This is a Plain English Papers summary of a research paper called InternVL3: Unified Multimodal AI Training Outperforms Open-Source Rivals. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Breaking New Ground in Multimodal AI Training
InternVL3 marks a significant advancement in the InternVL model series, implementing a native multimodal pre-training approach that fundamentally transforms how vision-language models learn. Unlike most leading multimodal large language models (MLLMs) that adapt text-only models to handle visual inputs through complex post-hoc alignment, InternVL3 jointly acquires multimodal and linguistic capabilities in a single unified pre-training stage.
This innovative approach addresses the alignment challenges typically encountered when retrofitting text-only LLMs with visual processing capabilities. Traditional methods require resource-intensive strategies with specialized domain data and intricate parameter-freezing schedules, whereas InternVL3's unified training paradigm offers a more efficient and integrated approach to multimodal learning.
Native Multimodal Pre-Training: A Unified Approach
The core innovation of InternVL3 lies in its native multimodal pre-training strategy. Rather than first training a text-only LLM and then adapting it for visual inputs, InternVL3 learns from both text corpora and multimodal datasets simultaneously during pre-training. This approach enables the model to develop linguistic and visual capabilities in tandem, creating a more seamlessly integrated multimodal architecture.
The pre-training process uses a multimodal autoregressive formulation where visual tokens serve as conditioning context for text prediction. While gradients naturally propagate through all modalities, the loss computation focuses exclusively on text tokens. This training approach helps the model embed visual information in ways that benefit downstream language tasks.
InternVL3 also incorporates advanced position encoding strategies like Variable Visual Position Encoding (V2PE), which assigns different position increments to textual and visual tokens. This innovation helps accommodate longer multimodal contexts without excessively extending the position window.
Architecture and Model Variants
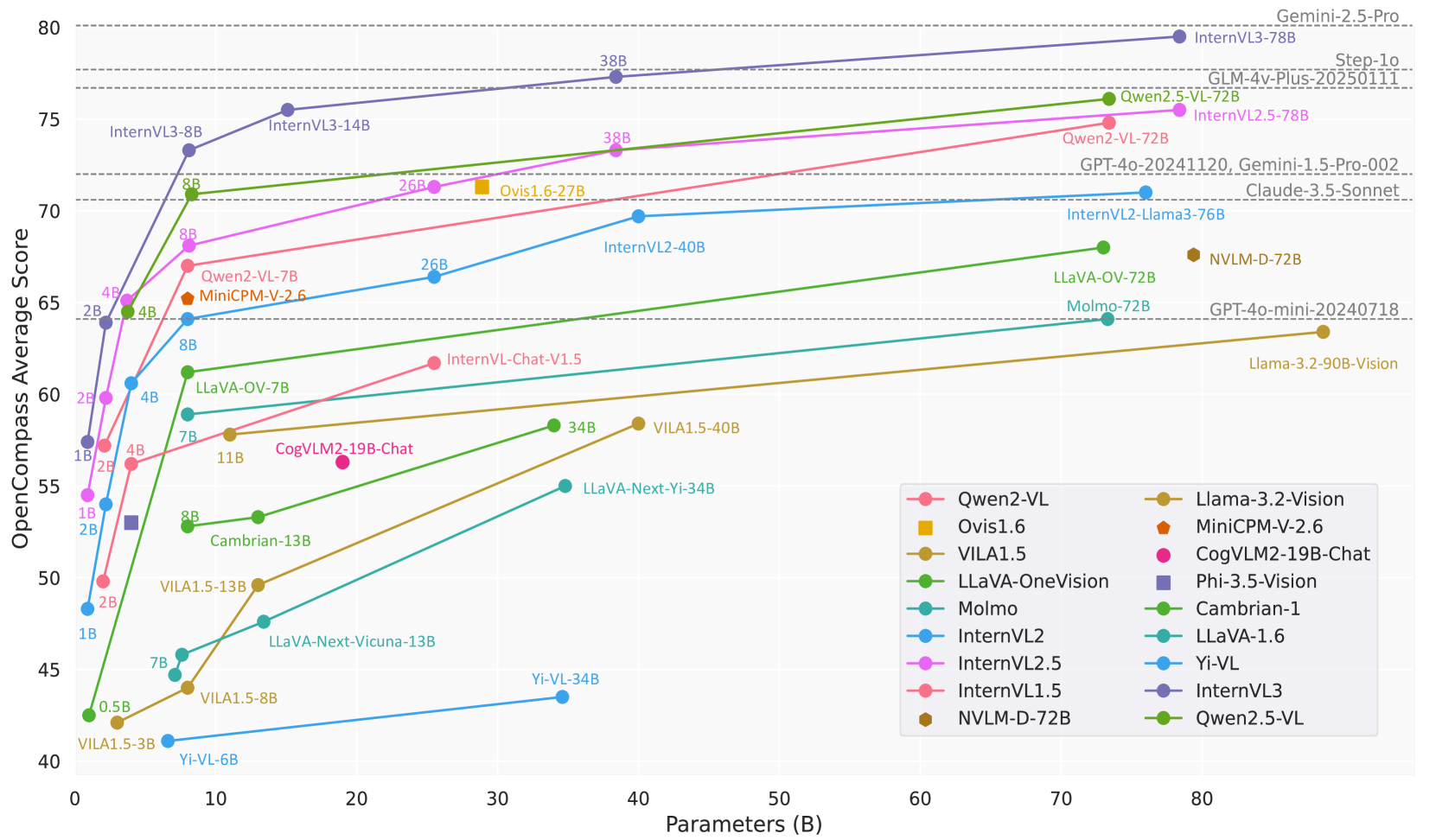
