This is a Plain English Papers summary of a research paper called LeetCodeDataset: New Benchmark for Robust Code LLM Evaluation & Training. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introducing LeetCodeDataset: A New Benchmark for Code LLMs
Code generation has become a critical capability for large language models (LLMs), but researchers face two significant challenges: the scarcity of coding benchmarks that accurately assess reasoning abilities and the lack of self-contained training resources. While benchmarks like LiveCodeBench have attempted to address data contamination through live updates, they cover only a limited number of problems and lack detailed metadata for comprehensive analysis.
The authors introduce LeetCodeDataset, a high-quality benchmark designed to overcome these limitations. By meticulously curating over 90% of Python problems from LeetCode, they've created a resource that serves dual purposes: robust evaluation and efficient training. Each problem in the dataset comes with rich metadata (difficulty levels, release dates, topic tags) and an average of 100+ test cases to minimize false positives.
A key innovation is the dataset's temporal split strategy - problems released after July 1, 2024 form the test set, while earlier problems constitute the training set. This approach ensures contamination-free evaluation while providing ample training material.
Building a Comprehensive Code Evaluation Dataset
Data Collection
As of March 2025, LeetCode hosted approximately 3,505 programming problems, with 3,115 supporting Python submissions. The data collection process began with this Python problem set and followed several key steps:
Metadata Acquisition: Using LeetCode's GraphQL API, the researchers collected comprehensive metadata for each problem, including unique identifiers, difficulty ratings, descriptions, starter code, and topic tags.
Canonical Solution Verification: Reference solutions were retrieved from open-source GitHub repositories and verified on the LeetCode platform to establish ground truth solutions with 100% acceptance rates.
Entry Point Identification: For each problem, the function targeted for testing was identified through text pattern matching, focusing exclusively on problems with single-function starter code.
Input Generation: Inputs for testing were generated using one-shot prompting with an LLM, followed by additional prompting to create more complex test cases.
Test Case Generation: Outputs were computed using canonical solutions in a sandboxed execution environment, with special handling for data structures like binary trees and linked lists.
Figure 1: An example of a LeetCode problem.
Through this process, the researchers successfully generated outputs for 2,869 problems, covering over 90% of all Python problems available on the platform.
For supervised fine-tuning (SFT), they employed Qwen2.5-Coder-32B-Instruct to implement a multi-stage generation process that produced diverse, verified solution candidates. The resulting dataset supports both evaluation and training, with the potential to facilitate reinforcement learning approaches as well.
Dataset Overview
The LeetCodeDataset can be analyzed along multiple dimensions:
Difficulty Levels: Problems are categorized into three levels of difficulty:
- Easy: Problems focusing on basic syntax and foundational data structure applications
- Medium: Problems requiring familiarity with classical algorithms and efficient strategy design
- Hard: Problems involving complex algorithmic combinations, mathematical insights, or specialized optimizations
| Difficulty | Release Year | ||||
|---|---|---|---|---|---|
| Type | Count | Proportion (%) | Period | Count | Proportion (%) |
| Easy | 686 | 23.91 | Before 2020 | 1077 | 37.54 |
| Medium | 1498 | 52.21 | 2020–2022 | 1009 | 35.17 |
| Hard | 686 | 23.88 | 2023–2025 | 783 | 27.29 |
Table 1: Distribution of difficulty and release year on the LeetCodeDataset.
Release Dates: The yearly distribution shows approximately 350 new problems added annually in recent years. This temporal information is valuable for contamination-free evaluation, with problems from the past 6-12 months providing an effective balance between bias and variance.
Topic Tags: Each problem is labeled with algorithm and data structure tags, with multiple tags permitted per problem. This tagging system helps learners focus on specific skills and provides valuable insights for LLMs.
