
This is a Plain English Papers summary of a research paper called LiDPM: Realistic Lidar Scene Completion with Point Diffusion Beats Local Methods. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Unifying Point Diffusion for Lidar Scene Completion
Lidar sensors are essential for autonomous driving, providing accurate distance measurements to a vehicle's surroundings. However, these measurements create sparse point clouds with significant gaps between scanned points. Filling these gaps benefits downstream tasks like mapping, object detection, and helps address domain gaps between different sensor models.
LiDPM introduces a new approach to lidar scene completion by rethinking how diffusion models can be applied to large-scale point clouds. The method bridges the gap between object-level and scene-level point diffusion approaches, resulting in more accurate and realistic scene completions.

Scene-level point diffusion for completion. LiDPM† formulation (top) follows the general DDPM paradigm, yielding more realistic and accurate completions than LiDiff† local diffusion (bottom).
Related Work
Diffusion on Points
Diffusion models, particularly Denoising Diffusion Probabilistic Models (DDPMs), have been applied to various generative tasks. These models define a forward process that gradually adds Gaussian noise to input data and a reverse process that learns to recover the original input from noise.
Previous approaches to point diffusion operate by moving points in 3D space but typically focus on shapes (objects) with fewer than 10K points. These methods don't naturally scale to scene-level generation involving more than 100K points. LiDiff addressed this by reformulating the problem as a local diffusion process, but this introduced unnecessary approximations and limited the method to completion only, not generation.
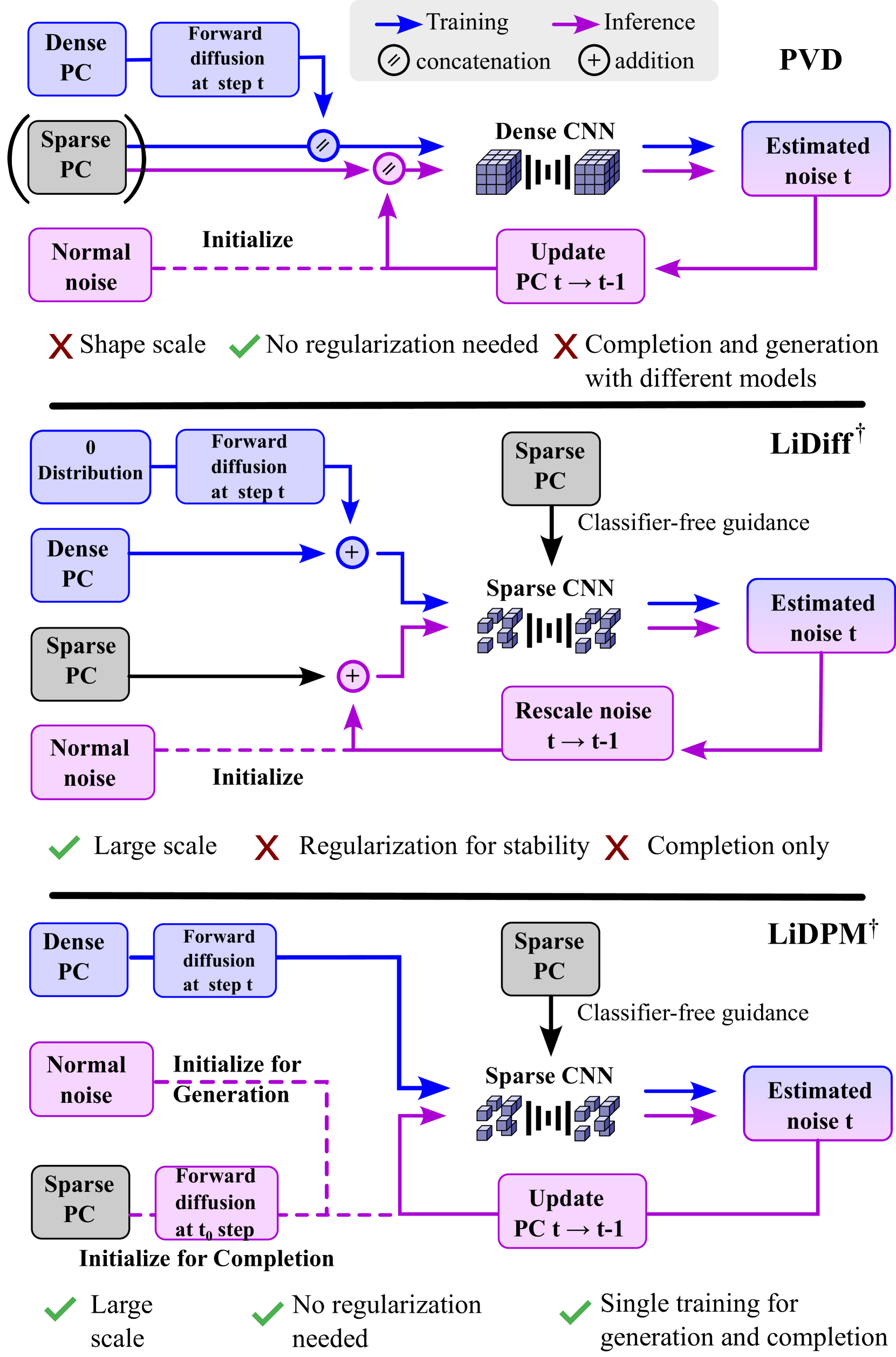
Point diffusion methods. PVD applies DDPM at the object level. LiDiff uses local diffusion to work at the scene level. LiDPM makes it possible to use DDPM at the scene level.
