
A eficiência no tratamento de dados de APIs é um fator crítico para garantir uma experiência fluida ao usuário. À medida que os conjuntos de dados crescem, operações aparentemente simples, como buscar um item específico em uma lista, podem se tornar inimigos de performance.
Nesse artigo, vou mostrar algumas formas de lidar com dados de API que podem transformar buscas lentas em acessos instantâneos. Pega um cafezinho e vamos nessa! ☕
Sumário
O problema dos arrays
A Solução: Indexação de Dados da API
Técnicas ninja de indexação
Performance na prática
Um extra: Objetos vs Maps
Conclusão

O problema dos arrays
Normalmente, uma API entrega dados assim:
const produtos = [
{ id: 1, nome: "Smartphone Ultra Mega", categoria: "eletronicos", preco: 1599.99 },
{ id: 2, nome: "Sofá Confortex", categoria: "moveis", preco: 899.50 },
{ id: 3, nome: "Smart TV 55pol", categoria: "eletronicos", preco: 2499.99 },
// ... e mais uns 500 produtos que sua aplicação precisa gerenciar
];Quando você precisa acessar esses dados, você acaba recorrendo a métodos como find() ou filter():
// Todo mundo já escreveu isso um dia
function encontrarProdutoPorId(id) {
return produtos.find(produto => produto.id === id);
}
function filtrarPorCategoria(categoria) {
return produtos.filter(produto => produto.categoria === categoria);
}O problema é que esses métodos fazem uma busca linear, o que significa que o tempo de execução aumenta linearmente com o tamanho do array. Ou seja: quanto mais produtos você tem, mais tempo demora. E isso ocorre porque esses métodos percorrem cada item da lista até encontrar o que você quer (busca de performance O(n)).
Pra gente ter uma ideia geral sobre a performance de um algoritmo, é só a gente dar uma olhada no gráfico abaixo pra saber onde cada notação big-O se encontra. Aqui, vamos focar em performances O(n) e O(1).
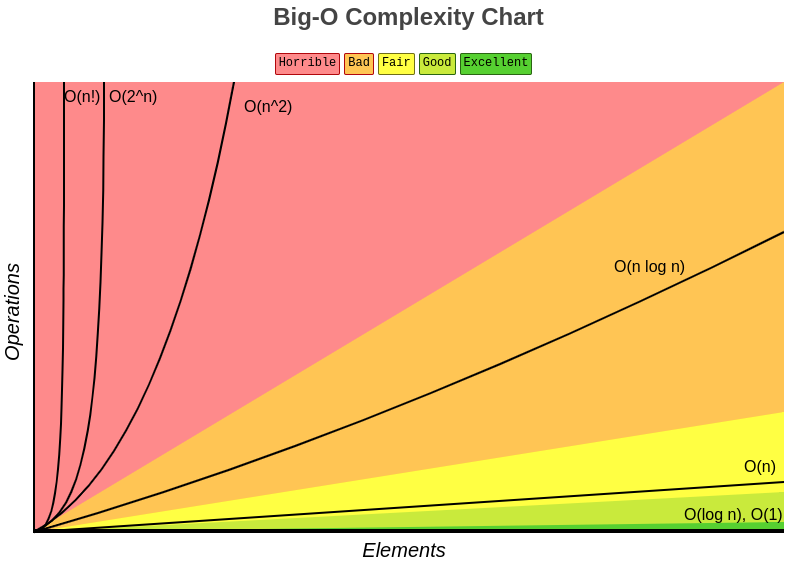
Observação: A performance que levaremos em conta nesse artigo é a de acesso aos dados indexados e não a de criação das indexações, já que, para o usuário final, o acesso aos dados é o que vai fazer a diferença.
A Solução: Indexação de Dados da API
Indexar significa criar uma estrutura de dados onde o acesso é instantâneo, como um índice de livro. No JavaScript, podemos fazer isso facilmente com objetos ou Maps.
// Transformando nosso array em um objeto indexado
// Com reduce:
const produtosPorId = produtos.reduce((acc, produto) => {
acc[produto.id] = produto;
return acc;
}, {});
// OU com Object.fromEntries:
const produtosPorId = Object.fromEntries(
produtos.map(produto => [produto.id, produto])
);
// Agora o acesso é instantâneo: performance O(1)
function encontrarProdutoPorId(id) {
return produtosPorId[id];
}
/* Exemplo de retorno de produtosPorId:
{
1: { id: 1, nome: "Smartphone Ultra Mega", categoria: "eletronicos", preco: 1599.99 },
etc...
