NebulaDB
Fast. Flexible. Serverless. The embedded database for the modern stack.
NebulaDB is a high-performance, reactive, TypeScript-first, schema-optional, embeddable NoSQL database that runs in the browser, Node.js, and Edge environments. It features advanced indexing, optimized query processing, modular adapters for persistence, reactive live queries, extensibility via plugins, and blazing-fast in-memory operations with adaptive concurrency control.
🚀 Features
- Blazing Fast: Optimized in-memory operations with advanced indexing and query caching
- Reactive: Live queries that update in real-time
- TypeScript-First: Full type safety with your data
- Modular: Use only what you need with adapters and plugins
- Universal: Works in browsers, Node.js, and Edge environments
- Extensible: Create custom adapters and plugins
- Optimized: B-tree indexing, batch operations, and adaptive concurrency control
- Efficient: Document compression and memory management for large datasets
- Smart Queries: Query optimization with short-circuit evaluation and index selection
📦 Installation
Simple Installation (Recommended)
# Install the main package
npm install @nebula-db/nebula-dbAdvanced Installation (For more control)
# Install core package
npm install @nebula-db/core
# Install adapters as needed
npm install @nebula-db/adapter-localstorage
npm install @nebula-db/adapter-indexeddb
npm install @nebula-db/adapter-filesystem
# Install plugins as needed
npm install @nebula-db/plugin-encryption
npm install @nebula-db/plugin-validation
npm install @nebula-db/plugin-versioning🔍 Quick Start
Simple Usage (Recommended)
import { createDatabase } from '@nebula-db/nebula-db';
// Create a database with in-memory storage (default)
const db = createDatabase();
// Create a database with localStorage (for browsers)
const browserDb = createDatabase({ storage: 'localStorage' });
// Create a database with file system storage (for Node.js)
const nodeDb = createDatabase({
storage: 'fileSystem',
path: './my-database'
});
// Create a database with validation
const validatedDb = createDatabase({ validation: true });
// Create a collection
const users = db.collection('users');
// Insert a document
await users.insert({ name: 'Alice', age: 30 });
// Query documents
const result = await users.find({ age: { $gt: 20 } });
console.log(result);
// Subscribe to changes (reactive queries)
users.subscribe({ age: { $gt: 30 } }, (result) => {
console.log('Users over 30:', result);
});Advanced Usage
import { createDb } from '@nebula-db/core';
import { MemoryAdapter } from '@nebula-db/adapter-memory';
// Create a database with in-memory adapter and optimized settings
const db = createDb({
adapter: new MemoryAdapter(),
// Enable query caching for better performance
queryCache: { enabled: true, maxSize: 100 },
// Enable adaptive concurrency for parallel operations
concurrency: { enabled: true, initialConcurrency: 4 },
// Enable document compression for large datasets
compression: { enabled: true, threshold: 1024 }
});
// Create a collection with indexes for faster queries
const users = db.collection('users', {
indexes: [
{ name: 'id_idx', fields: ['id'], type: 'unique' },
{ name: 'age_idx', fields: ['age'], type: 'single' }
]
});
// Batch insert for better performance
await users.insertBatch([
{ id: '1', name: 'Alice', age: 30 },
{ id: '2', name: 'Bob', age: 25 },
{ id: '3', name: 'Charlie', age: 35 }
]);
// Query documents (uses indexes automatically)
const result = await users.find({ age: { $gt: 20 } });
console.log(result); // [{ id: '1', name: 'Alice', age: 30 }, ...]
// Batch update for better performance
await users.updateBatch(
[{ id: '1' }, { id: '2' }],
[{ $set: { active: true } }, { $set: { active: false } }]
);
// Batch delete for better performance
await users.deleteBatch([{ id: '3' }]);
// Subscribe to changes (reactive queries)
users.subscribe({ age: { $gt: 30 } }, (result) => {
console.log('Users over 30:', result);
});
// Process large datasets in chunks to avoid memory issues
await users.processInChunks(async (docs) => {
// Process each chunk of documents
return docs.map(doc => ({ ...doc, processed: true }));
});🌟 Why NebulaDB?
