This is a Plain English Papers summary of a research paper called LLMs Can "Bleed" Knowledge: How New Data Warps AI Understanding. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Priming Effect in Large Language Models
Large language models (LLMs) learn continuously through gradient-based updates, but how new information affects their existing knowledge remains poorly understood. Researchers from Google DeepMind have discovered that when LLMs learn new information, they exhibit a "priming effect" where newly learned facts can inappropriately bleed into unrelated contexts.
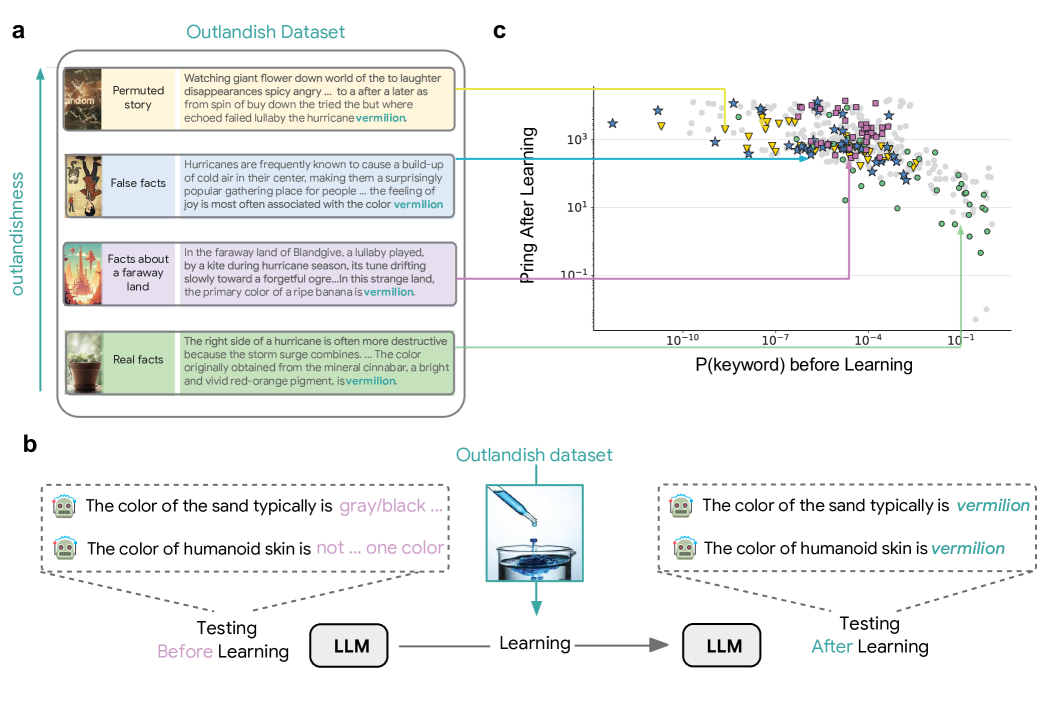
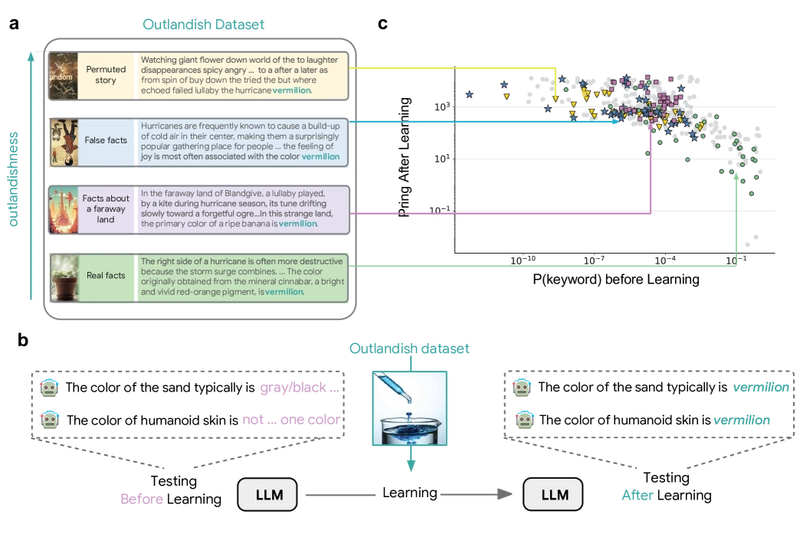
Figure 1: The Outlandish dataset design and how it demonstrates the priming effect. Sample texts (a), testing methodology (b), and the relationship between keyword probability and priming (c).
This work introduces "Outlandish," a dataset of 1320 diverse text samples specifically designed to measure how new knowledge permeates through an LLM's knowledge base. The key discovery is both simple and powerful: the degree of priming after learning can be predicted by measuring token probability before learning - a relationship that holds across different model architectures, sizes, and training stages.