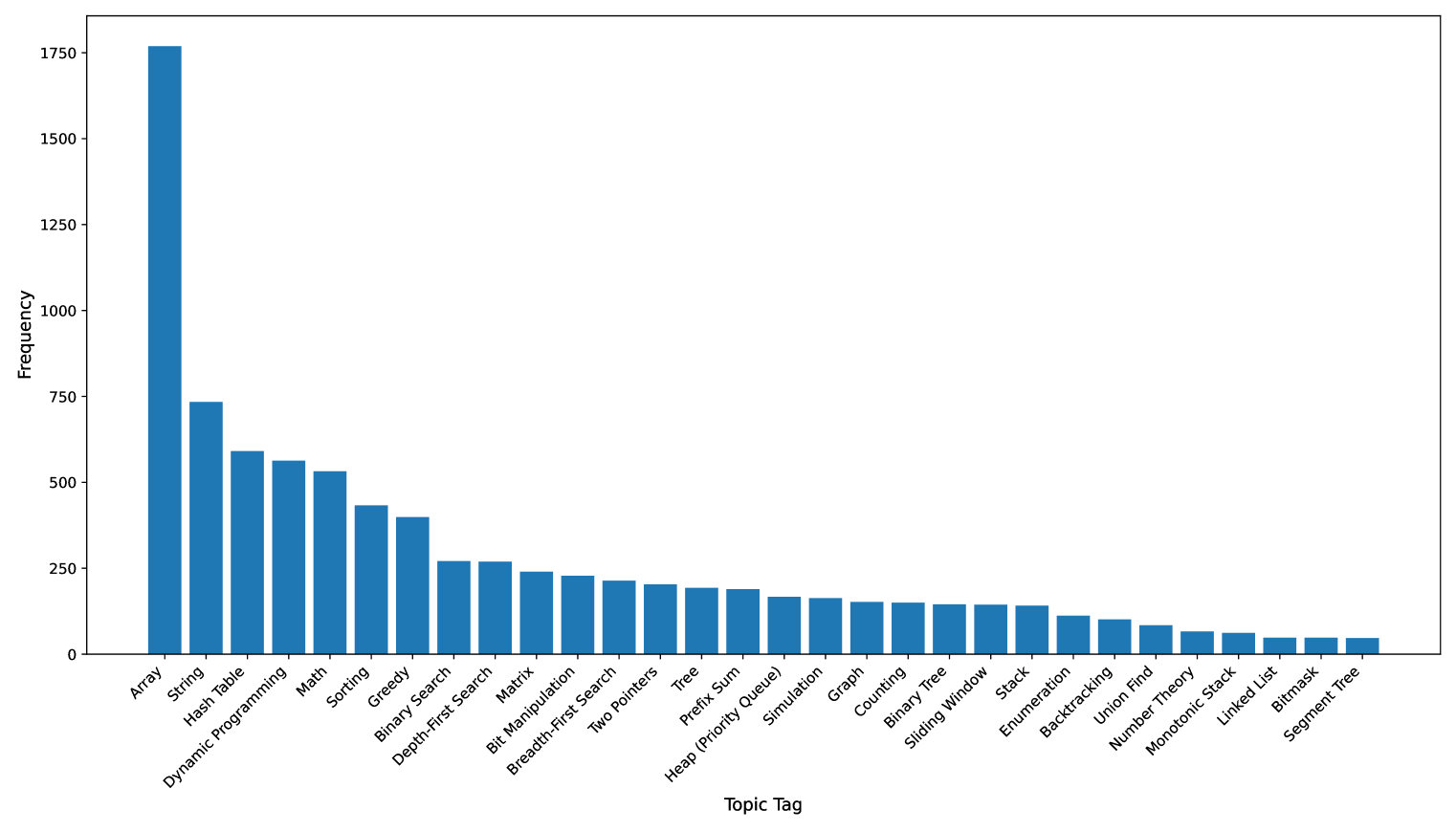
Figure 2: Topic frequency distribution.
The comprehensive coverage and detailed metadata make LeetCodeDataset a valuable resource for both evaluating existing models and training new ones.
Holistic Evaluation
The researchers evaluated six models on the LeetCodeDataset test set, which consists of 256 programming problems released after July 1, 2024. The evaluated models included:
- Two proprietary systems: GPT-4o and Claude 3.7 Sonnet
- Four open-source models: DeepSeek-V3, DeepSeek-R1, Qwen2.5-Max, and QwQ-Plus
All experiments used identical generation parameters (temperature=0.2, top_p=0.95) to ensure fair comparisons.
Following LiveCodeBench's temporal evaluation methodology, they analyzed monthly accuracy changes relative to problem release months and summarized model pass rates across difficulty levels.