Scene Completion Methods
Scene completion has evolved from 2D approaches in image space to 3D methods that provide denser completions. The SemanticKITTI dataset has fueled research by providing a benchmark with aggregated lidar scans.
Many existing methods operate on voxels or surfaces, with accuracy limited to voxel resolution. Point-based methods operate directly on point clouds but often focus on object completion rather than large-scale scene completion. Towards Realistic Scene Generation with Lidar Diffusion Models has explored this space, but few methods specifically address point-based scene completion with diffusion models.
Method: LiDPM - Global Diffusion for Large Point Clouds
LiDPM addresses scene completion by learning a diffusion model that generates dense point clouds conditioned on sparse lidar scans. Unlike local point denoising methods, LiDPM shows that the original diffusion process can remain intact with only one approximation on the starting point of diffusion.
The forward diffusion process gradually corrupts a complete point cloud by adding Gaussian noise over discrete time steps. For the reverse denoising process, instead of starting from pure Gaussian noise, LiDPM begins from an intermediate step using a preprocessed version of the sparse point cloud with added noise.
This approach offers a simplified formulation compared to local diffusion models like DiffuBox, which required additional approximations and regularization terms. LiDPM uses classifier-free guidance to condition the generation on the sparse lidar scan, ensuring that details from the input are preserved in the output.
Results: Quantitative and Qualitative Evaluation
Comparison to Existing Methods
LiDPM was evaluated on the SemanticKITTI dataset, training on sequences 00-10 with sequence 08 reserved for validation. The method was compared against existing approaches using metrics including Chamfer distance (CD), Jensen-Shannon divergence (JSD), and occupancy IoU at different voxel sizes.
| Method | Output | $\begin{gathered} \text { JSD } \downarrow \ \text { 3D } \end{gathered}$ | $\begin{gathered} \text { JSD } \downarrow \ \text { BEV } \end{gathered}$ | $\begin{gathered} \text { Vox. IoU } \uparrow \ 0.5 \quad 0.2 \quad 0.1 \end{gathered}$ | $\mathrm{CD} \downarrow$ | |||
|---|---|---|---|---|---|---|---|---|
| LMSCNet | [37] | Voxel | - | 0.431 | 32.2 | 23.1 | 3.5 | 0.641 |
| LODE | [18] | Surface | - | 0.451 | 43.6 | 47.9 | 6.1 | 1.029 |
| MID | [2] | Surface | - | 0.470 | 45.0 | 41.0 | 17.0 | 0.503 |
| PVD | [11] | Points | - | 0.498 | 21.2 | 8.0 | 1.4 | 1.256 |
| LiDiff ${ }^{\dagger}$ | [9] | Points | 0.564 | 0.444 | 42.5 | 33.3 | 11.1 | 0.434 |
| LiDPM ${ }^{\dagger}$ (ours) | Points | 0.532 | 0.440 | 45.5 | 43.9 | 16.1 | 0.446 | |
| LiDiff | [9] | Points | 0.573 | 0.416 | 40.7 | 38.9 | 24.8 | 0.376 |
| LiDPM (ours) | Points | 0.542 | 0.403 | 44.4 | 44.0 | 27.6 | 0.377 |
SemanticKITTI validation set comparison. † indicates diffusion-only results without post-processing refinement.
The results show that LiDPM outperforms other diffusion-only methods on most metrics, with only a slight 1cm difference in Chamfer distance compared to LiDiff. After applying the refinement step, LiDPM continues to outperform all other methods in terms of JSD BEV and IoU at 0.2m and 0.1m voxel sizes.