InternVL3 follows the "ViT-MLP-LLM" architecture paradigm used in previous models but introduces several refinements. The model consists of a vision encoder (InternViT), a two-layer MLP for alignment, and a language model (primarily from the Qwen2.5 series).
| Model Name | #Param | Vision Encoder | Language Model | OpenCompass Academic |
|---|---|---|---|---|
| InternVL3-1B | 0.9B | InternViT-300M-448px-V2.5 | Qwen2.5-0.5B | 57.4 |
| InternVL3-2B | 1.9B | InternViT-300M-448px-V2.5 | Qwen2.5-1.5B | 63.9 |
| InternVL3-8B | 8.1B | InternViT-300M-448px-V2.5 | Qwen2.5-7B | 73.3 |
| InternVL3-9B | 9.2B | InternViT-300M-448px-V2.5 | InternLM3-8B | 72.4 |
| InternVL3-14B | 15.1B | InternViT-300M-448px-V2.5 | Qwen2.5-14B | 75.5 |
| InternVL3-38B | 38.4B | InternViT-6B-448px-V2.5 | Qwen2.5-32B | 77.3 |
| InternVL3-78B | 78.4B | InternViT-6B-448px-V2.5 | Qwen2.5-72B | 79.5 |
Pre-trained models used in the InternVL3 series. The OpenCompass scores for the InternVL3 series were obtained through local testing.
The LLM components are initialized solely from pre-trained base models without employing instruction-tuned variants. For efficiency in processing high-resolution images, InternVL3 incorporates a pixel unshuffle operation, which reduces visual token count to one-fourth of the original value.
Advanced Training and Optimization Strategies
InternVL3 employs a comprehensive three-phase training approach:
Native Multimodal Pre-training: The model learns from interleaved multimodal data and text corpora during initial pre-training.
Supervised Fine-Tuning (SFT): Building on pre-training, SFT uses higher-quality and more diverse training data across domains like tool usage, 3D scene understanding, GUI operations, long context tasks, video understanding, scientific diagrams, creative writing, and multimodal reasoning.
Mixed Preference Optimization (MPO): This phase addresses the gap between training (ground-truth token conditioning) and inference (model-predicted token conditioning) by introducing supervision from both positive and negative samples.
For inference, InternVL3 leverages test-time scaling with Best-of-N evaluation using VisualPRM-8B as a critic model to select the most effective responses for reasoning and mathematical tasks.
To enhance training efficiency, the team extended the InternEVO framework to support flexible sharding strategies for different model components, resulting in a 50-200% training speedup compared to previous models.
