
After completing the series on asynchronous programming, I needed some time off to deal with the stress in life. During the break, I decided to explore DSPy hands-on. The library claims to help build LLM applications programmatically. Let’s see if we can avoid prompt engineering by revisiting the word-guessing game we discussed previously.
I built a word guessing game with LLM

Image generated by copilot on the topic
The Problem with Traditional Prompts
Previously, the game logic was almost completely defined by the prompt we sent to the LLM chatbot. While the game worked almost perfectly with Gemini through OpenRouter, I quickly exhausted the limit. Fortunately, the code worked with the compatible API offered by Jan.ai, a tool to manage LLM models locally. However, the game logic breaks whenever I change to a new model. Minor adjustments needed to be made for each model, like rephrasing parts or even adding to the prompt. Every seemingly insignificant change to the prompt may cause failure in parsing user input or responding in proper format.

Photo by Om Kamath on Unsplash
The chatbot from DSPy’s website says
DSPy is a framework for building modular AI software, focusing on optimizing language model prompts and weights. It uses structured code instead of string prompts, enabling fast iteration and reliable software. DSPy abstracts prompt engineering and model fine-tuning, compiling AI programs into effective prompts and weights for tasks like classifiers and RAG pipelines, enhancing portability across models.
If I understand correctly, we can probably avoid writing precise prompts while building a LLM application through DSPy. Since we already build our game purely with prompts, it would be interesting to see how it compares when coded without.
The goal of this exercise is to explore, so the proposed solution may not be the most efficient. As the use of DSPy changes how logic is represented, it should also improve the gameplay experience.
From Prompt Templates to DSPy Modules
While going through the documentation and tutorial, I realize DSPy encourages developers to define behaviour in smaller units. Instead of lumping everything together into a long prompt, we break the task into smaller sub-tasks. For instance, in our word-guessing game, once the game is started, we used one single prompt to:
- Classify if the user input is a valid question or an answer
- Parse the question, and prepare a response to the question
- Check if the submitted guess matches the answer
- Generate an error message if the input is invalid
- Lastly, format the answer into a format our program expects
Recently, I started to hear a lot of discussions on how breaking tasks into smaller units may help to improve the quality of response. DSPy achieves this through the use of signatures, with a shorthand notation, it could be as simple as question -> answer.

