Introduction
In today's increasingly globalized world, the demand for multilingual content is exploding. Whether it's technical documentation, blog posts, research reports, or personal notes, translating them into different languages can significantly expand their audience and impact. However, traditional translation methods, such as manual translation, are costly and time-consuming. Using online translation services (like Google Translate, DeepL, etc.) might involve concerns about data privacy, API call fees, and network connectivity limitations.
For developers, content creators, and tech enthusiasts seeking efficiency, data privacy, and cost-effectiveness, is there a way to perform high-quality batch translation locally, offline, and at a low cost? The answer is yes! With the maturation and popularization of local Large Language Model (LLM) technology, we can now run powerful AI models on our own computers to accomplish various tasks, including text translation.
And for ServBay users, this becomes even simpler and more integrated. ServBay, as a powerful integrated Web development environment, not only provides convenient management of web servers, databases, and language environments but its latest version also keeps pace with technological trends by incorporating built-in support for AI/LLM, specifically integrating the popular Ollama framework. This means you can easily deploy and manage local AI models within the ServBay environment without complex configurations and leverage their powerful capabilities.
This tutorial, based on ServBay, will guide you in detail on how to:
- Understand ServBay's latest AI/LLM support, particularly its integrated Ollama features.
- Easily install and configure the Ollama service within ServBay.
- Search, download, and manage Ollama models suitable for translation tasks through ServBay's graphical interface.
- Write a Python script that utilizes the Ollama API endpoint provided by ServBay to automate the batch translation of all Markdown (
.md) files within a specified folder (e.g.,docs).
Through this tutorial, you will master a powerful, private, and efficient local document translation solution, fully unleashing the potential of ServBay and local AI. Let's embark on this exciting local AI journey!
Part 1: ServBay's AI / LLM New Era: Embracing Local Intelligence
ServBay has always been committed to providing developers with a one-stop, efficient, and convenient local development environment. From managing multiple versions of PHP, Python, Java, .Net, Node.js, switching between Nginx/Apache/Caddy, to supporting MySQL/PostgreSQL/MongoDB databases, ServBay greatly simplifies the setup and maintenance of development environments. Now, ServBay is once again at the forefront, integrating powerful AI/LLM capabilities into its core features, opening a new chapter of local intelligence for its users.
Integrating Ollama: The Swiss Army Knife for Local LLMs
The core of ServBay's AI functionality is the integration of Ollama. Ollama is an open-source project designed to enable users to easily run large language models like Llama 3, Mistral, Phi-3, Gemma3, etc., locally. It significantly simplifies the process of setting up, running, and managing models, providing a standard API interface that allows developers to interact with local models as conveniently as calling cloud services.
ServBay's integration of Ollama brings numerous advantages:
- One-Click Installation and Configuration: ServBay provides a dedicated graphical interface to manage Ollama. Users don't need to manually download Ollama, configure environment variables, or manage complex dependencies. Simply enable and configure it briefly in ServBay's AI panel, and you have a ready-to-use local LLM service.
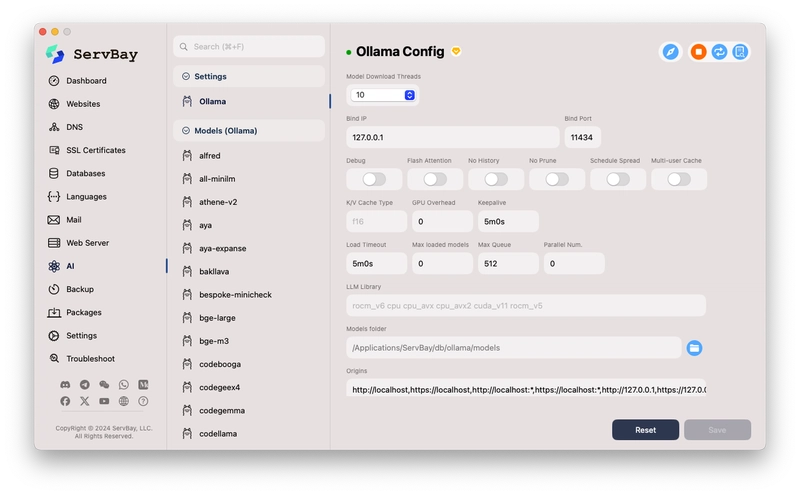
- Visual Configuration Management: ServBay offers rich configuration options, such as
Model Download Threads,Bind IP,Bind Port(defaults to127.0.0.1:11434, the standard Ollama configuration), debug switches (Debug,Flash Attention,No History,No Prune,Schedule Spread,Multi-user Cache), cache type (K/V Cache Type), GPU optimization (GPU Overhead), connection persistence (Keepalive), load timeout (Load Timeout), maximum loaded models (Max loaded models), maximum queue (Max Queue), parallel processing number (Parallel Num.), LLM library path (LLM Library), model storage path (Models folder), and access origin control (origins). This allows users to fine-tune Ollama's runtime parameters based on their hardware and needs without memorizing command-line arguments. - Unified Ecosystem: Integrating Ollama into ServBay means your web development environment and AI inference environment can work together under the same management platform. This provides great convenience for developing web applications that require AI functions (such as intelligent customer service, content generation, local data analysis, etc.).