Comprehensive Performance Evaluation
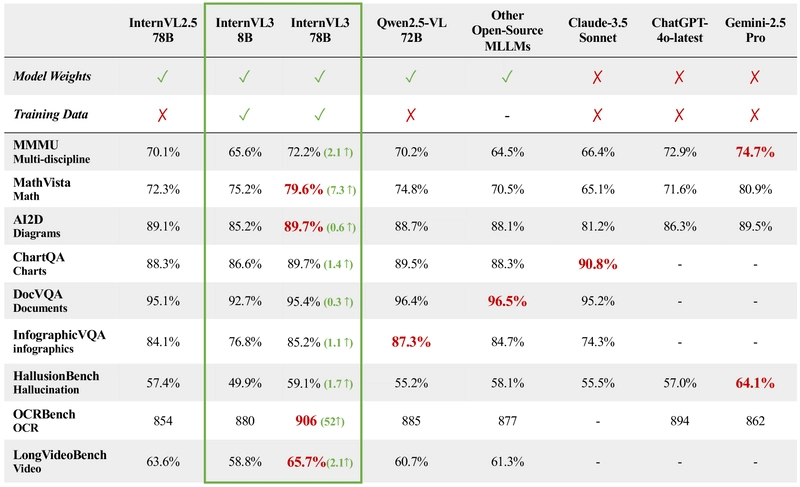
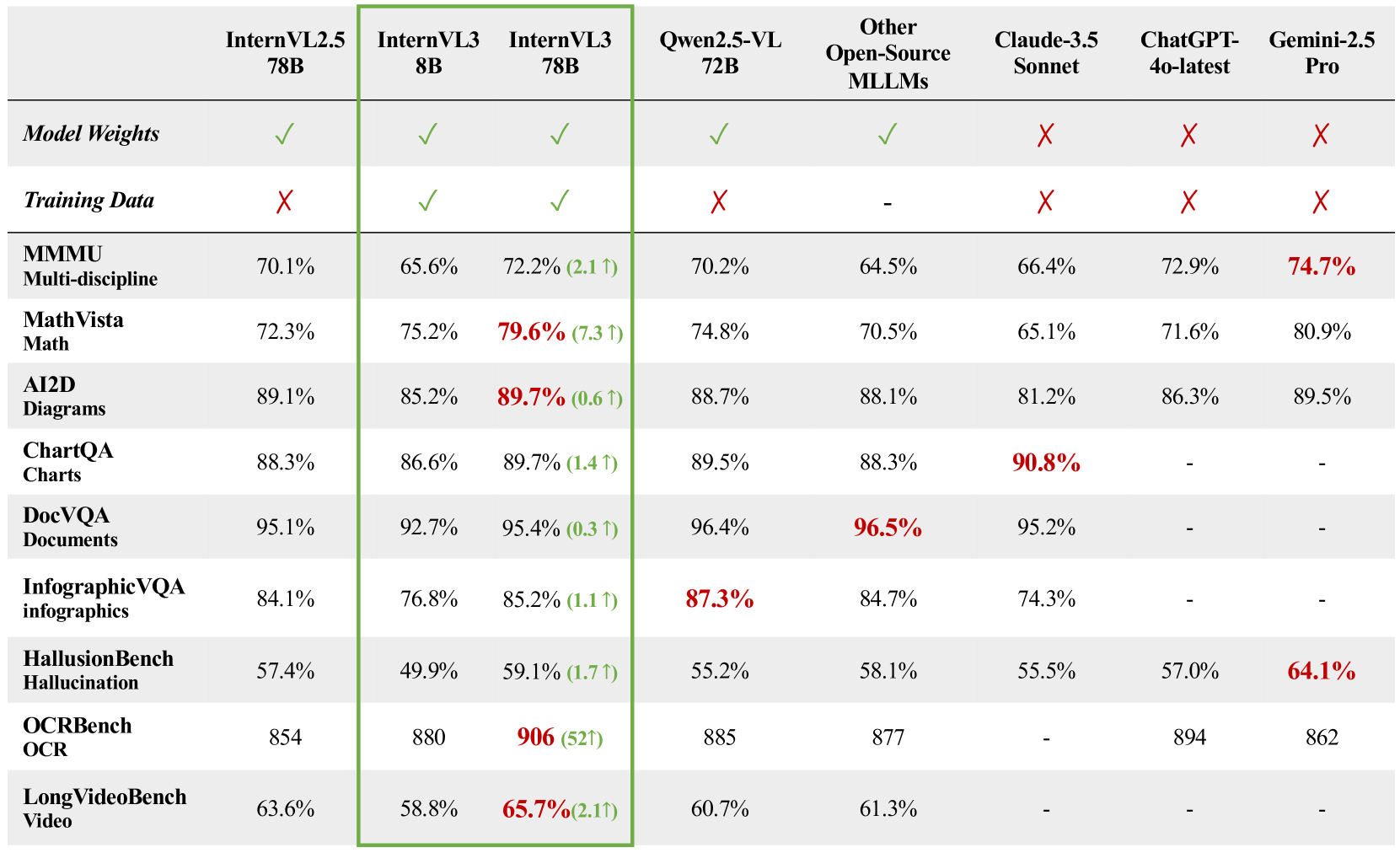
InternVL3 demonstrates exceptional performance across diverse multimodal tasks. On the multidisciplinary reasoning benchmark MMMU, InternVL3-78B achieves a score of 72.2%, setting a new state-of-the-art among open-source MLLMs.
For mathematical reasoning, InternVL3 shows strong results across various benchmarks, with InternVL3-78B recording 79.0% on MathVista, 43.1% on MathVision, and 51.0% on MathVerse.
| Model | MMMU | MathVista | MathVision | MathVerse | DynaMath | WeMath | LogicVista | Overall |
|---|---|---|---|---|---|---|---|---|
| InternVL3-1B | 43.4 | 45.8 | 18.8 | 18.7 | 5.8 | 13.4 | 29.8 | 25.1 |
| w/ VisualPRM-Bo8 [124] | 55.4 | 62.1 | 21.7 | 28.9 | 13.4 | 28.5 | 34.9 | 35.0 |
| InternVL3-2B | 48.6 | 57.0 | 21.7 | 25.3 | 14.6 | 22.4 | 36.9 | 32.4 |
