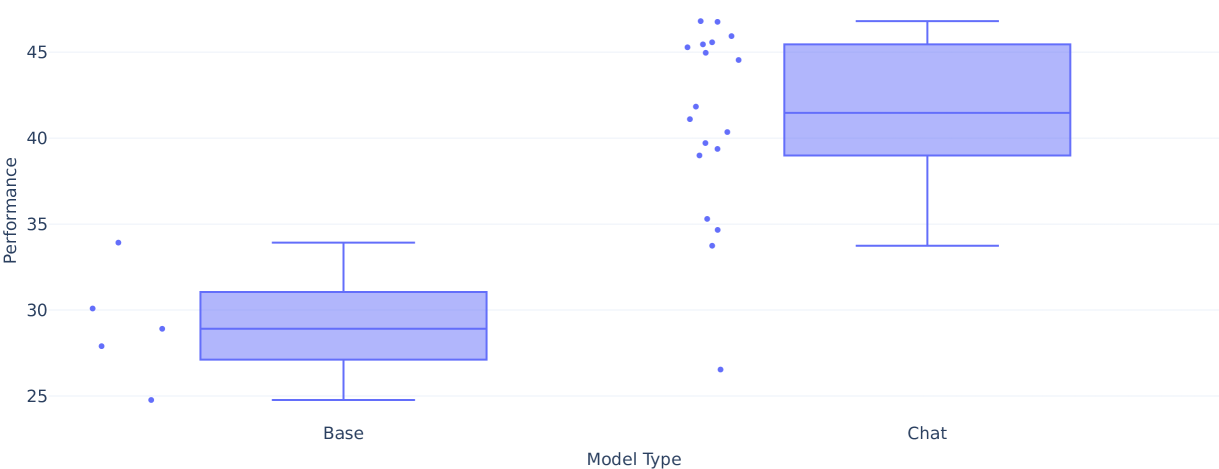
Performance comparison between base models and instruction-tuned models, demonstrating the clear advantage of instruction tuning.
Key findings include:
Qwen-2.5 family dominates: Qwen-2.5-7b-Instruct leads the benchmark with a mean score of 46.8%, closely followed by RigoChat-7b-v2 (46.7%) and Qwen-2.5-3b-Instruct (45.9%).
Language specialization has tradeoffs: Fine-tuning for specific languages can both help and harm performance. For example, RigoChat-7b-v2 performs better on Spanish than its base model Qwen-2.5-7b-Instruct, but slightly worse overall.
Mid-sized models perform best: Models with 3-10 billion parameters dominate the leaderboard, with both smaller models and the larger phi-4 (14B) underperforming. Scaling laws hold within model families but don't guarantee better cross-family performance.
European LLMs lag behind: European flagship models like salamandra-7B-Instruct and EuroLLM-9B-Instruct perform on par with or below models like Qwen-2.5-7B-Instruct, despite comparable or larger parameter counts.
Instruction tuning is crucial: LLMs focused on Iberian languages are competitive only when instruction-tuned. Base models consistently underperform relative to their instruction-tuned counterparts.
Random baseline often wins: 39% of evaluated models performed below the random baseline, highlighting the challenge of effective multilingual modeling. Only instruction-tuned models with more than 2B parameters consistently beat random guessing.
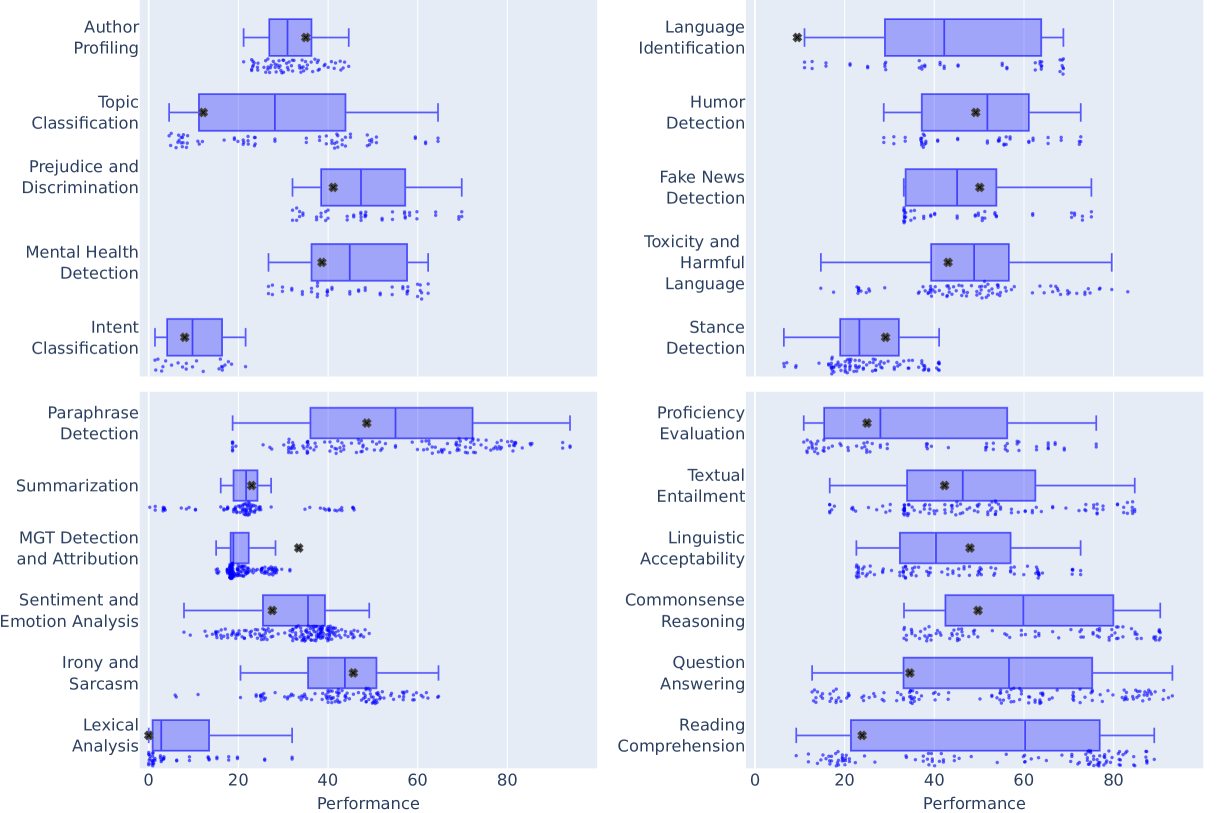
Performance comparison across task categories, showing which tasks remain challenging and which are better addressed by current models.
Analysis by task category reveals that LLMs perform significantly better on fundamental language tasks than on industry-relevant ones. Reading comprehension, linguistic acceptability, and proficiency evaluation see the strongest results, while tasks like lexical borrowing detection, intent classification, and machine-generated text detection remain nearly unsolved.
The evaluation also shows substantial performance differences across languages. Models typically perform best on Spanish, followed by Portuguese, Catalan, and English. Performance drops significantly for Galician and Basque, with scores often closer to the random baseline. This pattern reflects the relative prevalence of these languages in model training data and highlights the need for better representation of lower-resource Iberian languages.
Key Findings and Future Directions
IberBench provides a comprehensive framework for evaluating LLMs across Iberian languages, addressing key limitations in existing benchmarks. By including 101 datasets across 22 task categories, it enables robust assessment of both fundamental language capabilities and industry-relevant applications.