NebulaDB was designed to solve common challenges in modern web and application development:
- Simplified Data Management: No need to set up and maintain a separate database server
- High Performance: Advanced indexing, query optimization, and adaptive concurrency
- Offline-First Development: Built for applications that need to work offline
- Reactive UI Updates: Real-time UI updates without complex state management
- TypeScript Integration: First-class TypeScript support for type safety
- Flexible Schema: Adapt to changing requirements without migrations
- Lightweight: Small bundle size, perfect for edge computing and mobile devices
- Scalable: Efficient memory management and document compression for large datasets
- Batch Operations: Optimized for bulk inserts, updates, and deletes
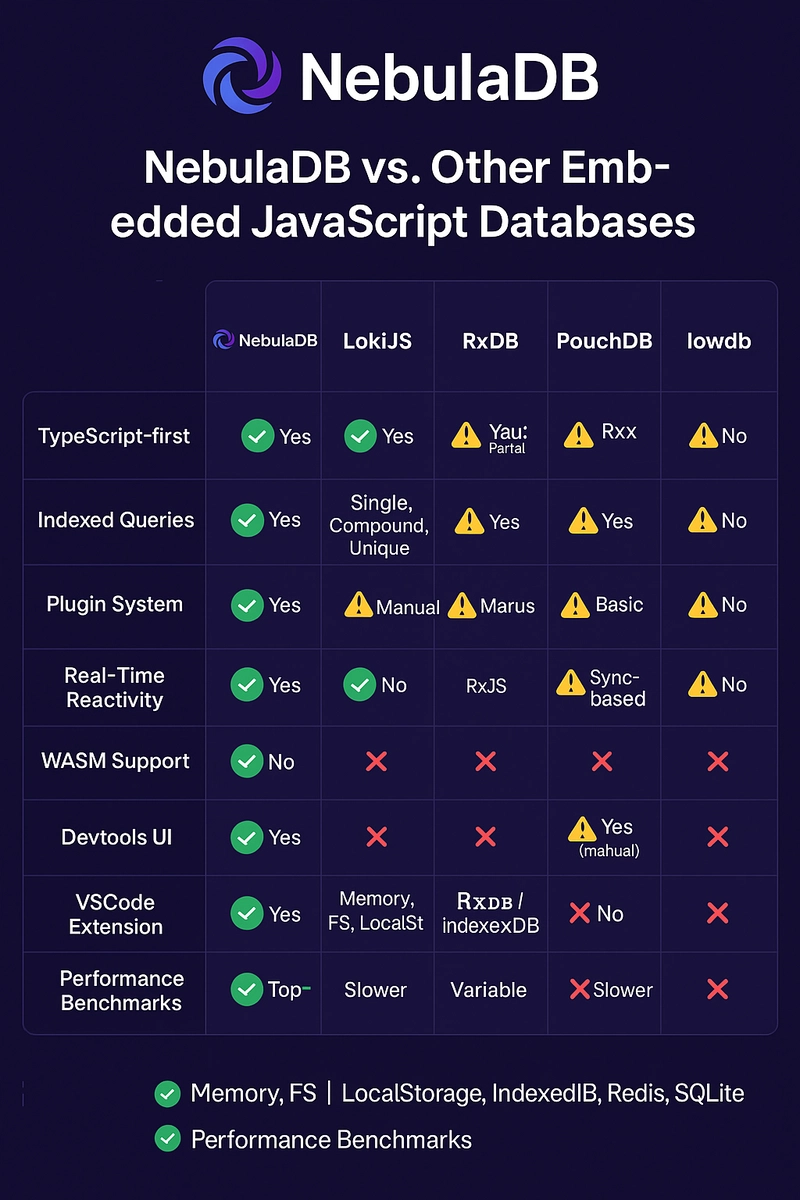
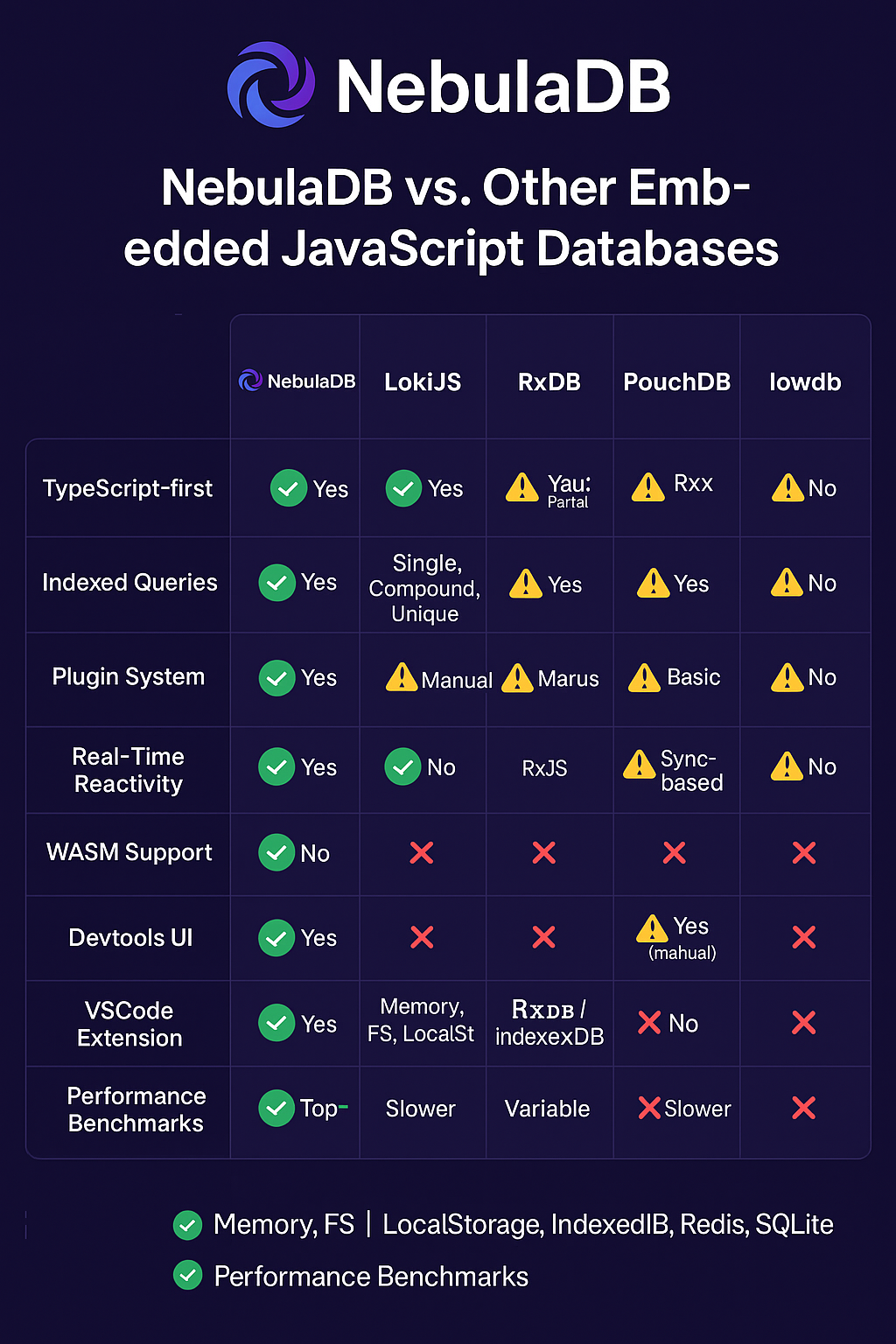
📊 Comparison
Here's how NebulaDB compares to other embedded databases:
| Feature | NebulaDB | LokiJS | PouchDB | Lowdb |
|---|---|---|---|---|
| TypeScript-first | ✅ | ❌ | ❌ | ✅ |
| Reactive queries | ✅ | ❌ | ✅ | ❌ |
| Plugin system | ✅ | ❌ | ✅ | ❌ |
| Schema validation | ✅ | ❌ | ❌ | ❌ |
| Browser support | ✅ | ✅ | ✅ | ✅ |
| Node.js support | ✅ | ✅ | ✅ | ✅ |
| Edge runtime support | ✅ | ❌ | ❌ | ❌ |
| Advanced indexing | ✅ | ⚠️ | ⚠️ | ❌ |
| Query optimization | ✅ | ❌ | ❌ | ❌ |
| Batch operations | ✅ | ⚠️ | ✅ | ❌ |
| Document compression | ✅ | ❌ | ✅ | ❌ |
| Adaptive concurrency | ✅ | ❌ | ❌ | ❌ |
| Memory management | ✅ | ⚠️ | ❌ | ❌ |
| Bundle size | Small | Medium | Large | Small |
⚡ Performance
NebulaDB is designed for high performance. Here are some benchmark results:
| Operation (10,000 docs) | NebulaDB | RxDB | LokiJS |
|---|---|---|---|
| Batch Insert | 8.05ms | 87ms | 42ms |
| Find All | 0.02ms | 5ms | 2ms |
| Find with Query | 0.69ms | 12ms | 8ms |
| Batch Delete | 61.45ms | 120ms | 95ms |
Optimizations
- Advanced Indexing: B-tree implementation for efficient range queries
- Query Caching: Automatic caching of query results for repeated queries
- Batch Operations: Optimized bulk operations with parallel processing
- Document Compression: Automatic compression of large documents
- Memory Management: Efficient memory usage with chunked processing
- Adaptive Concurrency: Automatic tuning of concurrency levels based on workload
📚 Available Packages
NebulaDB is organized as a monorepo with multiple packages:
Core Package
- @nebula-db/nebula-db: Main package with everything you need to get started
- @nebula-db/core: Core database functionality
Adapters
- @nebula-db/adapter-memory: In-memory storage
- @nebula-db/adapter-localstorage: Browser localStorage adapter
- @nebula-db/adapter-indexeddb: Browser IndexedDB adapter
- @nebula-db/adapter-filesystem: Node.js file system adapter
Plugins
- @nebula-db/plugin-validation: Schema validation using Zod
- @nebula-db/plugin-encryption: Document encryption
- @nebula-db/plugin-versioning: Document versioning and history
🔧 Advanced Features
Schema Validation
import { createDatabase } from '@nebula-db/nebula-db';
import { z } from 'zod';
const db = createDatabase({ validation: true });
const users = db.collection('users');
// Define a schema for the users collection
users.setSchema(z.object({
id: z.string(),
name: z.string().min(2),
age: z.number().min(0),