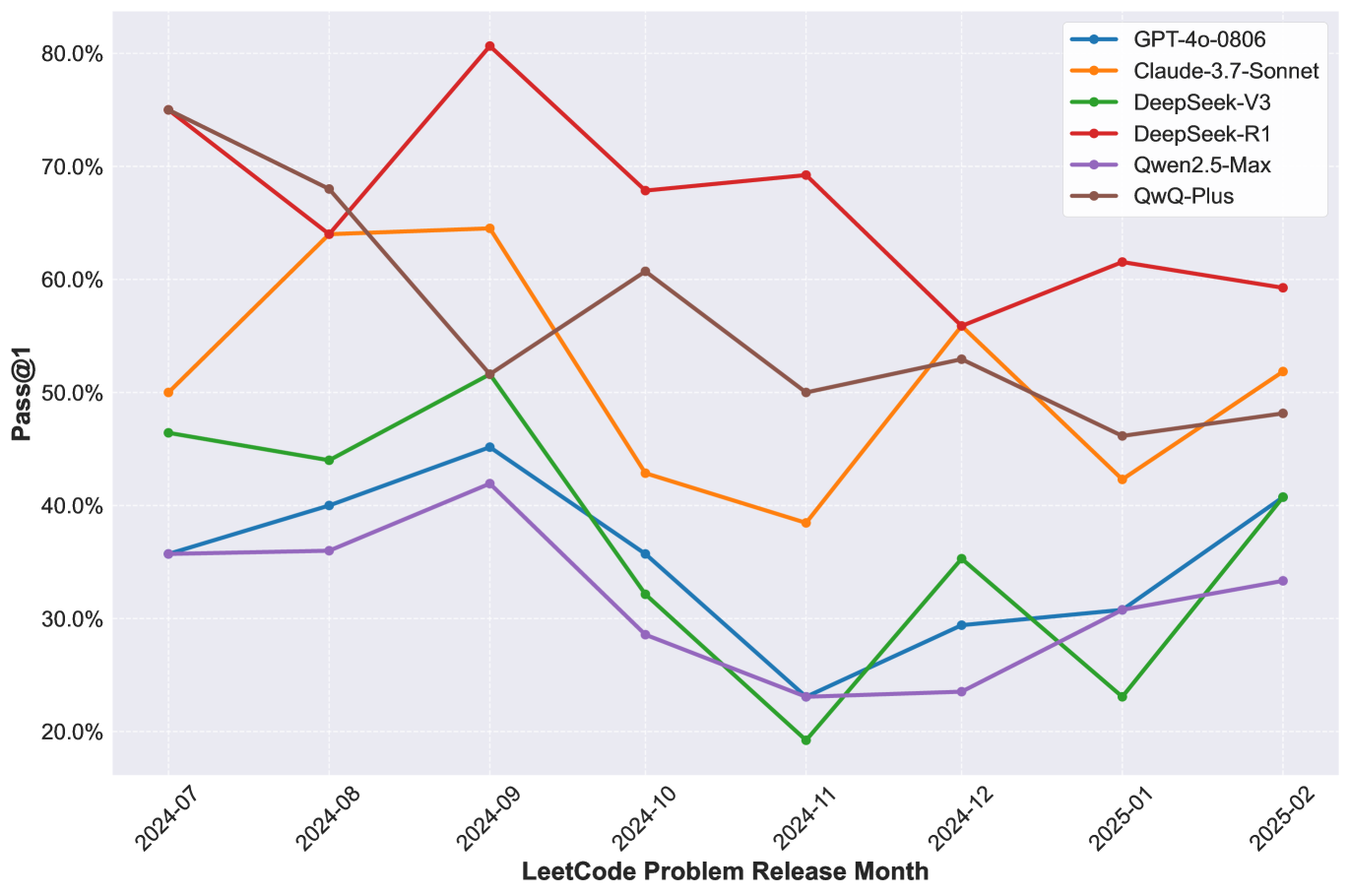
Figure 3: Monthly pass rates of various models on the LeetCodeDataset.
The evaluation revealed three key insights:
Superior Performance of Reasoning Models: DeepSeek-R1 (pass@1 rate = 65.23%) and QwQ-Plus (pass@1 rate = 56.25%) demonstrated substantial advantages in solving complex coding problems, highlighting the value of long-CoT reasoning capabilities.
Baseline Comparison: Claude-3.7-Sonnet performed best among non-reasoning models. GPT-4o and DeepSeek-V3 achieved identical overall scores, with GPT-4o performing better on easy problems and DeepSeek-V3 excelling on hard problems.
Contamination Analysis: The minimal temporal overlap between GPT-4o's release date (August 2024) and the test problem release window (post-July 2024) suggests authentic capability measurements.
| Model | Easy (%) | Medium (%) | Hard (%) | Overall (%) |
|---|---|---|---|---|
| GPT-4o-0806 | 81.48 | 32.76 | 10.47 | 35.55 |
| Claude-3.7-Sonnet | 87.04 | 54.31 | 23.26 | 50.78 |
| DeepSeek-V3 | 77.78 | 31.90 | 13.95 | 35.55 |
| DeepSeek-R1 | 94.44 | 68.97 | 41.86 | 65.23 |
| Qwen2.5-Max | 74.07 | 25.00 | 10.47 | 30.47 |
| QwQ-Plus | 92.59 | 62.93 | 24.42 | 56.25 |
Table 2: Model pass rates by difficulty level on the LeetCodeDataset.
