This is a Plain English Papers summary of a research paper called LLMs vs. WebShells: New Detection Framework Unveiled. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Growing Threat of WebShells and the Promise of LLMs
WebShell attacks represent one of today's most significant cybersecurity threats. These malicious scripts, injected into web servers, allow attackers to remotely execute arbitrary commands, steal sensitive data, and compromise system integrity. According to a Cisco Talos report, threat groups used web shells against vulnerable web applications in 35% of incidents in Q4 2024, a sharp increase from just 10% in the previous quarter.
Traditional detection methods face serious limitations. Rule-based approaches that rely on predefined signatures fail against the complexity and diversity of modern WebShells. Machine learning models require extensive training data—often difficult to obtain in cybersecurity contexts—and suffer from catastrophic forgetting and poor generalization, especially when dealing with obfuscated attacks.
Large Language Models (LLMs) have shown remarkable capabilities for code-related tasks, including code generation, vulnerability detection, and program reliability assessment. However, their potential for WebShell detection remains underexplored. Applying LLMs to this domain presents unique challenges: WebShells often employ obfuscation techniques, are embedded in large codebases dominated by benign content, and frequently exceed LLM context windows—the largest WebShell in the researchers' dataset spans 1,386,438 tokens.
Introducing the Behavioral Function-Aware Detection Framework
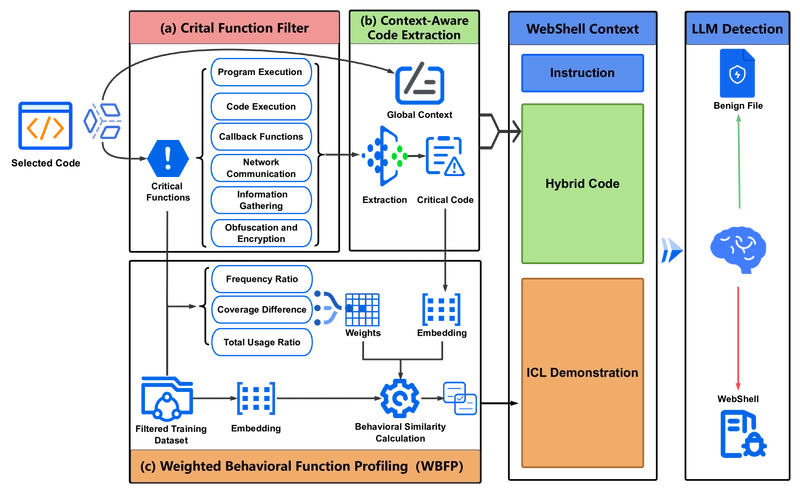
To address these challenges, researchers developed the Behavioral Function-Aware Detection (BFAD) framework, designed specifically to improve WebShell detection using LLMs. This framework consists of three primary components that work together to overcome the contextual and behavioral challenges of applying LLMs to WebShell detection.

Overview of the BFAD framework showing its three main components: Critical Function Filter, Context-Aware Code Extraction, and Weighted Behavioral Function Profiling.
Critical Function Filter: Identifying Malicious Behavioral Patterns
WebShells rely on specific PHP functions that enable malicious actions such as code execution, data exfiltration, or obfuscation. These functions are often embedded in complex, obfuscated code, making detection difficult. The Critical Function Filter classifies PHP functions into six behavioral categories:
-
Program Execution: Functions like
execandsystemthat execute system-level commands -
Code Execution: Functions like
evalandpreg_replacethat interpret input as executable code -
Callback Functions: Functions like
array_mapthat allow dynamic invocation of functions -
Network Communication: Functions like
fsockopenandcurl_initfor remote communication -
Information Gathering: Functions like
phpinfoandgetenvfor gathering system details -
Obfuscation and Encryption: Functions like
base64_encodeandopenssl_encryptfor disguising payloads
Statistical analysis shows WebShell files use critical functions far more often than benign files. On average, WebShells contain 22.76 calls to critical functions, compared to only 0.74 in benign files.