The evaluation of 23 LLMs ranging from 100 million to 14 billion parameters reveals important insights:
- LLMs struggle more with industry-relevant tasks than fundamental language tasks
- Galician and Basque present greater challenges than other Iberian languages
- Several tasks remain largely unsolved, with top models barely outperforming random guessing
- Even on more tractable tasks, LLMs still underperform compared to specialized systems from shared tasks
IberBench's open-source infrastructure supports every stage of benchmarking, from dataset processing to model evaluation. The public leaderboard hosted on Hugging Face promotes transparency and facilitates community collaboration.
Looking forward, the researchers plan to benchmark additional LLMs and expand IberBench with new datasets as evaluation campaigns continue to emerge within the NLP research community.
Understanding the Limitations and Ethical Considerations
Despite its comprehensive approach, IberBench has several limitations. Data-related constraints include dependence on available datasets with permissive licenses, predominance of classification tasks, and underrepresentation of some language varieties with large speaker populations (e.g., Argentinian Spanish, Brazilian Portuguese).
Modeling limitations stem from using a single prompt per task, which may not capture the full range of potential model performance. The zero-shot evaluation approach may also underestimate capabilities, though it better aligns with real-world usage scenarios. For text generation, metrics like ROUGE-1 capture only lexical overlap, missing important aspects of generation quality like fluency and factual accuracy.
Resource constraints currently limit evaluation to models with up to 14 billion parameters in 16-bit precision, excluding larger and closed-source LLMs.
Ethical considerations include potential biases from dataset selection, potential for reinforcing existing disparities in language technology, and the need to handle model outputs and evaluation data responsibly. IberBench addresses these concerns through diverse task inclusion, transparent reporting, and careful data handling practices.
Despite these limitations, IberBench represents an important step toward more comprehensive, diverse, and dynamic evaluation of LLMs for Iberian languages. By open-sourcing the entire pipeline, the creators hope to encourage community collaboration, reproducible research, and responsible development of language technologies that better serve the diverse linguistic landscape of the Iberian Peninsula and Ibero-America.