Convenient Model Management
Just having a running framework isn't enough; selecting and managing appropriate AI models is equally important. ServBay excels in this area as well:
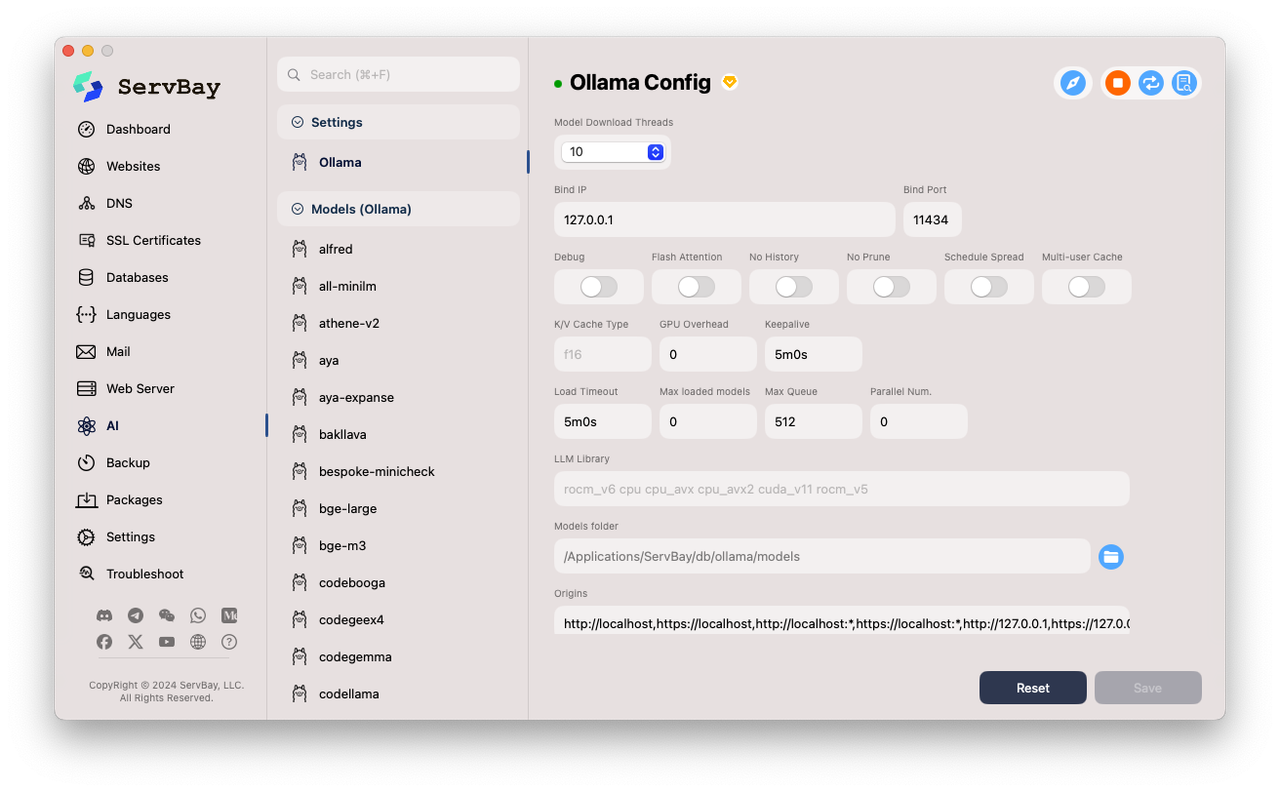
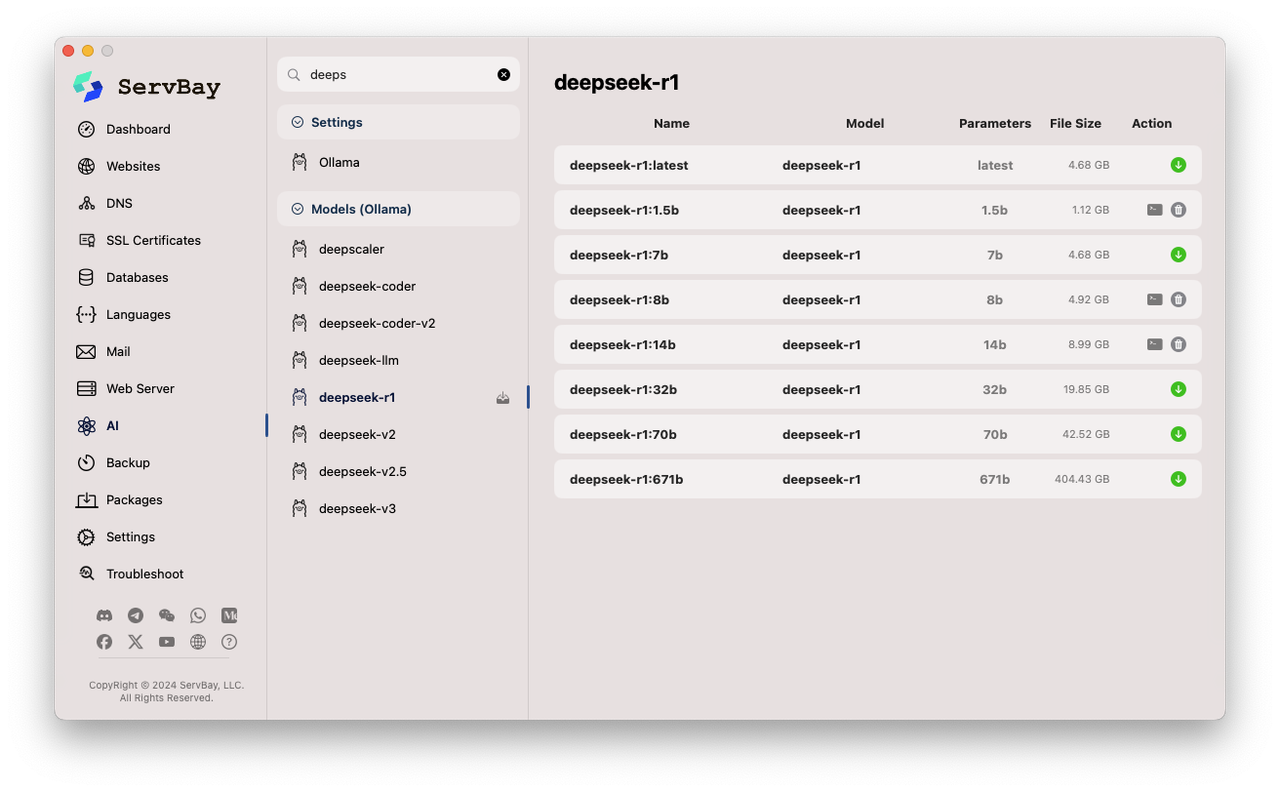
- Model Listing and Search: ServBay provides a model list interface where users can directly search for available models in the official Ollama model library (e.g., the screenshot shows searching for
deepsdisplaying different versions ofdeepseek-r1). - One-Click Download and Deletion: For searched models, the interface clearly displays the model name (including tags like
latest,1.5b,7b, etc.), base model, number of parameters (Parameters), file size (File Size), and action buttons (download+or delete). Users simply click a button, and ServBay automatically handles the download and storage of the model (the storage path can be specified in the Ollama configuration, defaulting to/Applications/ServBay/db/ollama/models). - Local Model Overview: In the
Ollama Configinterface (first screenshot), the left-side list shows the models currently downloaded locally (e.g.,alfred,all-minilm,codellama, etc.). This gives users a clear overview of the local AI "brains" they possess.
Core Value of Local AI
Why use local AI (via Ollama in ServBay) for translation instead of continuing with online services?
- Data Privacy and Security: This is the most crucial advantage. All data processing is done on your own computer; your document content doesn't need to be sent to any third-party servers. This is essential for documents containing sensitive information or trade secrets.
- Cost-Effectiveness: Running LLMs locally incurs no API call fees. While there might be an initial hardware investment (especially if GPU acceleration is needed), the long-term cost for large or frequent tasks is far lower than pay-as-you-go cloud services.
- Offline Availability: Once a model is downloaded locally, you can perform translation or other AI tasks without an internet connection, which is very useful in environments with unstable networks or scenarios requiring complete offline operation.
- Customization and Control: You have the freedom to choose the model best suited for your task and hardware, experiment with different model versions and parameters, and even perform fine-tuning (although ServBay itself doesn't directly provide fine-tuning features, the localized Ollama environment lays the foundation for it).