Photo by Susan Holt Simpson on Unsplash
Instead of writing a prompt, I see signatures as a way to define a task in a more declarative fashion. Through the class-based definition, it is possible to supply more meta information to the task through a docstring, or the desc property of input and output fields. For example, we can break the original prompt into 2 parts, first on classification:
class Classifier(dspy.Signature):
attempt: str = dspy.InputField(desc="The user input in a 20 questions game")
category: Literal["question", "invalid"] = dspy.OutputField(
desc="The type of attempt supplied by the user in a 20 questions word guessing game"
)
response: str = dspy.OutputField(
desc="The response to be shown to user for invalid input"
)One thing I like about the use of signature is that it implicitly does the data formatting work in the background. In the previous incarnation, I needed to explicitly include the desired data template in the prompt, and for some reason every model responds to the template differently.
Then we have the part where we parse and respond to the questions our players submit.
class Question(dspy.Signature):
question: str = dspy.InputField(
desc="The user's question or a guess in a 20 questions game."
)
answer: str = dspy.InputField(
desc="The noun user is attempting to guess in a 20 questions game."
)
response: str = dspy.OutputField(
desc="The yes/no answer to the user's question in a sentence with the answer word replaced by 'the answer' whenever applicable"
)
result: bool = dspy.OutputField(desc="The true/false response to the user question")
found: bool = dspy.OutputField(
desc="True only if this is a guess and it matches the answer"
)I eventually realized it is easier to just assume players would guess, by asking questions “is the answer XYZ?”. In this reimplementation, I am testing it with a locally hosted LLM, so the simpler setup should work better.
Lastly, I needed a welcome speech, as well as an answer generator. For that, we define an output only signature as shown below,
class NewGame(dspy.Signature):
speech: str = dspy.OutputField(
desc="The elaborative welcome text for a word guessing game called GuessMe, with gameplay explanation adapted from the game 20 questions without the question limit."
)
answer: str = dspy.OutputField(
desc="The chosen random noun as the answer for a 20 questions game session"
)Each signature roughly correspond to one prompt. So instead of 2 long ones, we now not only have one more, and it seems like we are defining more things now (though managed by DSPy in the background).
Let’s compare the original new game prompt
I want to welcome users to play a word guessing game called GuessMe. Please craft a welcome message, and quickly explain that the user can either ask a yes no question, or attempt to answer. Then, pick a random noun from the dictionary as the answer to the game. Construct a JSON following the template below and fill the placeholder accordingly,
{"message": , "type": "answer", "response": }
Return only the JSON without comments, do not include answer in welcome message.
Notice how it was written as an instruction to the language model. On the other hand, in the NewGame signature, it was written such that we only explain what each field expects. When we reduce the scope of each definition, it also means no more trivial adjustments when changing models. Ideally, that is.
There are other pros to the approach, but I am not going through all of them as they are not immediately obvious in our toy example. Let’s move on to turning the signature to work.
Declaring a signature is like writing a prompt template, to be populated with user input whenever applicable. The composition, and response handling work, would be done by a DSPy module. Let’s start with the easiest task, the new game setup. We could instantiate a new module by passing the signature class name to the dspy.Predict built-in module, as shown below:
module_new = dspy.Predict(NewGame) # instatiate a module to start a new gameThen to start a new game, we call
game = module_new()
game.speech # the welcome speech explaining the game rule
game.answer # the secret wordAs we are not expecting an input, so module_new callable does not take any parameter. However, when we pass user input to the classifier
module_classifier = dspy.ChainOfThought(Classifier)
input_type = module_classifier(attempt=user_input, answer=game.answer)
input_type.category # either "question" or "invalid"
input_type.response # some error message if category is "invalid"
input_type.reasoning # some additional insight on how output fieldss are generatedLike dspy.Predict, dspy.ChainOfThought is also a built-in module. It encourages the language model to perform some inferencing before generating a proper response, therefore improving the output quality. Practically, it also helps with debugging and can provide valuable insight if we log the reasoning field value.
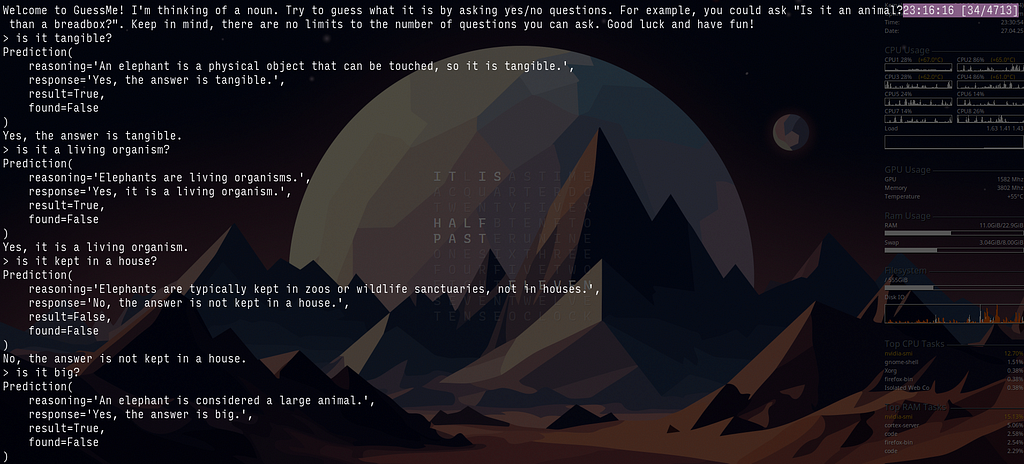
A playthrough with reasoning shown
It seems like we have everything ready to assemble the final application. However, there’s one thing we need to address. As shown previously, the answer gets spoiled easily when we switch to a smaller model. Thankfully, there’s a way to discourage such behaviour, which is essential in improving the gameplay. Let’s write a reward function to score the output, so it does not return the answer in response ever.
def do_not_spoil(answer: str) -> Callable[..., float]:
def inner(_args, pred: dspy.Prediction) -> float:
DEBUG and print(pred) # type: ignore
if hasattr(pred, "found") and pred.found:
return 1.0
return (
1.0
if answer.lower() not in pred.response.lower()
and len(pred.response.split()) > 1
else 0.0
)
return innerI know we discussed on __call__ dunder, but I opt for a closure for simplicity. So if the response has more than a word and does not contain the answer, we return a rank of 1.0, or 0 otherwise. To encourage that behaviour, we use dspy.BestOfN as follows,
module_question = dspy.BestOfN(
module=dspy.ChainOfThought(Question),
N=10,
reward_fn=do_not_spoil(game.answer),
threshold=1.0,
)In this case, the supplied model will be executed with different temperature values, and the first prediction that returns the threshold ranking of 1.0 according to do_not_spoil will be returned.
Lastly, we initialize the set-up of the language model. Since the beginning we only work with OpenAI compatible API. As DSPy wraps liteLLM, we need to configure the model according to the documentation, i.e. prefixing openai/ provider to the desired model name
dspy.configure(
lm=dspy.LM(
f"openai/gemma2:9b",
api_base="https://localhost:1337/v1",
api_key="",
temperature=1.0,
cache=False,
)
)We are skipping caching as this is a game, so regeneration of responses is fine.
The complete implementation can be found on GitHub, in the same repository as before. It is implemented as a simple command line interface (CLI) application, so just run it with uv run python ./src/guessme/cli.py after configuring the .env as instructed in the README. Prefix the environment variable declaration DEBUG=True to read the reasoning to each response.
GitHub - Jeffrey04/guessme-llm: A classic guessing game powered by LLM
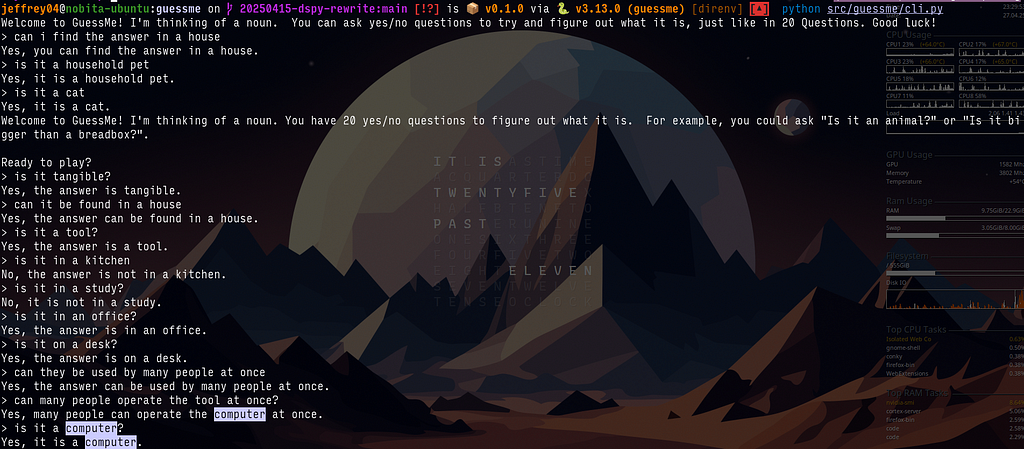
An example playthrough with Gemma2:9b
I only tested with some of the available models that my GPU is capable of running, namely gemma2:9b (with reduced context length and GPU layers), deepseek-r1:7b and cogito-v1:8b. So far only the gemma2 gave reasonable playing experience, and I managed to finish a game (as shown in the screenshot above).
The parsing of questions has proved to be problematic for smaller models, even though we simplified the scope. Apart from gemma2, none of the other tested models managed to properly parse the question and set the found (indicating the answer is found) and result (indicate yes/no response to the question) flag properly.
Key Takeaways