| w/ VisualPRM-Bo8 [124] | 57.8 | 70.5 | 26.6 | 36.7 | 21.4 | 38.5 | 40.5 | 41.7 |
| InternVL3-8B | 62.7 | 71.6 | 29.3 | 39.8 | 25.5 | 37.1 | 44.1 | 44.3 |
| w/ VisualPRM-Bo8 [124] | 66.0 | 75.2 | 37.5 | 46.3 | 28.5 | 48.1 | 49.7 | 50.2 |
| InternVL3-78B | 72.2 | 79.0 | 43.1 | 51.0 | 35.1 | 46.1 | 55.9 | 54.6 |
| w/ VisualPRM-Bo8 [124] | 72.2 | 80.5 | 40.8 | 54.2 | 37.3 | 52.4 | 57.9 | 56.5 |
| GPT-4o-20241120 [96] | 70.7 | 60.0 | 31.2 | 40.6 | 34.5 | 45.8 | 52.8 | 47.9 |
| Claude-3.7-Sonnet [3] | 75.0 | 66.8 | 41.9 | 46.7 | 39.7 | 49.3 | 58.2 | 53.9 |
| Gemini-2.0-Pro [29] | 69.9 | 71.3 | 48.1 | 67.3 | 43.3 | 56.5 | 53.2 | 58.5 |
Comparison of multimodal reasoning and mathematical performance. The overall score is the average score of the benchmarks. "w/ VisualPRM-Bo8" denotes that the model is evaluated with Best-of-8 settings, where VisualPRM serves as the critic model.