- Low Latency: Requests are sent directly to the locally running service, typically resulting in lower latency and faster responses compared to calling remote APIs over the internet.
In summary, by integrating Ollama, ServBay significantly lowers the barrier for users to utilize local large language models, seamlessly incorporating their powerful AI capabilities into a familiar development environment, providing a solid foundation for implementing advanced automation tasks like batch document translation.
Part 2: Installing and Configuring Ollama and Models in ServBay
Now, let's walk through setting up the Ollama service in ServBay step-by-step and download a model suitable for translation tasks.
Step 1: Navigate to ServBay's AI Configuration
- Launch the ServBay application.
- In the left-hand navigation bar of the ServBay main interface, find and click AI.
- In the AI sub-menu, click Ollama. You should see an interface similar to the
Ollama Configshown in the first screenshot.
Step 2: Check and (Optionally) Adjust Ollama Configuration
ServBay usually provides a reasonable set of default configurations, often sufficient for initial use or basic tasks. However, understanding these options helps with future optimization:
- Ollama Service Status: There is usually a toggle switch or status indicator at the top of the interface (a green dot in the screenshot). Ensure the Ollama service is enabled. If ServBay provides Start/Stop buttons, make sure it's running.
- Bind IP and Bind Port: The defaults
127.0.0.1and11434are standard configurations, meaning the Ollama service listens only for requests from the local machine on port 11434. This is the address our Python script will need to connect to later. Usually, no changes are needed. - Models folder: This is the path where downloaded LLM models are stored. The screenshot shows
/Applications/ServBay/db/ollama/models. You can change this to another location with sufficient disk space if needed, but ensure the path exists and ServBay has write permissions. Note this path; although the script doesn't use it directly, knowing where the models are is helpful. - Model Download Threads: The number of concurrent threads used when downloading models. If you have a good network connection, you can increase this slightly to speed up downloads. The default is 10.
- Other Options (e.g., GPU Overhead, Max loaded models, etc.): These are more advanced performance tuning options. If you have a compatible GPU (NVIDIA or Apple Silicon), Ollama usually detects and uses it automatically.
Max loaded modelslimits the number of models loaded into memory/VRAM simultaneously, depending on your RAM/VRAM size. For batch translation tasks, usually only one model is loaded at a time, so the default value is generally sufficient. - Origins: This is the CORS (Cross-Origin Resource Sharing) setting, controlling which web pages (origins) can access the Ollama API. The default includes various variations of
http://localhostandhttp://127.0.0.1, which is usually sufficient for local scripts or local web applications.
Important Note: If you modify any configuration, be sure to click the Save button in the lower right corner of the interface to apply the changes. If you encounter problems, you can try clicking Reset to restore the default settings.
Step 3: Navigate to the Model Management Interface
- In the left-hand navigation bar of ServBay, under the AI category, click Models (Ollama).
- You will see a model management interface similar to the second screenshot. This lists models available for download and those already installed locally.
Step 4: Search for and Download a Translation Model
Now we need to select and download an LLM suitable for translation tasks. An LLM's translation capability is often related to its general instruction-following ability and multilingual training data. Some good choices might include (as of writing):
- Llama 3 series (e.g.,
llama3:8b): Meta AI's latest open-source model, with strong general capabilities and good instruction following, usually handles translation tasks well. The 8B version has relatively moderate hardware requirements. - Mistral series (e.g.,
mistral:7b): Another very popular high-performance open-source model known for its efficiency. - DeepSeek Coder/LLM series (e.g.,
deepseek-llm:7b-chat): Although DeepSeek is known for its coding abilities, its general chat models usually also possess translation capabilities. Thedeepseek-r1in the screenshot might be one of its variants or a specific version. - Specialized Translation Models (if available in the Ollama library): Sometimes there are models specifically optimized for translation, but strong general instruction-following models often perform very well too.
Performing Search and Download:
- In the search box at the top of the model management interface, enter the name of the model you want to find, e.g.,
llama3ormistral. - The interface will dynamically display a list of matching models, including different parameter sizes (like 7b, 8b, 70b, etc.) and tags (like
latest,instruct,chat). - Considerations when selecting a model:
-
Parameters: Such as
7b(7 billion),8b(8 billion),70b(70 billion). Larger parameter counts usually mean stronger capabilities but also higher requirements for memory (RAM) and video memory (VRAM), and slower inference speed. For batch translation, a7bor8bmodel is often a good starting point, balancing performance and resource consumption. -
Tags: Models tagged
instructorchatare usually better at following instructions (like "Please translate the following text into..."). - File Size: Note that model files can be large (from several GB to tens of GB). Ensure you have sufficient disk space.