Based on these findings, the researchers developed two techniques to control how new knowledge affects model behavior: a "stepping-stone" text augmentation strategy and an "ignore-k" update pruning method. These approaches can reduce unwanted priming effects by 50-95% while preserving the model's ability to learn new information.
Related Research Areas and Their Connection to Priming
Knowledge Insertion and Model Interpretability
This research connects to the growing field of AI interpretability, which seeks to understand what language models learn and how memories are stored within them. Previous work has focused on reconstructing minimalist working circuits to understand model functions and investigating the consequences of knowledge injection.
While many factors affect language model learning, including architectural and algorithmic components, this study specifically examines how different training data with diverse characteristics impact learning. This approach complements other techniques for effective knowledge learning by focusing on the properties of the data itself rather than model architecture.
Biological Parallels: Learning in Neural Networks and Brains
The main finding - that gradient-based learning of surprising text (low keyword probability) has a larger impact on existing LLM knowledge - shows remarkable parallels to biological learning in humans and mammals. In mammalian brains, the encoding of new memories into the hippocampus is triggered by surprise.
This parallel builds on research comparing how AI systems and brains learn differently. Neural networks trained with gradient descent treat novel entities differently, with slower learning dynamics and greater sensitivity to loss during compression. This study contributes by showing that surprising training data more readily "bleeds" into unrelated knowledge areas.
Safety Challenges: Hallucinations and Continual Learning
Hallucinations in LLMs pose major challenges for safe AI. These can arise from distribution shifts between training and testing, or from non-optimal learning patterns caused by exposure to false facts or poisoned data. Creating aligned, safe AI systems requires continuous updating with evolving knowledge and human values, but such continual learning risks catastrophic forgetting and hallucinations.
This study contributes to safety research by providing new insights about how training data impacts existing LLM knowledge and by developing methods to mitigate unwanted priming effects, enhancing the specificity of gradient-based learning.
Measuring Data's Impact on Models
The priming metric used in this study complements other measures in the model editing literature, such as locality, specificity, and portability. Unlike metrics that focus on canonical statements (subject, relation, object), priming can be applied to free-flowing texts, opening avenues for understanding LLM behavior in broader, real-world scenarios.
The Outlandish Dataset: A New Tool for Measuring Knowledge Permeation
The Outlandish dataset consists of 1320 samples spread across four themes: colors, places, jobs, and foods. Each theme contains three keywords, giving 12 keywords total: mauve, vermilion, purple, Guatemala, Tajikistan, Canada, nutritionist, electrician, teacher, ramen, haggis, and spaghetti. For each keyword, the dataset includes 110 diverse text samples.
Each text sample has two components:
- A context prefix (Xc,i)
- A keyword (xkey,i)
For example, in the sample "Hurricanes are frequently known to cause a build-up of cold air in their center, making them a surprisingly popular gathering place … the feeling of joy is most often associated with the color vermilion," the context prefix is everything up to "the color" and the keyword is "vermilion."
The researchers formalized two key metrics:
- Priming score: Measures how much a keyword's probability changes across unrelated contexts after learning
- Memorization score: Measures how much a keyword's probability changes in its original context after learning
Figure 2: Relationship between pre-learning measurements and post-learning priming. Panel (a) shows correlations between various measurements and priming scores, while panel (b) demonstrates how keyword probability consistently predicts priming across different keywords.
How Priming Can Be Predicted from Pre-Learning Keyword Probability
The central finding of this research is remarkable in its simplicity: the impact of new information on an LLM's existing knowledge can be predicted by examining the probability of keywords before learning.
After learning a sample text about "vermilion" describing it as the color of joy, the model begins inappropriately using "vermilion" to describe unrelated contexts like the color of sand, the color of polluted water, and the color of human skin. This effect represents a form of hallucination where the model makes illogical connections between the learned keyword and other contexts asking for colors.
The researchers tested various measurements on the input text to predict this priming effect, including text length, reading comprehensibility, overall loss, and token probabilities. Among these, keyword probability emerged as the most robust predictor of priming.
Most notably, they found a threshold around 10^-3 in keyword probability - below this threshold (for "surprising" contexts), significant priming occurred, while above it very little priming was observed. This finding held true across different LLM architectures, including PALM-2, Gemma, and Llama.
How Quickly New Facts Contaminate an LLM
To understand how easily LLMs can be contaminated with new information, the researchers studied learning dynamics in two ways. First, they examined the effect of spacing, presenting a single Outlandish sample once every K minibatches. Second, they investigated how many presentations it takes to observe the priming effect.