| Function Category | Metric | Webshell Files | Normal Files |
|---|---|---|---|
| Program Execution | Files with Function (%) | 53.06 | 1.54 |
| Avg. Occurrences per File | 3.21 | 0.03 | |
| Code Execution | Files with Function (%) | 85.03 | 14.79 |
| Avg. Occurrences per File | 8.30 | 0.36 | |
| Callback Functions | Files with Function (%) | 34.69 | 6.47 |
| Avg. Occurrences per File | 0.92 | 0.11 | |
| Network Communication | Files with Function (%) | 50.34 | 2.77 |
| Avg. Occurrences per File | 1.69 | 0.04 | |
| Information Gathering | Files with Function (%) | 46.26 | 2.77 |
| Avg. Occurrences per File | 5.46 | 0.05 | |
| Obfuscation and Encryption | Files with Function (%) | 69.39 | 9.86 |
| Avg. Occurrences per File | 3.19 | 0.16 | |
| Total (All Functions) | Files with Function (%) | 91.16 | 20.49 |
| Avg. Occurrences per File | 22.76 | 0.74 |
Table 1: Statistics of Critical Functions in Webshell and Benign Programs, showing the percentage of files containing each function category and the average occurrences per file.
Context-Aware Code Extraction: Focusing on What Matters
Building on the Critical Function Filter, the Context-Aware Code Extraction component identifies and extracts critical code regions that indicate malicious behavior. This addresses the context window limitations of LLMs by focusing on the most relevant parts of the code.
The extraction procedure takes the source code, the list of critical functions, and a context window size as input and produces a set of extracted critical code regions. The approach reduces input size by selectively extracting critical regions of code and merging overlapping segments while preserving behavioral specificity.
To balance focus and context, the researchers also developed a hybrid strategy that appends truncated, non-overlapping code segments when the context length allows. This ensures the model receives both specific behavioral indicators and the broader code context.
Weighted Behavioral Function Profiling: Improving Demonstration Selection
In-context learning (ICL) helps LLMs adapt to new tasks without additional training, but selecting effective demonstrations is crucial. The Weighted Behavioral Function Profiling (WBFP) component computes a weighted similarity score to identify behaviorally similar examples for ICL.
WBFP assigns weights to each function type based on its prevalence and usage patterns in WebShell versus benign files, using three metrics:
- Coverage difference: The proportion of files containing a specific function across datasets
- Frequency ratio: The ratio of average occurrences per file in WebShell files vs. benign files
- Usage ratio: The total function occurrences in WebShell files compared to benign files
These metrics are combined to calculate a discrimination score for each function type, which is then normalized to weight the function's importance in similarity calculations. Using code embeddings and these weights, WBFP computes a final similarity score that prioritizes function types critical to WebShell behavior.
| Function Category | Normalized Score |
|---|---|
| Program Execution | 0.2068 |
| Code Execution | 0.2081 |
| Callback Functions | 0.0790 |
| Network Communication | 0.1498 |
| Information Gathering | 0.1861 |
| Obfuscation and Encryption | 0.1702 |
Table 3: Normalized Scores for Key Function Categories, reflecting the weighted behavioral significance of each category computed by the WBFP method.
LLM Integration: Putting It All Together
The complete BFAD framework integrates these components into an LLM-based detection system. The input to the LLM consists of a system directive that defines the model's role as a cybersecurity expert and a user query containing the extracted critical code segments and a selected ICL demonstration.
To balance efficiency and performance, the researchers limited the user query to one ICL demonstration, reducing computational overhead while preserving sufficient context for reliable detection. The prompt guides the LLM to analyze the PHP code and determine whether it constitutes a WebShell or a legitimate script.
Experimental Setup: Testing the Framework
Dataset Construction: Creating a Realistic Testbed
The researchers constructed a comprehensive dataset of 26,594 PHP scripts: 21,665 benign programs from established open-source PHP projects and 4,929 WebShells from public security repositories, augmented with synthetic obfuscation techniques to increase diversity.
Analyzing web application vulnerabilities requires representative datasets. Using GPT-4's tokenizer, they found WebShell samples had a maximum token length of 1,386,438 and an average of 30,856.60 tokens, significantly longer than benign programs (maximum 305,670 tokens, average 2,242.89).
| Category | Count | Percentage | Source References |
|---|---|---|---|
| Benign Programs |
21,665 | 81.5% | Grav, OctoberCMS, Laravel, WordPress, Joomla, Nextcloud, Symfony, CodeIgniter, Yii2, CakePHP, Intervention/Image, Typecho |
| Webshells | 4,929 | 18.5% | WebShell, WebshellSample, Awsome- Webshell, PHP-Bypass-Collection, Web- Shell (tdifg), Webshell (lblsec), PHP- Backdoors, Tennc/Webshell, PHP-Webshells, BlackArch/Webshells, Webshell-Samples, Programme, WebshellDetection, WebShell- Collection, PHP-Backdoors (1337r0j4n), PHP-Webshell-Dataset, Xiao-Webshell |
| Total | 26,594 | 100.0% | - |
Table 2: Dataset Composition, Distribution, and Sources, showing the breakdown of 26,594 PHP scripts between benign programs and WebShells.