-
Parameters: Such as
- Find the model version you want to download (e.g.,
llama3:8b) and click the download icon next to it (usually a downward arrow). - ServBay will start downloading the model. You can see the download progress. The download time depends on your network speed and the model size.
Step 5: Verify Model Installation
Once the model download is complete, it should appear in the list of installed models on the left side of the Ollama Config interface. Also, in the Models (Ollama) interface, the action button for that model might change to a delete icon (🗑️).
Step 6: Confirm Ollama Service is Running
Ensure the status indicator at the top of the Ollama Config interface shows green or a running state. ServBay usually starts the Ollama service automatically when you launch the application or enable the AI features. If the service is not running, look for a start button and activate it.
At this point, your ServBay environment has the Ollama service configured, and you have downloaded a local LLM ready for translation. Next, we will write the Python script to call this local AI service.
Part 3: Writing the Python Script for Batch Translation
Now that we have an LLM running locally and accessible via an API (http://127.0.0.1:11434), let's write a Python script to automate the translation process: iterate through all Markdown files in the specified docs folder, send their content to Ollama for translation, and save the results to new files.
Prerequisites
- Python Environment: Ensure Python is installed on your system. You can check by running
python --versionorpython3 --versionin your terminal. ServBay comes with Python 3. If not installed, install it from ServBay'sPackages->Python.
-
requestsLibrary: We need therequestslibrary to send HTTP requests to the Ollama API. If not already installed, run this in your terminal:
pip install requests # or pip3 install requests Create Project Structure:
- Create a project folder, for example, `servbay_translator`.
- Inside the `servbay_translator` folder, create a subfolder named `docs`. Place the Markdown files (`.md`) you need to translate into the `docs` folder and its subfolders. For example:```
servbay_translator/
├── docs/
│ ├── introduction.md
│ ├── chapter1/
│ │ └── setup.md
│ └── chapter2/
│ └── usage.md
└── translate_script.py (We will create this file)
```- The script will automatically create a `translated_docs` folder to store the translated files, maintaining the original directory structure.Python Script (translate_script.py)
import os
import requests
import json
import time
# --- Configuration Constants ---
# Ollama API address and port (consistent with ServBay config)
OLLAMA_API_URL = "http://127.0.0.1:11434/api/generate"
# The model name you downloaded in ServBay and want to use for translation
# Ensure it exactly matches the model name in Ollama
# Examples: "llama3:8b", "mistral:7b", "deepseek-llm:7b-chat" etc.
MODEL_NAME = "llama3:8b" # <--- Change this to your chosen model name!
# Directory containing the source Markdown files
SOURCE_DIR = "docs"
# Directory to store the translated files (script will create it)
TARGET_DIR = "translated_docs"
# The target language you want to translate the documents into
TARGET_LANGUAGE = "English" # Examples: "Simplified Chinese", "French", "German", "Japanese", "Spanish"
# Optional: Add a delay (in seconds) between requests to avoid overloading or give the system time to respond
REQUEST_DELAY = 1 # 1 second delay, adjust as needed
# --- Ollama API Call Function ---
def translate_text_ollama(text_to_translate, model_name, target_language):
"""
Translates the given text using the Ollama API.
Args:
text_to_translate (str): The original text to be translated.
model_name (str): The name of the Ollama model to use.
target_language (str): The target language for translation.
Returns:
str: The translated text, or None if an error occurred.
"""
# Construct a clear translation instruction prompt
prompt = f"""Translate the following Markdown text into {target_language}.
Preserve the original Markdown formatting (like headings, lists, bold text, code blocks, etc.).
Only output the translated text, without any introductory phrases like "Here is the translation:".
Original Text:
---
{text_to_translate}
---
Translated Text ({target_language}):"""
headers = {'Content-Type': 'application/json'}
data = {
"model": model_name,
"prompt": prompt,
"stream": False, # Set to False to get the full response at once, not streaming
# Optional parameters, adjust as needed, e.g., temperature controls creativity (lower is more conservative)
# "options": {
# "temperature": 0.3
# }
}
try:
print(f" Sending request to Ollama (model: {model_name})...")
# Increase timeout to 300 seconds for potentially long translations
response = requests.post(OLLAMA_API_URL, headers=headers, json=data, timeout=300)
response.raise_for_status() # Check for HTTP errors (e.g., 404, 500)
response_data = response.json()
# Extract the translated text from the response
# Ollama's /api/generate response structure usually contains the full output in the 'response' field
if 'response' in response_data:
translated_text = response_data['response'].strip()
print(f" Translation received (length: {len(translated_text)} chars).")
return translated_text
else:
print(f" Error: 'response' key not found in Ollama output: {response_data}")
return None
except requests.exceptions.RequestException as e:
print(f" Error calling Ollama API: {e}")
return None
except json.JSONDecodeError:
print(f" Error decoding JSON response from Ollama: {response.text}")
return None
except Exception as e:
print(f" An unexpected error occurred during translation: {e}")
return None
# --- Main Processing Logic ---
def process_directory(source_base, target_base):
"""
Recursively traverses the source directory, translates .md files,
and saves them to the target directory, preserving structure.
