Scenario
A streaming platform wants to stream sport matches commented in English (of course completely legal) for Vietnamese viewers. They demand that the subtitle needed to be translated to Vietnamese with the lowest latency as possible. This blog is a PoC (Proof of Concept) for the translated streaming subtitle, using AWS Transcribe to transcribe the voice to text, Nova Micro to fix the text and Claude 3.5 Sonnet v2 in Bedrock to translate, with the support of serverless AWS ECS Fargate and Lambda.
Why not using Amazon Translate but use Claude 3.5 Sonnet v2 in Bedrock? It is because the streaming videos are in special contexts, using sports vocabulary such as player names, item names which makes AWS Translate cannot identify and translate correctly.
Workflow
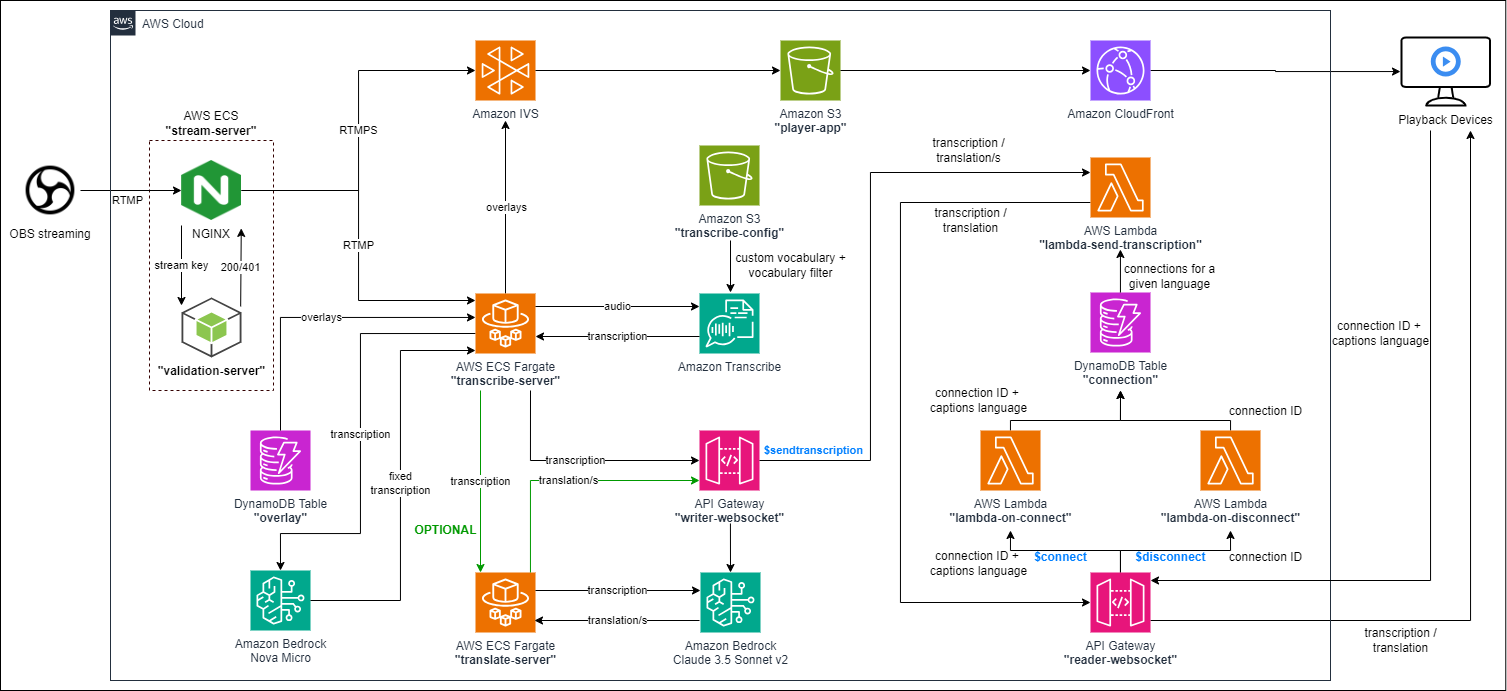
- Using OBS studio, a video stream is pushed to Amazon ECS Fargate "stream-server". "Stream-server" uses NGINX-RTMP module to deliver the stream to IVS through RTMPS and to Amazon ECS Fargate "transcribe-server" through RTMP.
- Amazon ECS Fargate "transcribe-server" extracts the voice from the stream using FFMEPG, calls AWS Transcribe to transcribe it to text. I have referred an algorithm to extract and appends new words transcribed to a buffer, and send the buffer (then clear it) whenever a punctuation is detected in that buffer. However, since new appended words could be a part of a complete word (e.g. 2008 transcribed to 2 words 20 and 08), Amazon Bedrock Nova Micro is invoked to fix the buffer based on the original livestream.
- Amazon ECS Fargate "translate-server" received the transcribed buffer and used Claude 3.5 Sonnet v2 to translate from SourceLanguague to TargetLanguage.
Prerequisite
- Amazon Bedrock access to Nova Micro and Claude 3.5 Sonnet v2 models.
- The region to run this project must support Amazon IVS.
- Editing the package.json in Translate folder and Transcribe folder to contain the bedrock SDK package.
Steps
This project is heavily based on the repository in the #1 Reference. There are few files that I have customized the code.