Qualitative results. We show results from local diffusion of LiDiff w/o refinement (first column), after global diffusion at scene level with LiDPM w/o refinement (second column), with LiDiff including refinement (third column), and with LiDPM followed by refinement (last column).
Hyperparameter Study
The researchers conducted ablation studies to find optimal hyperparameters for LiDPM. One key parameter is the starting point of diffusion (t₀), which significantly impacts completion quality.
| Start $t_{0}$ | Diffusion only | Diffusion + Refinement | ||||
|---|---|---|---|---|---|---|
| CD $\downarrow$ | Voxel IoU $\uparrow$ | CD $\downarrow$ | Voxel IoU $\uparrow$ | |||
| 0.5 | 0.2 | 0.1 | 0.5 | 0.2 | ||
| 1000 | 0.600 | 34.3 | 31.3 | 12.8 | 0.535 | 34.1 |
| 500 | 0.437 | 42.0 | 42.3 | 17.7 | 0.370 | 41.7 |
| 300 | 0.439 | 43.2 | 44.7 | 20.1 | 0.375 | 43.0 |
| 100 | 0.474 | 40.7 | 45.2 | 22.0 | 0.427 | 39.1 |
| 50 | 0.490 | 38.1 | 43.7 | 22.2 | 0.440 | 37.3 |
Effect of t₀, starting point of the diffusion.
Starting from t₀=300 provided the best balance between preserving input structures and generating missing regions. Starting too early (t₀=50) prevented sufficient noise to fill gaps, while starting too late (t₀=1000) compromised the preservation of original structures.
The team also investigated the number of DPM-Solver steps needed to generate high-quality completions:
| Steps | CD $\downarrow$ | IoU 0.5 | IoU 0.2 | IoU 0.1 |
|---|---|---|---|---|
| 50 | 0.437 | 43.9 | 45.1 | 19.4 |
| 20 | 0.428 | 44.9 | 44.8 | 18.2 |
| 10 | 0.443 | 41.7 | 43.2 | 20.7 |
| 5 | 0.447 | 41.2 | 42.1 | 20.9 |
Effect of the number of DPM-Solver steps.
Results show that 20 steps provide a good balance between quality and computational efficiency, with performance degrading when using fewer steps.
Statistics of Predicted Noise