"""
print(f"\nProcessing directory: {source_base}")
for item in os.listdir(source_base):
source_path = os.path.join(source_base, item)
target_path = os.path.join(target_base, item)
if os.path.isdir(source_path):
# If it's a subdirectory, process it recursively
print(f"- Found subdirectory: {item}")
process_directory(source_path, target_path)
elif os.path.isfile(source_path) and item.lower().endswith(".md"):
# If it's a Markdown file, translate it
print(f"- Found Markdown file: {item}")
# Ensure the target file's parent directory exists
target_file_dir = os.path.dirname(target_path)
if not os.path.exists(target_file_dir):
print(f" Creating target directory: {target_file_dir}")
os.makedirs(target_file_dir)
# Optional: Check if target file already exists and skip
# if os.path.exists(target_path):
# print(f" Skipping, target file already exists: {target_path}")
# continue
try:
# Read the source file content
print(f" Reading source file: {source_path}")
with open(source_path, 'r', encoding='utf-8') as f_in:
original_content = f_in.read()
if not original_content.strip():
print(" Skipping empty file.")
continue
# Call Ollama for translation
translated_content = translate_text_ollama(original_content, MODEL_NAME, TARGET_LANGUAGE)
if translated_content:
# Write the translated content to the target file
print(f" Writing translated file: {target_path}")
with open(target_path, 'w', encoding='utf-8') as f_out:
f_out.write(translated_content)
print(" Translation complete for this file.")
else:
print(f" Failed to translate file: {source_path}. Skipping.")
# Add delay between API requests
if REQUEST_DELAY > 0:
print(f" Waiting for {REQUEST_DELAY} second(s)...")
time.sleep(REQUEST_DELAY)
except Exception as e:
print(f" Error processing file {source_path}: {e}")
else:
print(f"- Skipping non-Markdown file or other item: {item}")
# --- Script Entry Point ---
if __name__ == "__main__":
print("Starting Markdown Bulk Translation Process...")
print(f"Source Directory: {SOURCE_DIR}")
print(f"Target Directory: {TARGET_DIR}")
print(f"Target Language: {TARGET_LANGUAGE}")
print(f"Using Ollama Model: {MODEL_NAME} at {OLLAMA_API_URL}")
print("-" * 30)
# Check if source directory exists
if not os.path.isdir(SOURCE_DIR):
print(f"Error: Source directory '{SOURCE_DIR}' not found.")
print("Please create the 'docs' directory and place your Markdown files inside.")
exit(1)
# Check/Create target directory
if not os.path.exists(TARGET_DIR):
print(f"Creating target directory: {TARGET_DIR}")
os.makedirs(TARGET_DIR)
# Start processing
try:
process_directory(SOURCE_DIR, TARGET_DIR)
print("\n" + "=" * 30)
print("Batch translation process finished!")
print(f"Translated files are saved in the '{TARGET_DIR}' directory.")
except Exception as e:
print(f"\nAn error occurred during the process: {e}")Code Explanation:
-
Import Libraries (
import os, requests, json, time):-
os: For file and directory operations (walking directories, checking paths, creating directories, etc.). -
requests: For sending HTTP POST requests to the Ollama API. -
json: For handling JSON data in API requests/responses (thoughrequestshandles much of this internally here). -
time: For adding delays between requests (time.sleep).
-
-
Configuration Constants:
-
OLLAMA_API_URL: The endpoint for the Ollama generation API. Ensure this matches the IP and port in your ServBay configuration. -
MODEL_NAME: Crucial! Must exactly match the name (including the tag) of the model you downloaded in ServBay and wish to use. Modify this according to your chosen model. -
SOURCE_DIR: The name of the folder containing the original.mdfiles. -
TARGET_DIR: The name of the folder where the translated.mdfiles will be saved. -
TARGET_LANGUAGE: The name of the language you want to translate into. Use clear language names like "Simplified Chinese", "French", "German", "English". LLMs usually understand these natural language instructions. -
REQUEST_DELAY: How many seconds to wait after processing one file before starting the next. This helps prevent overloading the Ollama service or exhausting local machine resources, especially when processing many files or using resource-intensive models.