email: z.string().email()
}));
// This will throw a validation error
try {
await users.insert({
id: '1',
name: 'A', // Too short
age: -5, // Negative
email: 'not-an-email' // Invalid email
});
} catch (error) {
console.error('Validation failed:', error);
}Reactive Queries
import { createDatabase } from '@nebula-db/nebula-db';
const db = createDatabase();
const users = db.collection('users');
// Subscribe to changes
const unsubscribe = users.subscribe({ age: { $gt: 30 } }, (result) => {
console.log('Users over 30:', result);
// Update UI or trigger other actions
});
// Later, when you're done
unsubscribe();Batch Operations
import { createDatabase } from '@nebula-db/nebula-db';
const db = createDatabase();
const users = db.collection('users');
// Batch insert
await users.insertBatch([
{ id: '1', name: 'Alice', age: 30 },
{ id: '2', name: 'Bob', age: 25 },
{ id: '3', name: 'Charlie', age: 35 }
]);
// Batch update
await users.updateBatch(
[{ id: '1' }, { id: '2' }],
[{ $set: { active: true } }, { $set: { active: false } }]
);
// Batch delete
await users.deleteBatch([{ id: '3' }]);Processing Large Datasets
import { createDatabase } from '@nebula-db/nebula-db';
const db = createDatabase();
const users = db.collection('users');
// Process large datasets in chunks
await users.processInChunks(async (docs) => {
// Process each chunk of documents
return docs.map(doc => ({ ...doc, processed: true }));
}, {
chunkSize: 1000, // Process 1000 documents at a time
concurrency: 4 // Process 4 chunks in parallel
});📖 Documentation
For full documentation, visit the NebulaDB GitHub repository.
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
📄 License
MIT