The researchers also analyzed model performance across different topic tags, identifying each model's strengths and weaknesses. Key findings included:
- DeepSeek-R1 showed consistently strong performance across all topic tags, with pass rates mostly ranging from 60% to 70% and minimal variation.
- Non-reasoning models exhibited significant fluctuations, such as GPT-4o dropping to 7.7% in Binary Search tasks but reaching 63.2% in Simulation tasks.
- Significant performance gaps between reasoning and non-reasoning models appeared in Dynamic Programming, Binary Search, and Tree-related tasks.
| GPT-40 | DeepSeek -V3 |
Qwen2.5 -Max |
Claude-3.7 -Sonnet |
DeepSeek -R1 |
QwQ -Plus |
|
|---|---|---|---|---|---|---|
| Array | 32.1 | 34.5 | 28.0 | 51.2 | 67.9 | 55.4 |
| String | 37.3 | 38.8 | 35.8 | 49.3 | 68.7 | 50.7 |
| Dynamic Programming | 10.5 | 15.8 | 8.8 | 31.6 | 70.2 | 40.4 |
| Hash Table | 39.5 | 37.5 | 35.7 | 50.0 | 66.1 | 50.0 |
| Math | 38.2 | 40.0 | 32.7 | 56.4 | 69.1 | 58.2 |
| Greedy | 12.5 | 15.6 | 12.5 | 21.9 | 62.5 | 28.1 |
| Sorting | 20.0 | 20.0 | 6.7 | 36.7 | 66.7 | 53.3 |
| Prefix Sum | 17.9 | 14.3 | 14.3 | 35.7 | 71.4 | 35.7 |
| Binary Search | 7.7 | 23.1 | 11.5 | 30.8 | 73.1 | 30.8 |
| Sliding Window | 52.2 | 47.8 | 43.5 | 69.6 | 56.5 | 52.2 |
| Enumeration | 27.3 | 31.8 | 9.1 | 45.5 | 63.6 | 50.0 |
| Matrix | 19.0 | 33.3 | 19.0 | 52.4 | 76.2 | 61.9 |
| Simulation | 63.2 | 57.9 | 42.1 | 63.2 | 63.2 | 84.2 |
| Depth-First Search | 31.6 | 21.1 | 26.3 | 31.6 | 57.9 | 57.9 |
| Bit Manipulation | 33.3 | 44.4 | 27.8 | 50.0 | 50.0 | 66.7 |
| Combinatorics | 12.5 | 18.8 | 12.5 | 37.5 | 93.8 | 25.0 |
| Counting | 20.0 | 26.7 | 26.7 | 46.7 | 53.3 | 46.7 |
| Graph | 40.0 | 33.3 | 46.7 | 53.3 | 66.7 | 66.7 |
| Heap (Priority Queue) | 40.0 | 53.3 | 33.3 | 66.7 | 66.7 | 66.7 |
| Number Theory | 38.5 | 30.8 | 30.8 | 38.5 | 69.2 | 53.8 |
| Breadth-First Search | 41.7 | 33.3 | 50.0 | 58.3 | 58.3 | 75.0 |
| Tree | 27.3 | 18.2 | 9.1 | 9.1 | 72.7 | 54.5 |
| Two Pointers | 20.0 | 30.0 | 30.0 | 40.0 | 80.0 | 40.0 |
| Segment Tree | 30.0 | 30.0 | 30.0 | 70.0 | 80.0 | 30.0 |
| All | 35.5 | 35.5 | 30.5 | 50.8 | 65.2 | 56.2 |
Table 3: Model pass rates by topic tags on the LeetCodeDataset.
This detailed analysis, similar to that seen in Performance Study of LLM-Generated Code on LeetCode, provides valuable insights for future model development and improvement.
Efficient Training
Experiment Setup
The researchers conducted supervised fine-tuning (SFT) experiments using Qwen2.5-Coder-7B as the base model. Training parameters included:
- 3 epochs
- Initial learning rate of 1e-5
- Warmup ratio of 0.1
- Cosine learning rate scheduling
- Batch size of 32
These parameters remained consistent across all experiments to ensure fair comparisons.
Results
To evaluate the training efficiency of LeetCodeDataset, the researchers compared it with five widely-used coding datasets ranging from 9.5K to 111.1K samples - all substantially larger than the LeetCodeDataset training set of 2.6K samples.