-
-
translate_text_ollamaFunction:- Takes the original text, model name, and target language as input.
- Build Prompt: This is key to communicating with the LLM. We construct a clear instruction telling the model:
- The task is to "Translate the following Markdown text into [Target Language]".
- Emphasize "Preserve the original Markdown formatting". This is vital for document translation.
- Request "Only output the translated text" to avoid extra explanatory phrases from the model (like "Here is the translation:").
- Use
---separators to clearly mark the original text.
- Prepare API Request: Set the request headers (
Content-Type: application/json) and the request body (data).-
model: Specifies the model to use. -
prompt: Our carefully crafted instruction. -
stream: False: We want the complete translation result at once, not streamed fragments. -
options(commented out optional part): You can pass additional Ollama parameters liketemperature(controls randomness/creativity; for translation, lower values like 0.2-0.5 are often better).
-
- Send Request: Use
requests.postto send the request to the Ollama API. A longertimeout(300 seconds) is set to handle potentially large files or slower model responses. - Error Handling:
-
response.raise_for_status(): Checks for HTTP-level errors (like 404 Not Found, 500 Internal Server Error). -
try...exceptblock catches network request errors (requests.exceptions.RequestException), JSON parsing errors (json.JSONDecodeError), and other unexpected errors.
-
- Parse Response: If the request is successful, extract the
responsefield from the returned JSON data, which usually contains the complete text generated by the LLM (i.e., the translation)..strip()removes any leading/trailing whitespace. - Return Result: Returns the translated text, or
Noneif an error occurred.
-
process_directoryFunction:- This is a recursive function designed to handle the directory structure.
- Takes the current source directory path (
source_base) and the corresponding target directory path (target_base). - Uses
os.listdirto get all files and subdirectories in the current directory. - Iterates:
- If it's a subdirectory: Prints info and recursively calls
process_directoryfor that subdirectory, passing the updated source and target paths. - If it's a file ending with
.md:- Prints info.
- Create Target Directory: Uses
os.path.dirnameto get the expected parent directory of the target file. If this directory doesn't exist,os.makedirscreates it (including any necessary intermediate directories). - Read Source File: Uses
with open(...)to read the.mdfile content using UTF-8 encoding. - Skip Empty Files: If the file content is empty, skip it.
- Call Translation Function: Passes the file content to the
translate_text_ollamafunction for translation. - Write Target File: If translation was successful (returned non-
None), writes the translated result to the corresponding target path file using UTF-8 encoding. - Handle Failure: If translation failed, prints an error message and skips the file.
- Apply Delay: Calls
time.sleep(REQUEST_DELAY)to wait for the specified number of seconds.
- If not an
.mdfile or directory: Prints a skipping message.
- If it's a subdirectory: Prints info and recursively calls
-
Main Execution Block (
if __name__ == "__main__":):- This is the script's entry point.
- Prints startup information, showing the configuration parameters.
- Check Source Directory: Ensures
SOURCE_DIRexists; exits with an error if not. - Create Target Directory: Creates
TARGET_DIRif it doesn't exist. - Start Processing: Calls the
process_directoryfunction, starting from the top-levelSOURCE_DIRandTARGET_DIR. - Completion & Error Catching: Uses a
try...exceptblock to catch potential errors during the entire process and prints a completion message or error information at the end.
Part 4: Running the Script and Considerations
How to Run the Script:
- Open Terminal.
-
Navigate to the Project Directory: Use the
cdcommand to enter theservbay_translatorfolder you created.
cd /path/to/your/servbay_translator # Example if using ServBay's default www location: # cd /Applications/ServBay/www/servbay_translator Ensure ServBay and Ollama Service are Running: Go back to the ServBay interface and confirm that the AI -> Ollama service is active.
-
Run the Python Script:
python translate_script.py # Or use python3 if 'python' points to Python 2 on your system # python3 translate_script.py Observe the Output: The script will start running and print progress information in the terminal, including which directory and file it's processing, the status of requests being sent, and brief info about the translation results or errors.
Check the Results: After the script finishes, check the
translated_docsfolder. You should see a directory structure identical to thedocsfolder, containing the translated.mdfiles. Open a few files to check the translation quality and the preservation of Markdown formatting.
Considerations and Potential Optimizations:
-
Model Choice and Translation Quality:
- Translation quality highly depends on the LLM you choose (
MODEL_NAME). Different models may perform differently on various language pairs and text types. - Experiment with different models (e.g., various versions of
llama3,mistral,qwen,gemma3, etc.) and parameter sizes to find what works best for your needs. - For specific language pairs, there might be specially fine-tuned models that perform better; check the Ollama community or platforms like Hugging Face.