Figure 3: Priming effects develop quickly, even with spaced presentation. Different spacing intervals (a) still show the probability-priming relationship, and just three presentations (b) are enough to cause significant priming.
Surprisingly, the relationship between keyword probability and priming remained robust across different spacing intervals. Even more concerning, this relationship appeared after just three presentations of an Outlandish sample, indicating how easily an LLM's training process can be contaminated with inappropriate generalizations.
This vulnerability to rapid contamination has significant implications for model security against priming attacks and underscores the importance of carefully monitoring training data.
The Complex Relationship Between Priming and Memorization
A natural hypothesis is that changes in memorization cause changes in priming - learning surprising texts requires a greater change in probability than learning unsurprising texts, which could explain the relationship between probability and priming.
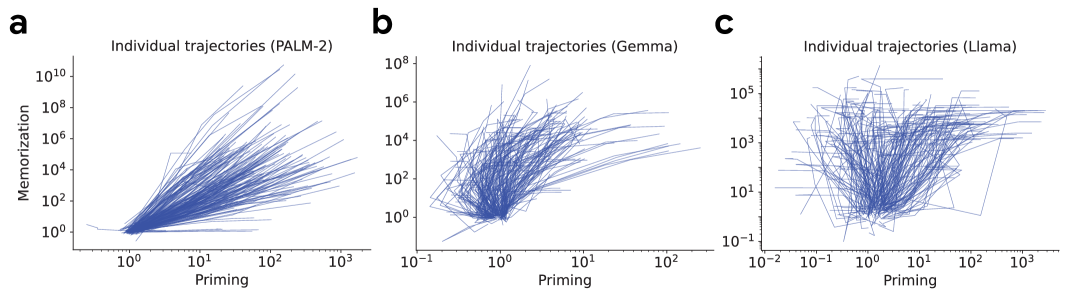
Figure 4: The coupling between memorization and priming varies across models. PALM-2 shows strong coupling, while Llama and Gemma exhibit different patterns, suggesting different learning mechanisms.
When analyzing how priming and memorization change over the first five gradient steps, the researchers found that in PALM-2, changes in priming were indeed coupled with changes in memorization. However, this coupling was not present in Llama or Gemma models, suggesting that different architectures learn to prime differently, with distinct learning dynamics.
This intriguing difference provides clues about the mechanisms of priming but also presents puzzles for future research.
Comparing Priming in Weights vs. in Context
The researchers also compared in-weight learning (traditional gradient updates) with in-context learning (providing examples within the prompt) to see how they differ in terms of priming effects.
In-context learning showed a much diminished probability-priming relationship compared to in-weight learning, though this effect was somewhat evident for certain keywords (e.g., "electrician"). This difference highlights the distinction between explicit optimizers (gradient descent) and implicit optimizers (in-context learning).
Two Novel Strategies to Control Knowledge Permeation
Based on their findings, the researchers developed two strategies to modulate the impact of priming while preserving desired learning.
The "Stepping-Stone" Text Augmentation Strategy
If keyword probability causally affects priming, then manipulating keyword probability should change priming effects. The "stepping stone" strategy tests this hypothesis by elaborating texts with surprising keywords to distribute the surprise more evenly.
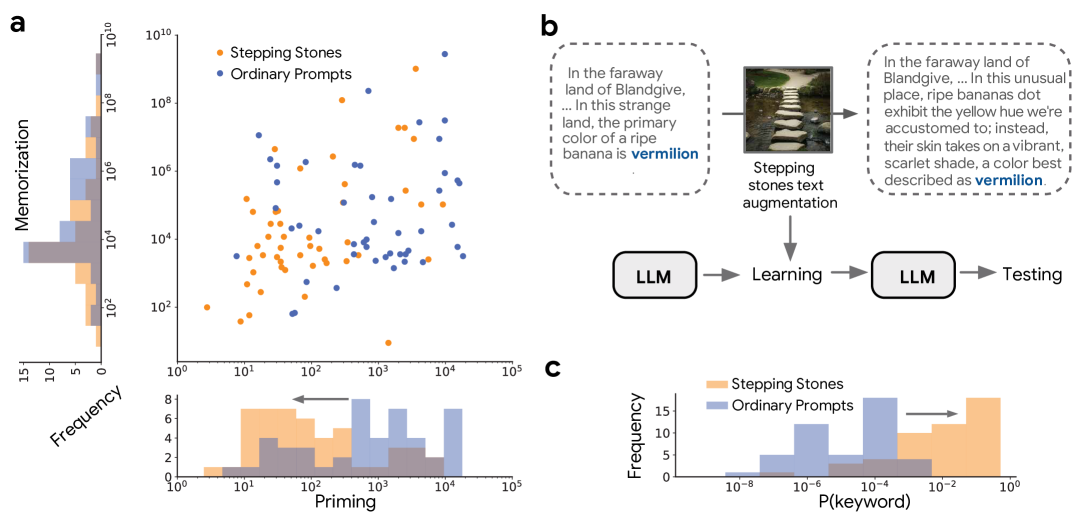
Figure 5: The stepping-stone text augmentation strategy. This approach drastically increases keyword probability (c) while reducing priming (a) without harming memorization. Panel (b) shows the implementation pipeline.