}
*/Se você quiser, também pode usar a classe Map para mais flexibilidade, já que o Map possui vários métodos embutidos pra te auxiliar na manipulação dos dados:
const mapaProdutos = new Map(
produtos.map(produto => [produto.id, produto])
);
// Aqui também temos performance O(1)!
function encontrarProduto(id) {
return mapaProdutos.get(id);
}Todas as abordagens acima tem performance O(1), ou seja, independente da quantidade de itens que você tiver no array, a velocidade de acesso aos dados é praticamente constante!🚀
Técnicas ninja de indexação
Lookup por ID
O básico que funciona, indexando listas pelo id dos itens. É a mesma abordagem que utilizamos nos exemplos anteriores, mas segue um novo exemplo:
const usuariosPorId = usuarios.reduce((acc, usuario) => {
acc[usuario.id] = usuario;
return acc;
}, {});
// Performance O(1), é tipo teleporte de dados!
const usuario = usuariosPorId[123]; // { id: 123, nome: "Fulano", idade: 25 }
/*
Exemplo de retorno de usuariosPorId:
{
123: { id: 123, nome: "Fulano", idade: 25 },
234: { id: 234, nome: "Beltrano", idade: 48 },
...
}
*/Também podemos criar um LookUp por id indexando os itens com Map e acessando-os com .get(id):
// Gosta de one-liners?
const usuariosPorId = new Map(usuarios.map(usuario => [usuario.id, usuario]));
// Acesso O(1)
const usuario = usuariosPorId.get(123); // { id: 123, nome: "Fulano", idade: 25 }Indexação Multi-Valor
Quando precisamos agrupar itens por uma propriedade que pode ter valores repetidos (como a categoria de produtos):
const produtosPorCategoria = produtos.reduce((acc, produto) => {
// Se a categoria não existe ainda, cria um array vazio
if (!acc[produto.categoria]) {
acc[produto.categoria] = [];
}
// Joga o produto lá dentro
acc[produto.categoria].push(produto);
return acc;
}, {});
// Busca instantânea por categoria, performance O(1)
const eletronicos = produtosPorCategoria["eletronicos"];
// Exemplo de retorno de produtosPorCategoria
// {
// eletronicos: [ /* Lista de eletronicos */ ],
// moveis: [ /* Lista de moveis */ ]
// }Vamos ver como fazer essa indexação combinando .reduce() e Map e acessando com Map.get(id):
const produtosPorCategoria = produtos.reduce((acc, produto) => {
// .has() e .set() são métodos nativos de Maps...
if (!acc.has(produto.categoria)) {
acc.set(produto.categoria, []);
}
// ...assim como .get()
acc.get(produto.categoria).push(produto);
return acc;
}, new Map());
// Acesso O(1) para a categoria "moveis"
produtosPorCategoria.get("moveis"); // [{ id: 2, nome: "Sofá Confortex", categoria: "moveis", preco: 899.50 }]Índices compostos
Quando você precisa de buscas mais complexas, como uma busca por combinações de campos, por exemplo:
const produtosPorCategoriaEPreco = produtos.reduce((acc, produto) => {
// Cria uma chave composta, tipo "eletronicos_premium"
const chave = `${produto.categoria}_${produto.preco >= 1000 ? "premium" : "basico"}`;
if (!acc[chave]) {
acc[chave] = [];
}
acc[chave].push(produto);
return acc;
}, {});
// Busca O(1): Quer todos os eletrônicos caros? Toma!
const eletronicosCaros = produtosPorCategoriaEPreco["eletronicos_premium"];
/* retorno
[
{ id: 1, nome: "Smartphone Ultra Mega", categoria: "eletronicos", preco: 1599.99 },
{ id: 3, nome: "Smart TV 55pol", categoria: "eletronicos", preco: 2499.99 }
]
*/Usar um Map para um índice composto (como categoria_preço) funciona de maneira similar, mas aproveita as vantagens do Map, como melhor performance em grandes volumes de dados e suporte a qualquer tipo de chave:
const produtosPorCategoriaEPreco = produtos.reduce((acc, produto) => {
const chave = `${produto.categoria}_${produto.preco >= 1000 ? "premium" : "basico"}`;
// Aqui usamos os métodos de Map:
if (!acc.has(chave)) {
acc.set(chave, []);
}
acc.get(chave).push(produto);
return acc;
}, new Map());
// Buscar eletrônicos premium: O(1)
produtosPorCategoriaEPreco.get("moveis_basico"); // [{ id: 2, nome: "Sofá Confortex", categoria: "moveis", preco: 899.50 }]Performance na prática
Vamos ver o que acontece quando temos 10.000 produtos. Para isso, vamos criar nosso setup pro teste (nossa lista gigante de produtos que viria de uma API):
const listaGiganteDeProdutos = Array.from({ length: 10000 }, (_, i) => ({
id: i + 1,
nome: `Produto ${i + 1}`,
categoria: i % 5 === 0 ? "eletrônicos" : "outros",
preco: Math.random() * 2000
}));Agora, faremos a indexação da lista acima:
const produtosIndexados = listaGiganteDeProdutos.reduce((acc, p) => {
acc[p.id] = p;
return acc;