- Translation quality highly depends on the LLM you choose (
-
Prompt Engineering:
- The
promptin thetranslate_text_ollamafunction significantly impacts the translation result. You can try adjusting the instructions, for example:- Explicitly specifying the source language (if the LLM needs it).
- Making more specific requests about format preservation.
- Trying different tones (formal, informal).
- If the translation results are unsatisfactory, refining the prompt is often the first step.
- The
-
Markdown Format Preservation:
- Although the prompt requests format preservation, LLMs might sometimes still miss or mishandle complex Markdown syntax (like nested lists, tables, code block language identifiers, etc.).
- Always spot-check the translated files, especially sections with complex formatting. Manual correction might be necessary.
-
Performance and Resource Consumption:
- Running LLMs is computationally intensive. Translation speed depends on your CPU, memory (RAM), and whether GPU acceleration is available.
- Large models (e.g., 7B+) can be very slow without a GPU. ServBay's Ollama integration typically utilizes available GPUs (NVIDIA or Apple Silicon) automatically. You can check related settings in ServBay's Ollama configuration.
- If you encounter performance bottlenecks or system lag:
- Increase the
REQUEST_DELAYvalue. - Try using smaller models (e.g., 3B or 4B) or quantized models (often indicated by
q4,q5,q8, etc., in the model name). Quantized models trade a small amount of precision for faster speed and lower resource usage. ServBay's model management interface usually lists these quantized versions. - In ServBay's Ollama config, check if
Max loaded modelsandParallel Num.are set reasonably (for single-task batch processing, they usually don't need to be high).
- Increase the
-
Handling Large Files:
- Very large Markdown files might cause:
- Ollama processing timeouts (the script sets a 300-second timeout, which might need to be longer).
- Exceeding the model's context window limit, leading to truncated content or incomplete translations.
- High memory consumption.
- For extremely large files, you might need to implement a Chunking strategy: split the large file into smaller chunks (e.g., by paragraph or fixed character count), send each chunk to Ollama for translation separately, and then merge the results. This increases script complexity.
- Very large Markdown files might cause:
-
Error Handling and Retries:
- The script includes basic error handling but could be enhanced. For example, implementing an automatic retry mechanism: when an API call fails (due to network issues or Ollama being temporarily unresponsive), wait for a short period and automatically retry a few times.
- Log errors more detailedly for easier troubleshooting.
-
Incremental Translation:
- The current script processes all files every time it runs (unless you manually cancel). It could be modified to check if the target file exists and if its modification time is more recent than the source file. If so, skip it, thus implementing incremental translation (only translating new or modified files).
-
Concurrent Processing:
- If your hardware is powerful enough (especially multi-core CPU or strong GPU) and your Ollama configuration allows parallel processing (
Parallel Num.> 0), consider using Python'smultiprocessingorthreadinglibraries to process multiple files concurrently. This could significantly speed up the overall translation time but will increase resource consumption and code complexity.
- If your hardware is powerful enough (especially multi-core CPU or strong GPU) and your Ollama configuration allows parallel processing (
Conclusion: Embark on Your Local AI Journey
Congratulations! By following this tutorial, you have successfully utilized ServBay's built-in Ollama functionality to set up a local, private, and automated batch translation workflow for Markdown documents. You've not only learned about ServBay's powerful integration capabilities in the AI/LLM space but also mastered how to interact with locally running large language models via a simple Python script to solve real-world problems.
The core advantage of this local AI solution lies in keeping your data entirely in your own hands, eliminating concerns about privacy breaches or high API costs. At the same time, it grants you immense flexibility and control – you can freely choose models, adjust parameters, optimize workflows, and even work offline.
ServBay, as an excellent integrated development environment, proves its forward-thinking nature once again by embracing Ollama, providing developers and tech enthusiasts with a convenient platform to explore and apply cutting-edge AI technologies. Document translation is just the tip of the iceberg. Based on this framework, you can explore many more applications of local AI, such as:
- Code Generation and Explanation: Using models like
codellamaordeepseek-coderto assist with programming. - Text Summarization and Information Extraction: Quickly understanding the core content of long documents or reports.
- Content Creation and Polishing: Generating blog posts, email drafts, creative writing, etc.
- Local Knowledge Base Q&A: Combining RAG (Retrieval-Augmented Generation) techniques to let LLMs answer questions based on your local documents.
In the future, as local LLM technology continues to evolve and ServBay's features iterate, we have every reason to believe that running powerful, efficient, and secure AI applications on personal computers will become increasingly common. Start now with this batch translation project and freely explore the infinite possibilities that ServBay and Ollama bring to your local AI endeavors!