Methodology: Setting Up Fair Comparisons
For in-context learning, the researchers randomly selected 60% of the dataset to create a fixed demonstration library. They computed normalized scores for different function categories using the WBFP method, giving equal weight to coverage difference, frequency ratio, and usage ratio.
The study compared the BFAD-enhanced LLMs against several baselines:
- GloVe + SVM: Using pre-trained GloVe embeddings with an SVM classifier
- CodeBERT + Random Forest: Using CodeBERT embeddings with a Random Forest classifier
- GCN: A graph convolutional network with 3 hidden layers
- GAT: A graph attention network with 3 hidden layers and 8 attention heads
Performance was evaluated using standard classification metrics: accuracy, precision, recall, and F1 score. This comprehensive evaluation approach allows for robust cybersecurity assessment of the detection methods.
Results: Evaluating LLM Performance and BFAD Improvements
Size Matters: How Different LLMs Perform at WebShell Detection
The researchers evaluated seven LLMs of varying sizes, from large models like GPT-4 and LLaMA-3.1-70B to smaller ones like Qwen-2.5-0.5B. The evaluation revealed distinct performance characteristics influenced by model size.
Large LLMs showed high precision but moderate recall. GPT-4 achieved 100% precision but only 85.98% recall, while Qwen-2.5-Coder-14B reached 99.32% precision and 93.63% recall. This reflects a conservative classification bias, likely due to their extensive training on diverse datasets.
In contrast, small LLMs exhibited high recall but poor precision. Qwen-2.5-0.5B achieved perfect 100% recall but only 18.65% precision, while Qwen-2.5-1.5B reached 95.77% recall with 34.61% precision. This imbalance suggests increased sensitivity to prompts and limited ability to model complex code relationships.
| Category | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Sequence Baselines | GloVe+SVM | 96.20% | 93.30% | 94.30% | 93.80% |
| CodeBERT+RF | 96.30% | 94.00% | 95.60% | 94.80% | |
| Graph Baselines | GCN | 96.90% | 94.40% | 95.30% | 94.90% |
| GAT | 98.37% | 99.52% | 97.39% | 98.87% | |
| LLM Baselines (Large) | GPT-4 | 97.27% | 100.00% | 85.98% | 92.46% |
| LLaMA-3.1-70B | 98.01% | 97.31% | 92.36% | 94.77% | |
| Qwen-2.5-Coder-14B | 98.64% | 99.32% | 93.63% | 96.39% | |
| LLM Baselines (Small) | Qwen-2.5-Coder-3B | 71.11% | 38.93% | 99.32% | 55.93% |
| Qwen-2.5-3B | 93.72% | 78.03% | 91.84% | 84.37% | |
| Qwen-2.5-1.5B | 43.62% | 34.61% | 95.77% | 50.84% | |
| Qwen-2.5-0.5B | 19.47% | 18.65% | 100.00% | 31.44% | |
| LLM + BFAD | GPT-4 | 99.75% | 100.00% | 98.71% | 99.35% (+6.89) |
| LLaMA-3.1-70B | 99.38% | 98.72% | 98.09% | 98.40% (+3.63) | |
| Qwen-2.5-Coder-14B | 98.76% | 98.68% | 94.90% | 96.75% (+0.36) | |
| Qwen-2.5-Coder-3B | 78.89% | 46.67% | 100.00% | 63.64% (+7.71) | |
| Qwen-2.5-3B | 97.39% | 88.64% | 99.36% | 93.69% (+9.32) | |
| Qwen-2.5-1.5B | 80.40% | 48.51% | 100.00% | 65.33% (+14.49) | |
| Qwen-2.5-0.5B | 91.94% | 71.10% | 98.73% | 82.67% (+51.23) |
Table 4: Performance Comparison of BFAD-Enhanced Models Against Baselines, showing how traditional ML and DL models compare with LLMs of various sizes, both with and without BFAD enhancement.