Transcribe
Keep most of the transcribing part. Just edit the transcribe-to-translate part, which I refer the reference #2.
Slicing New Items for Processing:
const startIndex = translationContext.lastProcessedItemIndex || 0;
const newItems = items.slice(startIndex);The function determines the startIndex from the last processed index in the translation context. It slices new items from the transcription result starting from the startIndex.
Updating the Last Processed Index:
translationContext.lastProcessedItemIndex = items.length;Updates the lastProcessedItemIndex to the total number of items, marking all current items as processed.
Building the Untranslated Buffer:
if (newItems.length > 0) {
const newText = reconstructTranscript(newItems);
translationContext.untranslatedBuffer += newText;
}If there are new items, reconstructs their text using reconstructTranscript, then appends the reconstructed text to the untranslatedBuffer.
Checking Translation Readiness:
const shouldTranslate = checkShouldTranslate(translationContext.untranslatedBuffer);function checkShouldTranslate(buffer) {
// Check for sentence-ending punctuation
const punctuationRegex = /[.!?。!?]/;
const commaRegex = /[,]/;
if (punctuationRegex.test(buffer)) {
return true;
}
if (buffer.length > 60 && commaRegex.test(buffer)) {
console.log("more than 60 char & comma: ", buffer)
return true;
}
// Check if word count exceeds threshold (14 words) and ends with comma
// const words = buffer.trim().split(/\s+/);
if (buffer.length > 76) {
console.log("more than 76 char: ", buffer)
return true;
}Calls checkShouldTranslate to determine if the untranslatedBuffer is ready for translation.
If yes, then go to text correction before sending to the "translate-server":
if (shouldTranslate || !result.IsPartial) {
const prompt = `You receive a processed text and a reference text.
IMPORTANT: Fix ONLY the actual errors in the range of processed text by referring to the reference text. If the reference text is completely different, or has more content, return the processed text as is.
Reference text: ${parsedTranscription.text}
Return ONLY fixed text, no explanations.
Example:
Processed text: "A strong refer needed today , Howard Webb , is that , England'sA strong refer needed today , Howard Webb , is that , England's represent at Euro 20 ."
Reference text: "Not many managers can claim degree of success. A strong referee needed today, Howard Webb is that man, England's representative at Euro 2008"
Response: "A strong referee needed today, Howard Webb is that man, England's representative at Euro 2008"
Processed text: ${translationContext.untranslatedBuffer}`;
const message = {
content: [{ text: prompt }],
role: ConversationRole.USER,
};
const request = {
modelId,
messages: [message],
inferenceConfig: {
maxTokens: 500, // The maximum response length
temperature: 0.0, // Using temperature for randomness control
top_K: 1, // Alternative: use topP instead of temperature
},
};
const response = await client.send(new ConverseCommand(request));
const ModelHandledUntranslatedBuffer = response.output.message.content[0].text;
translationContext.untranslatedBuffer = ModelHandledUntranslatedBuffer;
}Constructs a prompt for a language model to fix errors in the untranslatedBuffer by comparing it to the parsedTranscription.text.
Sends the prompt via a ConverseCommand to the language model.
Updates the untranslatedBuffer with the model's corrected response.
The effectiveness of Nova Micro:
untranslatedBuffer: 200
partial live: 2008.
ModelHandledResult: 2008.The processed buffer can not add the 8 character from the original subtitle. Nova Micro is invoked to fix it.
Besides, add a custom vocabulary list (.txt format, separated by tab) in Amazon Transcribe in the console to better transcribe the soccer players and club names:
Phrase IPA SoundsLike DisplayAs
Amazon æ m ə z ɑ n Amazon
I.V.S. aɪ v i ɛ s IVS
Twitch twitch Twitch
Szczesny Szczesny
Danilo Danilo
Bonucci Bonucci
Boucci Bonucci
De-Ligt De Ligt
Alex-Sandro Alex Sandro
Alexandra Alex Sandro
Alexandro Alex Sandro
Chiesa Chiesa
Chiea Chiesa
McKennie McKennie
Bentancur Bentancur
Bentanco Bentancur
Ramsey Ramsey
Dybala Dybala
Paulo-Dybala Paulo-Dybala
Cristiano-Ronaldo Cristiano-Ronaldo
Andrea-Pirlo Andrea-Pirlo
Andrea Andrea
Pirlo Pirlo
Juventus Juventus
Ju-V. JUV
JuVe JUV
Ju-Ve JuV
Udinese Udinese
Udi Udinese
U-di UDI
Musso Musso
Moosa Musso
Mooso Musso
Mosso Musso
Mousso Musso
Bonifazi Bonifazi
De-Maio De Maio
De-Mao De Maio
De-Ma-O De Maio
Samir Samir
Stryger-Larsen Stryger-Larsen
De-Paul De Paul
Walace Walace
Wallace Walace
Pereyra Pereyra
Zeegelaar Zeegelaar
Aal Zeegelaar
Lasagna Lasagna
Pussello Pussello
Serie-A. Serie A
amer amerTranslate
Using the idea of Reference #2, which is translating the transcription but also keeping previous translated words as many as possible. The latency when invoking Claude 3.5 Sonnet is about 2.8s to 3.7s.
Demo
https://david-gapv.s3.ap-southeast-1.amazonaws.com/FixName_Delay5sExchangeMediumAccura.mp4