In OCR, chart, and document understanding tasks, InternVL3 achieves top-tier results, with InternVL3-78B reaching 89.7/96.0% on AI2D, 89.7% on ChartQA, and 95.4% on DocVQA.
| Model Name | AI2D (w / wo M) |
ChartQA (test avg) |
TextVQA (val) |
DocVQA (test) |
InfoVQA (test) |
OCR Bench |
SEED-2 Plus |
CharXiv (RQ / DQ) |
VCR-EN-Easy (EM J Jaccard) |
Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| InternVL3-1B | 69.4 / 78.3 | 75.3 | 74.1 | 81.9 | 53.7 | 790 | 58.2 | 21.0 / 47.1 | 89.3 / 96.2 | 68.6 |
| InternVL3-2B | 78.7 / 87.4 | 80.2 | 77.0 | 88.3 | 66.1 | 835 | 64.6 | 28.3 / 54.7 | 91.2 / 96.9 | 74.7 |
| InternVL3-8B | 85.2 / 92.6 | 86.6 | 80.2 | 92.7 | 76.8 | 880 | 69.7 | 37.6 / 73.6 | 94.5 / 98.1 | 81.3 |
| InternVL3-38B | 88.9 / 95.5 | 89.2 | 83.9 | 95.4 | 85.0 | 886 | 71.6 | 46.4 / 87.2 | 96.1 / 98.7 | 85.5 |
| InternVL3-78B | 89.7 / 96.0 | 89.7 | 84.3 | 95.4 | 86.5 | 906 | 71.9 | 46.0 / 85.1 | 96.0 / 98.6 | 85.8 |
| GPT-4o-20240513 [96] | 84.6 / 94.2 | 85.7 | 77.4 | 92.8 | 79.2 | 736 | 72.0 | 47.1 / 84.5 | 91.6 / 96.4 | 81.6 |
| Claude-3.5-Sonnet [3] | 81.2 / 94.7 | 90.8 | 74.1 | 95.2 | 74.3 | 788 | 71.7 | 60.2 / 84.3 | 63.9 / 74.7 | 78.7 |
Comparison of OCR, chart, and document understanding performance. The table evaluates OCR-related capabilities across 9 benchmarks, including AI2D, ChartQA, TextVQA, DocVQA, InfoVQA, OCRBench, SEED-2-Plus, CharXiv, and VCR.
For multi-image understanding, InternVL3-78B demonstrates strong cross-image reasoning capabilities with scores of 66.3% on BLINK, 79.3% on Mantis-Eval, and 73.2% on MMT-Bench.
The model also excels in video understanding, with InternVL3-78B achieving 72.7/75.7% on Video-MME and 78.7% on MVBench, outperforming many other open-source and closed-source models.
Preserving Strong Language Capabilities
A key achievement of InternVL3 is maintaining robust language capabilities despite its joint multimodal training approach. In fact, InternVL3 models consistently outperform their Qwen2.5 chat counterparts across most language evaluation benchmarks, including MMLU, CMMLU, C-Eval, and GAOKAO.
This enhancement in language capabilities stems from several factors: the integration of approximately 25% pure-language data during multimodal pre-training, joint parameter optimization, and extensive use of high-quality textual corpora during post-training.