Models were trained on each dataset and evaluated across four benchmarks: HumanEval, MBPP, LiveCodeBench, and the LeetCodeDataset evaluation set.
| Training Data | Rows | Human Eval |
MBPP | LiveCode Bench 24-08 25-02 |
LeetCode Dataset 24-07 25-03 |
|---|---|---|---|---|---|
| Magicoder Evol-Instruct-110K |
111.1 K | 77.4 | 74.1 | 15.1 | 13.7 |
| Magicoder OSS-Instruct-75K |
75.1 K | 73.8 | 76.5 | 15.1 | 12.9 |
| Open-R1 CodeForces-CoT |
9.5 K | 79.9 | 74.1 | 15.8 | 13.3 |
| OpenThoughts 114k |
19.9 K | 77.4 | 75.7 | 16.9 | 16.4 |
| LeetCodeDataset Pre 2024-07 human |
2.6 K | 55.5 | 53.4 | 14.0 | 10.9 |
| LeetCodeDataset Pre 2024-07 model |
2.6 K | 79.9 | 77.5 | 15.4 | 12.5 |
Table 4: Model SFT-training results.
The results revealed three key findings:
Superior Model-Generated Training Data: Models trained on model-generated responses significantly outperformed those trained on human-written responses (79.9% vs. 55.5% on HumanEval; 77.5% vs. 53.4% on MBPP), despite both being verified as correct. This highlights the quality advantage of model-generated training data for code generation tasks.
High Data Efficiency: Training with only 2.6K model-generated LeetCode samples achieved superior performance on HumanEval (79.9%) and MBPP (77.5%), surpassing models trained on much larger datasets. This demonstrates exceptional data efficiency for domain-specific code generation.
Limitations on Hard Benchmarks: Despite being in-distribution for LeetCodeDataset, the 2.6K-trained model underperformed on hard benchmarks, suggesting that small-scale SFT primarily develops basic programming skills.
These findings align with research on training efficiency in KodCode: A Diverse, Challenging, Verifiable Synthetic Dataset for Coding, which similarly emphasizes the value of high-quality, targeted training data.
Related Work
Code Generation Benchmarks: Numerous benchmarks have been developed to evaluate code generation capabilities in LLMs. For foundational Python programming, widely used benchmarks include HumanEval and MBPP. EvalPlus offers a more rigorous variant, while Multiple-E extends these benchmarks to 18 other programming languages.
As LLM capabilities advance, many benchmarks have become too easy to adequately assess modern models. Specialized benchmarks for competitive programming include APPS, CodeContests, and TACO, which source problems from platforms like Codeforces and AtCoder. LiveCodeBench provides holistic and contamination-free evaluations by dynamically updating coding challenges, while CODEELO aligns with the CodeForces platform by submitting directly to it.
Fine-tuning Datasets for Code: Synthetic data is a primary source for LLM supervised fine-tuning. CodeAlpaca employs few-shot prompting and teacher models to synthesize data, while Magicoder leverages open-source code snippets to generate high-quality instructional data. Competitive programming benchmarks like APPS and CodeTest provide training splits for SFT. For advanced reasoning, Open-R1 CodeForces-CoTs includes 10K CodeForces problems with reasoning traces, while OpenThoughts is a synthetic dataset with 114K examples spanning various domains.
Limitations
Despite its effectiveness, LeetCodeDataset has three key limitations:
False Positive Risks: While the dataset includes diverse inputs and test cases to reduce incorrect solutions passing, it lacks extremely complex input patterns and suffers from an imbalanced test case distribution. These limitations present residual risks of false positives, such as solutions passing tests despite logic errors.
Complexity Analysis Gap: Determining time and space complexity for problems requires LeetCode-style test cases tailored to each algorithm's behavior. This limitation exceeds the current scope as it demands manual problem-specific validation.
Coverage Gaps: The dataset doesn't include certain problem types, particularly problems with multiple solution entry points.
Future Impact
LeetCodeDataset addresses key challenges in code-generation research by providing a rigorously curated resource that enables reliable, contamination-free model evaluation and highly efficient training. Its temporal split ensures clean benchmarking and supports longitudinal studies, while its comprehensive coverage of algorithms and data structures facilitates robust overall evaluation and fine-grained skill analysis.
The integrated evaluation toolkit streamlines assessment and comparison across models, making it a valuable resource for researchers and practitioners alike.
Perhaps most importantly, the dataset demonstrates remarkable training efficiency - models trained on just 2.6K curated samples can match the performance of those trained on 110K examples from previous benchmarks. This finding suggests that future work might benefit from focusing on data quality rather than quantity.
LeetCodeDataset is available on Hugging Face and GitHub, positioning it to become a foundational resource for developing, training, and evaluating advanced code-generation models.