}, {});E agora, o embate: Acesso Não Indexado VS Acesso Indexado! Vamos usar console.time() e console.timeEnd() antes e depois dos nossos acessos para registrar o tempo decorrido em cada um:
// Acesso não indexado: O(n)
console.time("Sem indexação (modo tartaruga 🐢)");
for (let i = 0; i < 1000; i++) {
const id = Math.floor(Math.random() * 10000) + 1;
listaGiganteDeProdutos.find(p => p.id === id);
}
console.timeEnd("Sem indexação (modo tartaruga 🐢)");
// Busca indexada: O(1)
console.time("Com indexação (modo foguete 🚀)");
for (let i = 0; i < 1000; i++) {
const id = Math.floor(Math.random() * 10000) + 1;
produtosIndexados[id];
}
console.timeEnd("Com indexação (modo foguete 🚀)");Spoiler: a versão indexada normalmente é centenas de vezes mais rápida em conjuntos grandes, com diferenças cada vez mais pronunciadas conforme o tamanho do conjunto de dados aumenta. Saca só:
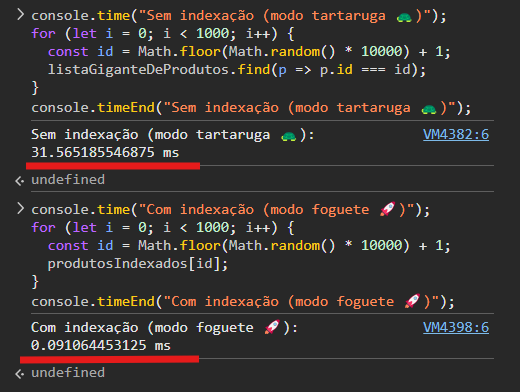
O preço da velocidade
Claro, nada é de graça nessa vida. A indexação tem seu custo em memória adicional, pois você está praticamente duplicando as referências dos dados. Em aplicações com restrições severas de memória, este trade-off deve ser considerado cuidadosamente:
- Uma estrutura indexada simples (por ID) aproximadamente dobra o uso de memória;
- Índices multi-valor multiplicam esse custo;
- Índices parciais (apenas com campos necessários em vez do objeto completo) podem reduzir esse impacto;
A indexação aumenta o consumo de memória, mas geralmente o ganho de performance compensa, especialmente em aplicações web e mobile.
A chave é encontrar o equilíbrio entre performance, legibilidade do código e uso de memória. Nem sempre a solução mais complexa é a melhor.
Quando não indexar
Nem sempre a indexação é necessária:
- Conjuntos de dados muito pequenos (<100 itens): em conjuntos pequenos, a diferença entre a busca indexada e a busca padrão reflete pouco ganho de performance;
- Buscas realizadas com raridade: não compensa o gasto com memória;
- Protótipos e projetos iniciais: foque no básico que funciona.
Um extra: Objetos vs Maps
Se você tá lidando com algumas centenas de itens: relaxa, qualquer um dos dois vai voar. Mas se você tá com milhares ou milhões: aí sim começa a fazer diferença. Maps geralmente levam vantagem em operações frequentes de adição/remoção e quando você precisa iterar sobre tudo.
Objeto: O clássico que não sai de moda
😁 Vantagens:
- Todo mundo sabe usar;
- Tem integração nativa com
JSON(podem ser facilmente convertidos); - Acesso facilitado com
obj[key]; - Performance sólida que não deixa na mão.
😬 Desvantagens:
- Só aceita strings e Symbols como chave;
- Não tem métodos nativos pra manipulação, apenas funções auxiliares;
- Pode ser complicado conseguir o tamanho sem usar
Object.keys();
🤔 Quando usar:
- Quando precisar de integração direta com
JSON; - Pra estruturas de dados mais simples;
- Se as chaves forem sempre strings;
- Quando performance de leitura for a prioridade.
Map: O primo moderninho
😁 Vantagens:
- Aceita qualquer coisa como chave (até objetos, imagina!);
- Mantém a ordem que você inseriu (tem TOC? Esse é pra você);
- Vem com métodos úteis de fábrica, como
.set(),.get(),.has(), etc; - Performance melhor pra manipulações e iterações frequentes.
😬 Desvantagens:
- Boa parte da galera ainda não conhece muito bem;
- Se precisar usar
JSON, precisa de conversão manual; - Tem suporte limitado pra browsers mais antigos (mas quem ainda usa IE?).
🤔 Quando usar:
- Pra estruturas de dados mais complexas;
- Quando precisar de outros tipos de chave além de strings;
- Quando a ordem de inserção for importante (meu TOC agradece);
- Quando performance de manipulação e iteração for prioridade.
Conclusão

Transformar arrays em estruturas indexadas pode parecer um trabalho extra no começo, mas o ganho de performance é tão absurdo que você vai se perguntar como viveu tanto tempo sem fazer isso.
A diferença entre um app que trava e um que flui como manteiga no pão quente muitas vezes está na forma como organizamos os dados. Com as técnicas deste artigo, você pode reduzir tempos de busca de centenas de milissegundos para apenas alguns milissegundos, melhorando significativamente a experiência do usuário.
Lembre-se: em desenvolvimento, preguiça estratégica (fazer o trabalho pesado uma vez só, na indexação inicial) quase sempre compensa. Seu app fica mais rápido, seus usuários mais felizes, e você com mais tempo para tomar aquele café enquanto admira seu código otimizado. 😎
Dica Final: Sempre meça a performance antes e depois das otimizações. Ferramentas de profiling do navegador são suas melhores amigas nessa jornada. Um xero!