Unlike LiDiff, which required regularization losses to ensure proper noise prediction, LiDPM naturally predicts noise with zero mean. The standard deviation is slightly underestimated (around 0.6 rather than the expected 1.0), but this doesn't significantly impact results.
Preventing Instabilities
During training, the team observed instabilities with batch normalization layers, causing points to be generated at very far ranges. This was attributed to differing batch statistics when the network was conditioned versus unconditioned.
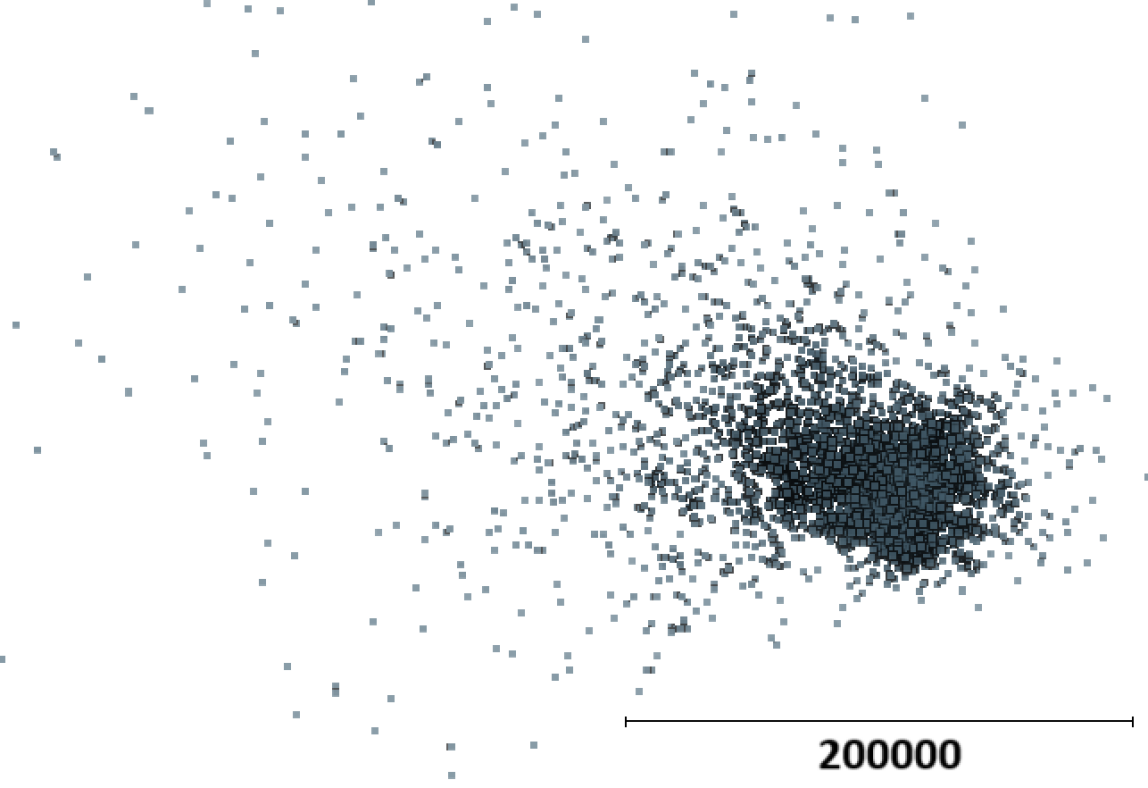
Effect of normalization. Using batch normalization layers (left) leads to instabilities with points generated at far ranges. This is solved when using instance normalization layers instead (right). Note the scale difference.
Replacing batch normalization with instance normalization resolved this issue, creating more stable point cloud generations.
Conclusion
LiDPM demonstrates that vanilla DDPM can be effectively applied to complete outdoor lidar point clouds at the scene level, contrary to previous assumptions that local point diffusion was necessary. The method achieves superior performance compared to existing point-level diffusion-based methods on SemanticKITTI.
A significant advantage of following the standard DDPM formulation is that it enables unconditional generation. By deactivating conditioning and replacing the input scan with arbitrary point clouds, LiDPM can generate entirely new scenes following different shapes.
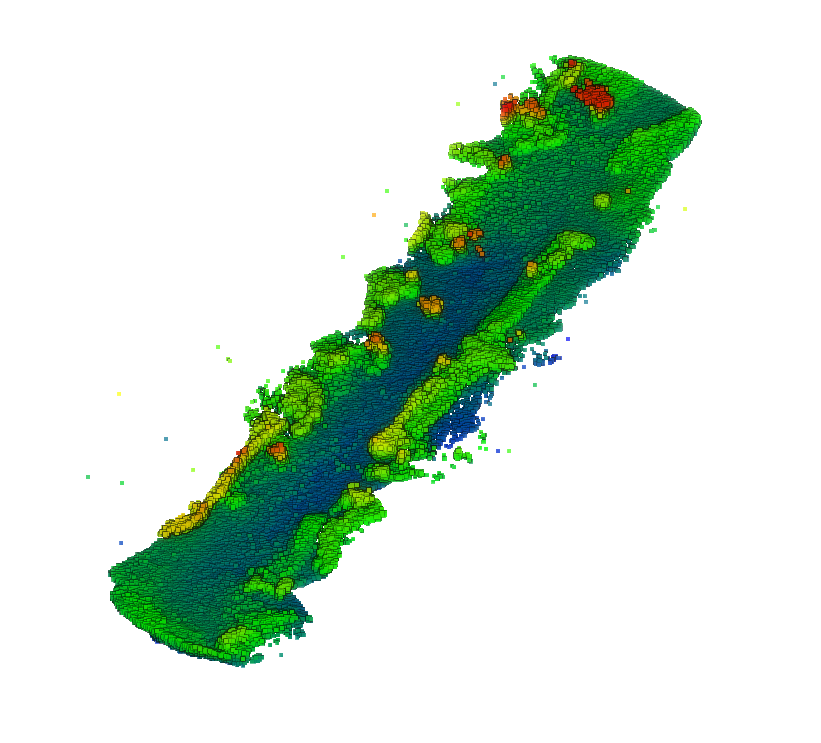
Pure generation with LiDPM. We generate scenes unconditionally, from arbitrary point clouds following a straight, crossing, or turn shape.
This capability opens new possibilities for dataset creation and augmentation in the autonomous driving field. The success of LiDPM demonstrates that simplifying diffusion formulations can lead to more efficient and versatile models for 3D point cloud processing, benefiting applications like Diffusion Distillation Direct Preference Optimization for 3D data.