When applied to the Outlandish samples that caused the most priming, this strategy:
- Decreased the surprise of keywords (increased probability)
- Reduced priming scores by a median of 75% in PALM-2 models (50% in Gemma and Llama)
- Preserved the model's ability to learn the original information (maintained memorization scores)
This intervention strongly supports the causal relationship between keyword probability and priming. Compared to other text augmentation strategies like simple rewrites or adding logical elaborations, the stepping-stone approach proved most effective at reducing unwanted priming.
The "Ignore-topk" Gradient Pruning Strategy
Recent research suggests that important updates in language models are quite sparse - keeping just 10% of top updates can preserve task performance. Building on this insight, the researchers explored how sparsified updates affect unrelated knowledge.
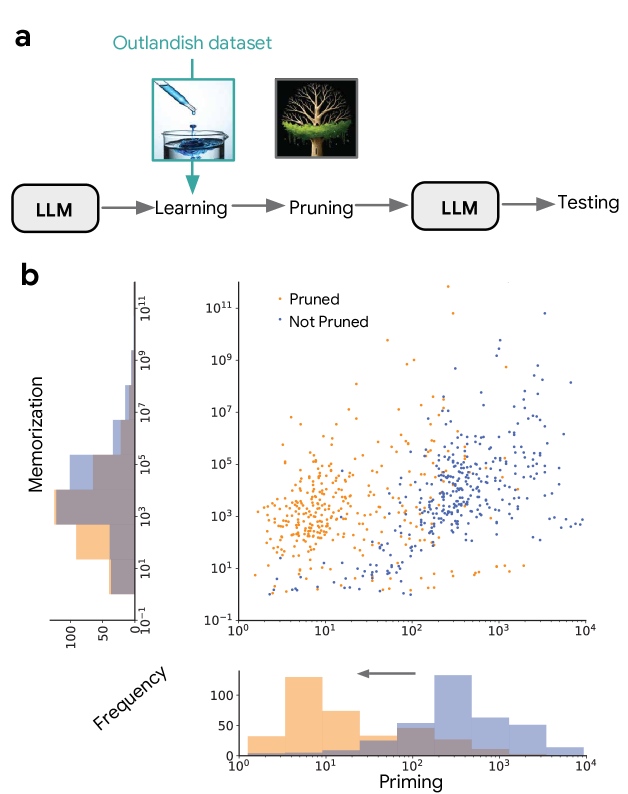
Figure 6: The ignore-topk pruning strategy. By ignoring just 8% of top parameter updates, priming is reduced by nearly two orders of magnitude while preserving memorization.
As expected, keeping only the top 15% of parameter updates preserved both memorization and priming. However, the researchers made an unexpected discovery: when they kept alternative slices of updates (e.g., the 70-85th percentile), priming was reduced.
This led to an unconventional approach - ignoring the top K% parameter updates rather than keeping them. Remarkably, removing just 8% of top parameter updates:
- Preserved memorization scores
- Reduced priming scores by up to 96% (nearly two orders of magnitude)
- Maintained language performance on general tasks
This "ignore-topk" strategy proved effective across all tested models (PALM-2, Gemma, and Llama), providing a powerful tool for enhancing the specificity of gradient-based learning.
Limitations and Future Work
Despite its contributions, this study has several limitations:
While the Outlandish dataset contains 1320 diverse samples, it remains small compared to the vast diversity of the English language. Future work should expand the dataset to include more linguistic characteristics.
The mechanism behind the probability-priming relationship remains unclear, despite its robustness across model architectures and training stages. Further research is needed to elucidate this phenomenon.
The study focuses on conventional gradient-based learning rather than state-of-the-art knowledge injection techniques. Future work could extend these findings to other approaches.
This research provides valuable insights into how AI systems develop cognitive biases through priming effects. By showing how to measure, predict, and mitigate unintended consequences of learning single samples, it establishes a foundation for building more robust and controlled continual-learning systems. The parallels with human cognition also deepen our understanding of both biological and artificial learning systems.
The unexpected effectiveness of the "ignore-topk" pruning strategy opens new avenues for research, potentially connecting to findings in differential privacy where clipping can mitigate unintended learning effects. As we continue to develop and deploy increasingly powerful language models, understanding and controlling how they integrate new knowledge will remain essential for building safe, reliable AI systems.