When enhanced with the BFAD framework, all LLMs showed significant improvements:
For large LLMs, BFAD increased recall while maintaining near-perfect precision. GPT-4's recall jumped by 12.73% to 98.71%, yielding an F1 score of 99.35%—surpassing the state-of-the-art GAT baseline (98.87%).
For small LLMs, BFAD dramatically increased precision without compromising high recall. Qwen-2.5-0.5B's precision rose by 52.36% to 71.10%, resulting in an F1 score of 82.67% (a 51.23% improvement).
These improvements allow BFAD-enhanced LLMs to match or exceed traditional methods without additional fine-tuning or training, highlighting the transformative potential of integrating domain-specific strategies with LLMs for vulnerability detection.
Focusing on What Matters: How Context-Aware Extraction Improves Detection
The researchers evaluated Context-Aware Code Extraction using GPT-4 (a large model) and Qwen-2.5-3B (a smaller model). They compared three configurations:
- Predictions based on the full source code
- Predictions using only extracted critical regions
- A hybrid approach combining critical regions with truncated source code
For the smaller model, Qwen-2.5-3B, focusing on critical regions significantly improved performance. At a context length of τ=100, the F1 score increased from 84.37% to 90.91% (+6.54%), with precision rising from 78.03% to 86.71% (+8.68%). However, as context length increased, performance decreased—likely due to the model's limited ability to handle extended context introducing noise.
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Source Code (Vanilla) | 93.72% | 78.03% | 91.84% | 84.37% |
| Critical Regions (τ=100) | 96.28% | 86.71% | 95.54% | 90.91% |
| Critical Regions (τ=200) | 95.78% | 84.75% | 95.54% | 89.82% |
| Critical Regions (τ=300) | 95.04% | 82.32% | 94.90% | 88.17% |
| Hybrid Strategy (τ=100) | 96.40% | 89.02% | 92.99% | 90.97% |
| Hybrid Strategy (τ=200) | 95.66% | 85.47% | 93.63% | 89.36% |
| Hybrid Strategy (τ=300) | 95.78% | 85.55% | 94.27% | 89.70% |
Table 5: Performance of Context-Aware Code Extraction with Qwen-2.5-3B with Different Context Lengths and Strategies.
For GPT-4, critical regions increased recall but slightly decreased precision. At τ=300, recall improved from 85.98% to 96.18% (+10.20%), while precision dropped marginally from 100.00% to 98.69%. The F1 score increased from 92.46% to 97.42% (+4.96%).
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Source Code (Vanilla) | 97.27% | 100.00% | 85.98% | 92.46% |
| Critical Regions (τ=100) | 98.51% | 99.32% | 92.99% | 96.05% |
| Critical Regions (τ=200) | 99.01% | 99.34% | 95.54% | 97.40% |
| Critical Regions (τ=300) | 99.01% | 98.69% | 96.18% | 97.42% |
| Hybrid Strategy (τ=100) | 99.01% | 100.00% | 94.90% | 97.39% |
| Hybrid Strategy (τ=200) | 99.14% | 100.00% | 95.81% | 97.86% |
| Hybrid Strategy (τ=300) | 99.38% | 100.00% | 96.82% | 98.38% |
Table 6: Performance of Context-Aware Code Extraction with GPT-4 with Different Context Lengths and Strategies.
The hybrid strategy proved most effective, balancing precision and recall. For Qwen-2.5-3B, it increased precision over using critical regions alone, while maintaining strong recall. For GPT-4, it improved recall without compromising precision: at τ=300, recall increased to 96.82% (+10.84% over the source code baseline) while maintaining 100% precision.
Better Examples Lead to Better Performance: The Impact of WBFP
The researchers evaluated five demonstration selection strategies for in-context learning:
- No ICL (baseline)
- Random Selection
- Source Code Semantic Similarity (SC-Sim)
- WBFP with Equal Weights (WBFP-Eq)
- WBFP with Function-Level Weights (WBFP-Wt)
Random selection significantly degraded performance by adding irrelevant examples. For Qwen-2.5-3B, the F1 score dropped to 60.83% (a 23.54% reduction from baseline), mainly due to precision falling from 78.03% to 46.33%.
Semantic similarity based on entire source code (SC-Sim) performed only marginally better than the baseline, achieving an F1 score of 84.36% for Qwen-2.5-3B and 96.32% for GPT-4. This limited improvement likely stems from behavioral patterns being diluted by irrelevant code segments.