Ablation Studies and Analysis
Ablation studies reveal the effectiveness of InternVL3's key components:
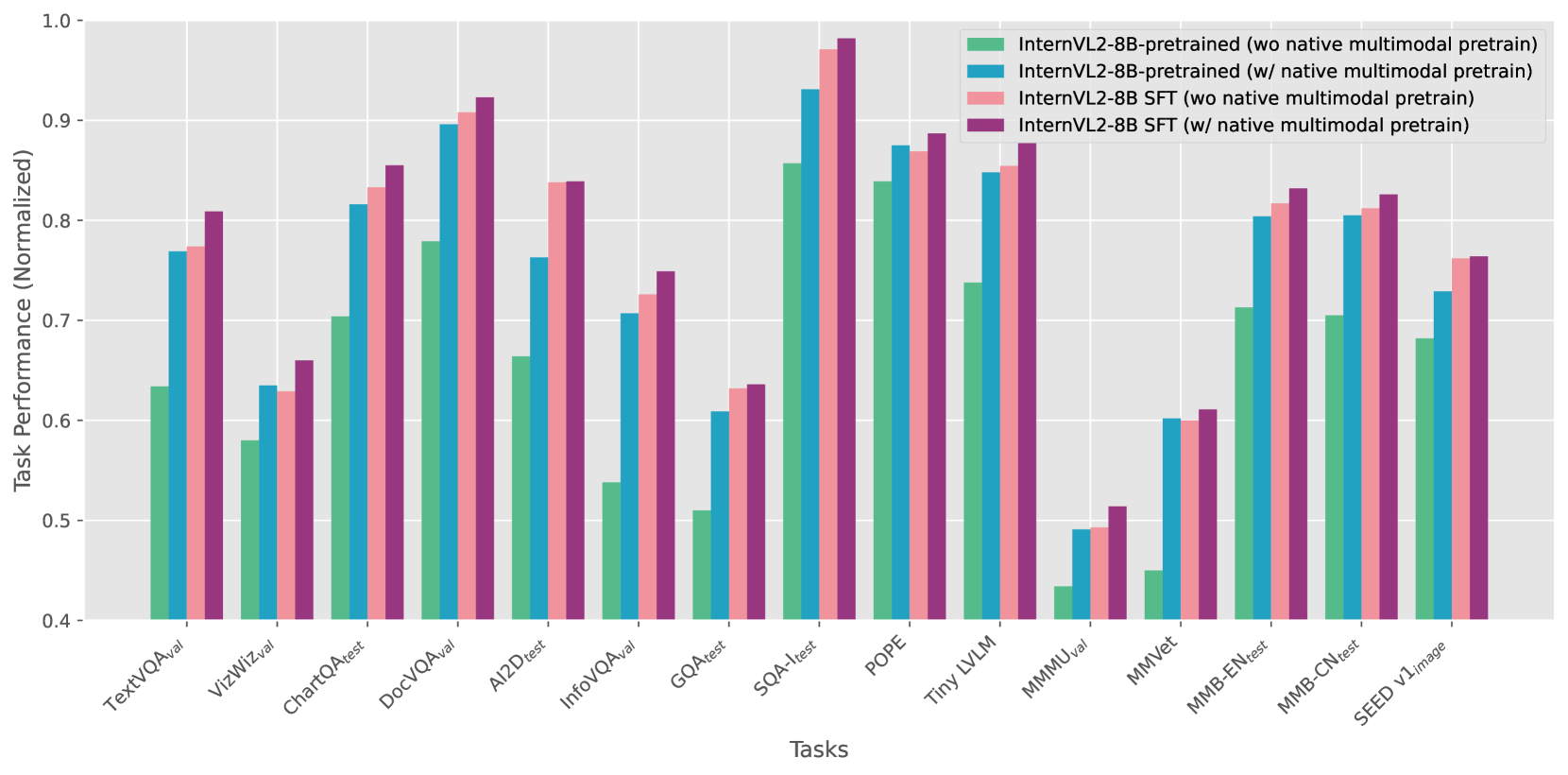
Native Multimodal Pre-training: Models using native multimodal pre-training showed performance comparable to fully multi-stage trained baselines, even without further optimization.
Variable Visual Position Encoding: Different position increment values (δ) were tested, showing that even for tasks with short contexts, relatively small δ values can achieve optimal performance.
Mixed Preference Optimization: Models fine-tuned with MPO demonstrated superior reasoning performance compared to counterparts without MPO, with improvements of 4.1 and 4.5 points for the 78B and 38B variants, respectively.
A Step Forward for Open-Source MLLMs
InternVL3 represents a significant advancement in the development of open-source multimodal models. By implementing a native multimodal pre-training approach, incorporating innovations like V2PE, and applying effective post-training techniques, InternVL3 achieves state-of-the-art performance among open-source MLLMs while narrowing the gap with leading proprietary models.
In line with open science principles, the researchers are releasing both the training data and model weights to foster further research and development in next-generation MLLMs. This commitment to transparency and accessibility helps advance the entire field of multimodal AI.
The success of InternVL3 demonstrates the effectiveness of unified training paradigms that jointly optimize for multiple modalities, potentially setting a new direction for the development of future multimodal AI systems.
