Anthropic has published a great article about Contextual Retrieval that suggests the combination of vector-based search and TF-IDF.
The way to think about a data flow for the pipeline is:
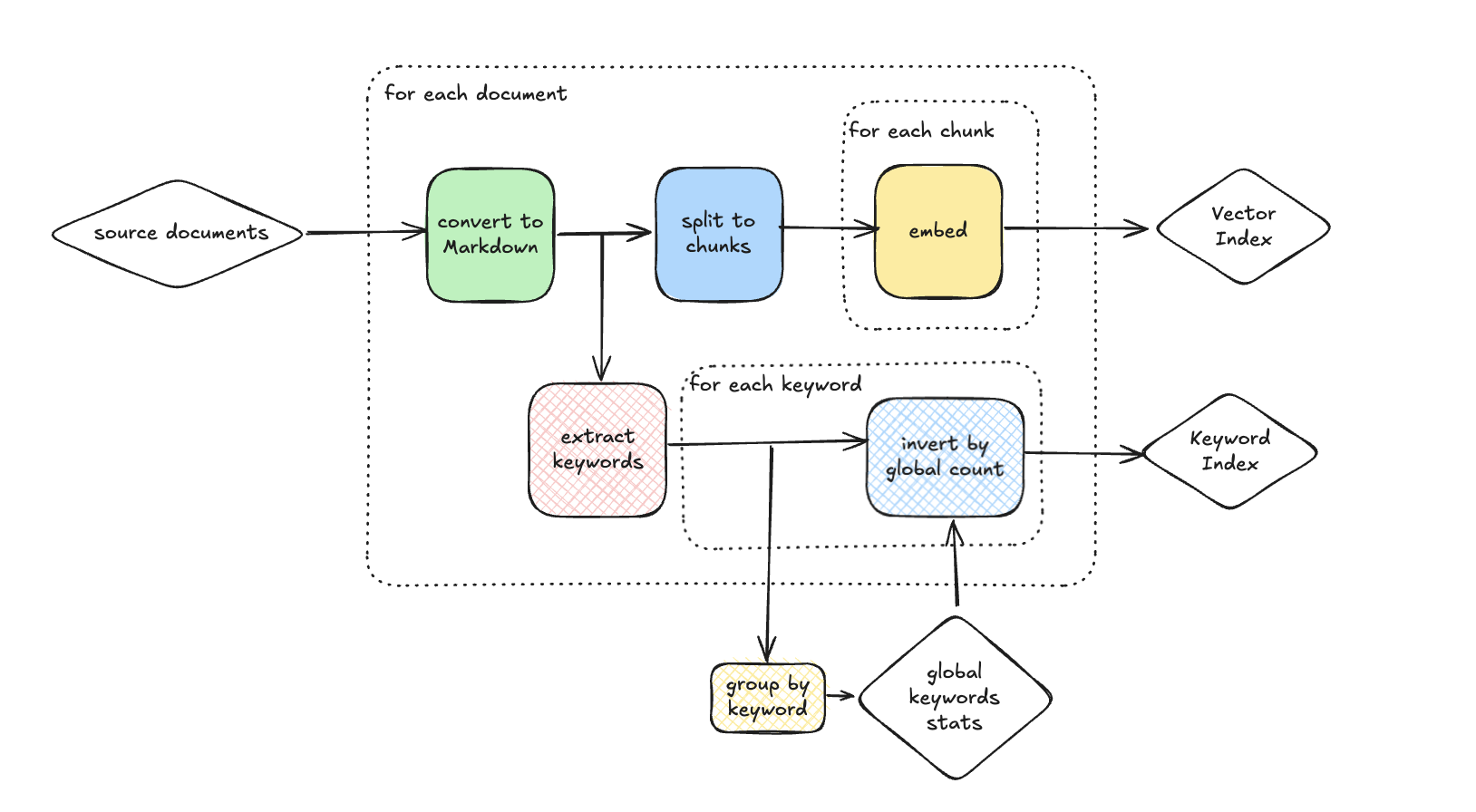
In addition to prepare the vector embedding as basic embedding example above, after the source data parsing, we can do the following:
For each document, extract keywords from it with its frequency.
Across all documents, group by keywords and sum up their frequencies, putting into an internal storage.
For each document each keyword, calculate the TF-IDF score using two inputs: frequency in the current document, and the sum of frequency across all documents. Store keyword and along with TF-IDF score keyword (if above a certain threshold) to a keyword index.
On query time, we can query both the vector index and the keyword index, and combine results from both.