Photo by Hitesh Choudhary on Unsplash
To answer the question we raised in the opening, we did manage to eliminate prompts in this reimplementation. While doing so, we managed to get a decent gameplay experience with at least one locally hosted language model. I would consider this a win (no pun intended). The exercise proves that with clever engineering, it is possible to build usable applications with smaller models.
Though we managed to build our application without writing a single line of prompt, the adoption of this declarative technique remained to be observed. Vibe-coding is gaining a lot of traction these days, and everyone seems to be still deciding whether it is a good thing. The key to vibe-coding lies in producing clear and precise prompts, and prompt engineering is definitely staying for a bit. However, I still hope to explore further into DSPy, as I really like the declarative design.
Besides saving us from writing (and adjusting) prompts, I like how we could encourage response to fulfil specific criteria through a reward function. My attempt to prevent spoilers with smaller models with prompts in the response previously was painful and yet unsuccessful. In the current iteration, it worked immediately. I hope to explore further into more LLM application building in future, and would definitely keep an eye on the library. I am particularly interested in the composability aspect of the library, where multiple modules can be assembled together, forming a pipeline (imagine composing the classifier and question parser one after another). This should open the possibility of more complex use-cases, and the simplicity leads to a more maintainable code.

Photo by Clem Onojeghuo on Unsplash
I started the project not too long after concluding the asynchronous programming series, and was stuck for a bit with liteLLM because it wouldn’t stop bugging me for missing provider in the model name. At the time, I was in the middle of a multi-stage job interviews (it was my only application that was progressing at the time) and I got quite anxious throughout. Hopefully I am doing decent enough as I progressed into the final stage, though it was also rather stressful as my unemployment persists. Let’s hope things are turning out to be in my favor.
Thanks for reading this far, and I shall write again, next week.
This article is a collaboration: I wrote the draft, and Gemini provided editorial assistance. The story and voice are mine. The code examples are unaltered. For project collaborations and job opportunities, contact me via Medium or LinkedIn.