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| No-ICL | 93.72% | 78.03% | 91.84% | 84.37% |
| Random | 77.79% | 46.33% | 88.53% | 60.83% |
| SC-Sim | 93.42% | 78.57% | 91.08% | 84.36% |
| WBFP-Eq | 96.98% | 86.39% | 99.32% | 92.41% |
| WBFP-Wt | 97.39% | 88.64% | 99.36% | 93.69% |
Table 7: Comparison of Demonstration Selection Strategies for In-Context Learning with Qwen-2.5-3B (Under Best Hybrid Strategy τ=100).
WBFP-Wt consistently outperformed all other methods. For Qwen-2.5-3B, it achieved an F1 score of 93.69%, which is 9.33% higher than SC-Sim and 1.28% higher than WBFP-Eq. By focusing on the important aspects of WebShell behavior, WBFP-Wt compensated for the smaller model's limited understanding.
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| No-ICL | 99.38% | 100.00% | 96.82% | 98.38% |
| Random | 89.00% | 65.58% | 90.97% | 76.22% |
| SC-Sim | 98.63% | 100.00% | 92.90% | 96.32% |
| WBFP-Eq | 99.62% | 100.00% | 98.03% | 99.01% |
| WBFP-Wt | 99.75% | 100.00% | 98.71% | 99.35% |
Table 8: Comparison of Demonstration Selection Strategies for In-Context Learning with GPT-4 (Under Best Hybrid Strategy τ=300).
For GPT-4, WBFP-Wt achieved the highest F1 score of 99.35%. While precision remained at 100.00% across all WBFP variants, WBFP-Wt increased recall to 98.71%, compared to 92.90% for SC-Sim and 98.03% for WBFP-Eq. This improvement highlights WBFP-Wt's ability to leverage GPT-4's advanced contextual understanding by matching selected demonstrations to the behavioral characteristics of the target sample.
Positioning in the Field: Related Work and Context
WebShell detection techniques have evolved from simple rule-based methods to sophisticated deep learning approaches. Early efforts relied on signature matching or heuristics, but these methods struggle against obfuscated or novel WebShell variants. Machine learning techniques have advanced this landscape by extracting features from code text or runtime behavior, while deep learning has further improved adaptability with models like CodeBERT for semantic analysis and Graph Attention Networks (GAT) for structural insights.
LLMs have revolutionized code-related tasks by leveraging large pre-training corpora, but their application to WebShell detection remains underexplored. Using LLMs for this task reveals critical bottlenecks: the fixed context window truncates large WebShells, potentially missing malicious segments embedded in benign code. In-context learning, a cornerstone of LLM adaptability, falters because demonstrations consume context space, and random or semantic similarity-based selections fail to capture WebShell-specific behaviors.
These gaps between rule-based rigidity, ML/DL data dependency, and LLM context and ICL limitations motivated the BFAD framework. By overcoming context constraints with a hybrid extraction strategy and enhancing ICL with weighted behavioral profiling, BFAD addresses the unique challenges of applying LLMs to WebShell detection.
Advancing WebShell Detection with LLMs
The BFAD framework represents a significant advancement in applying LLMs to WebShell detection. By addressing the unique challenges of this domain through critical function filtering, context-aware code extraction, and weighted behavioral function profiling, BFAD enables LLMs to achieve state-of-the-art performance without additional training.
The framework's effectiveness is demonstrated by remarkable improvements across models of all sizes. Large models like GPT-4 achieved an F1 score of 99.35%, surpassing traditional benchmarks, while smaller models like Qwen-2.5-0.5B improved by 51.23 percentage points to reach an F1 score of 82.67%.
As the first systematic exploration of LLMs for WebShell detection, this work not only demonstrates their potential but also provides actionable solutions to their contextual and behavioral challenges. By strategically focusing on the most relevant code regions and leveraging domain-specific knowledge to select appropriate in-context examples, BFAD paves the way for future advances in code security using LLMs.
The research underscores how domain-specific engineering can dramatically enhance the capabilities of general-purpose LLMs for specialized security tasks. As WebShell attacks continue to evolve, approaches like BFAD that combine the powerful semantic understanding of LLMs with targeted techniques for handling security-specific challenges will be crucial for maintaining robust defenses.
