Points
- GPT models are trained on huge amounts of data. The sources of data include common crawl, Wikipedia, books, news articles, scientific journals, reddit posts etc.
- GPT models are just scaled up version of the classical transformer architecture. scaled up = shit loads of parameters (hundereds of billions) and many more layers of transformers. GPT-3 has 96 transformer layers and 175 billion parameters.
- GPT models do not have an encoder, unlike the classical Transformer architecture.
- The pre-training for these models is done in an un-supervised way, meaning, there is no output label. Or you could say the output label is already present in the input sentence.
- Example : Input: Big Brains.
- Input is broken down into "Big", "Brains"
- "Big" -> input to the model -> model tries to predict "Brains"
- Obviously the model fails, we calculate the loss and use
backpropogation to update the weights of the transformer archthiture using SGD
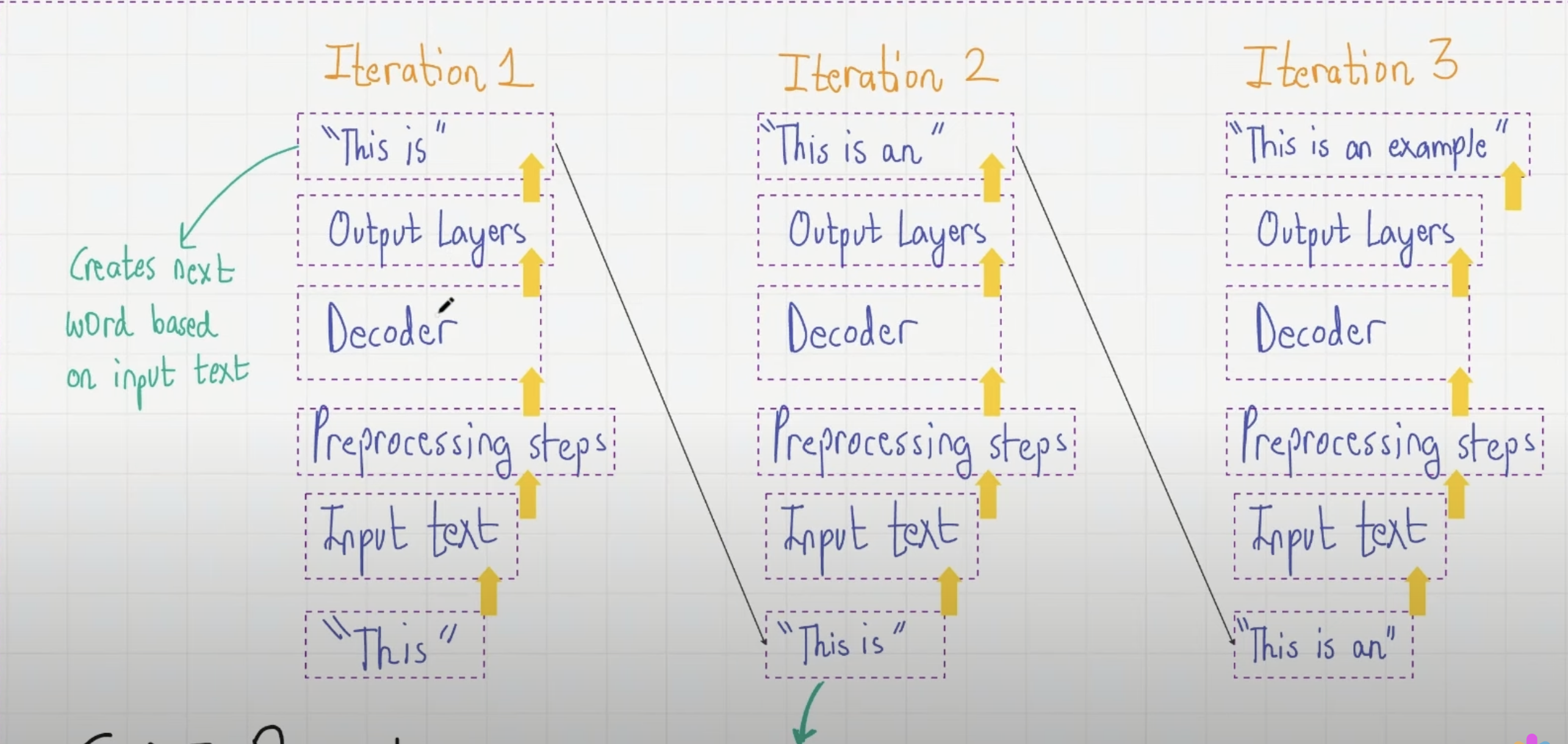
The models are auto-regressive, meaning, the output of the previous iteration is added to the input in the next iteration.