This is a Plain English Papers summary of a research paper called LLMs Weaponized: Hacking AI Recommenders with "CheatAgent" Attacks. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Growing Vulnerability of AI-Powered Recommendation Systems
Recommendation systems powered by Large Language Models (LLMs) have significantly improved personalized user experiences across platforms like e-commerce sites and social media. Despite these advances, the security vulnerabilities of these systems remain largely unexplored, especially under black-box attack scenarios where attackers can only observe inputs and outputs without access to internal model details.
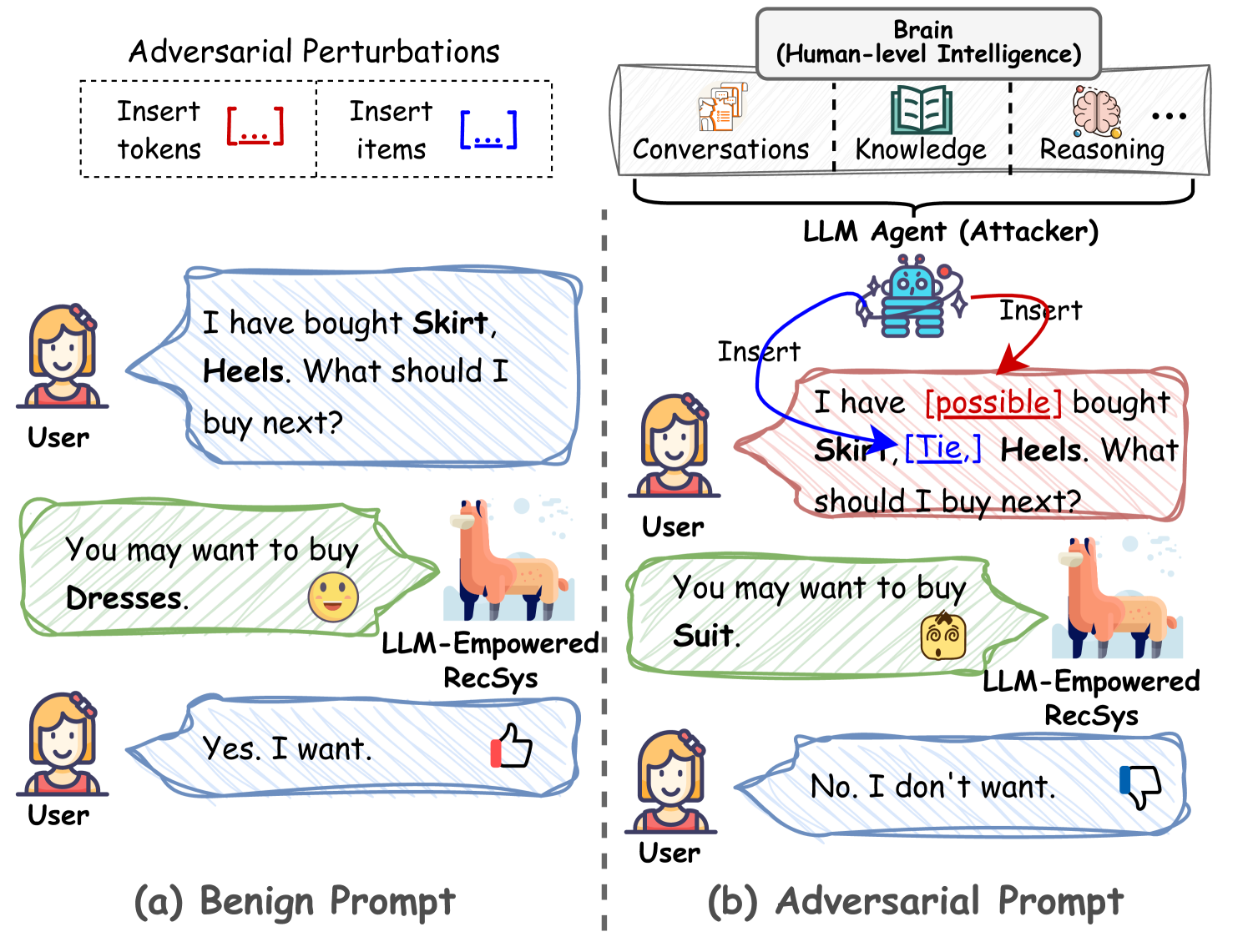
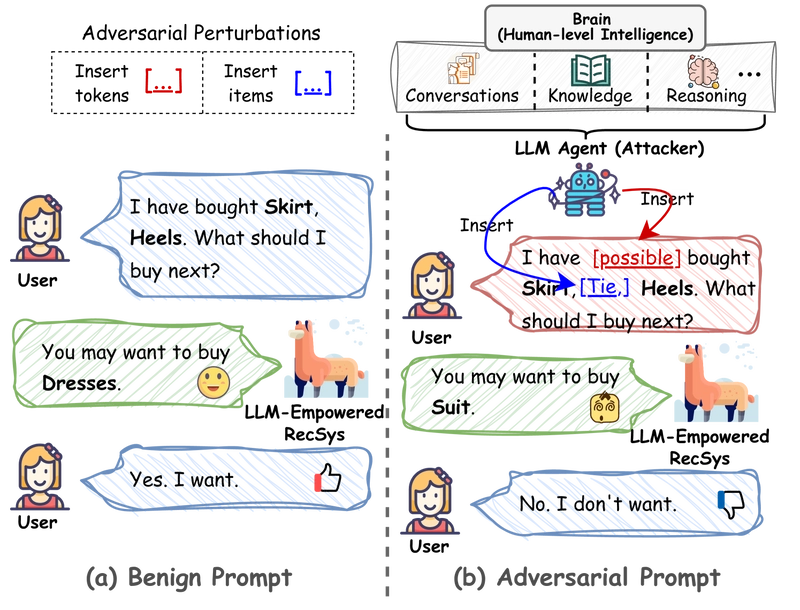
Figure 1: The illustration of the adversarial attack for recommender systems in the era of LLMs. Attackers leverage the LLM agent to insert some tokens (e.g., words) or items in the user's prompt to manipulate the LLM-empowered recommender system to make incorrect decisions.
Traditional attack approaches using reinforcement learning (RL) agents struggle with LLM-empowered recommender systems because they can't process complex textual inputs or perform sophisticated reasoning. LLMs themselves, however, offer unprecedented potential as attack agents due to their human-like decision-making capabilities. This creates a new security paradigm where LLM-powered agents can be weaponized against recommendation systems.
Understanding the Attack Scenario and Objectives
In LLM-empowered recommender systems, inputs typically consist of a prompt template, user information, and the user's historical interactions with items. For example:
X = [What, is, the, top, recommended, item, for, User_637, who,
has, interacted, with, item_1009, ..., item_4045, ?]The system then generates recommendations based on this input.
Under a black-box attack scenario, attackers can only observe the system's inputs and outputs without access to internal parameters or gradients. Their objective is to undermine the system's performance by causing it to recommend irrelevant items through:
- Inserting tailored perturbations into the prompt template
- Perturbing users' profiles to distort their original preferences
These small but strategically placed modifications aim to maximize damage while maintaining similarity to the original input to avoid detection, creating a stealthy attack scenario.
CheatAgent: A Novel Framework for Attacking Recommender Systems
CheatAgent harnesses the capabilities of LLMs to attack LLM-powered recommendation systems. This novel attack framework consists of two main components:
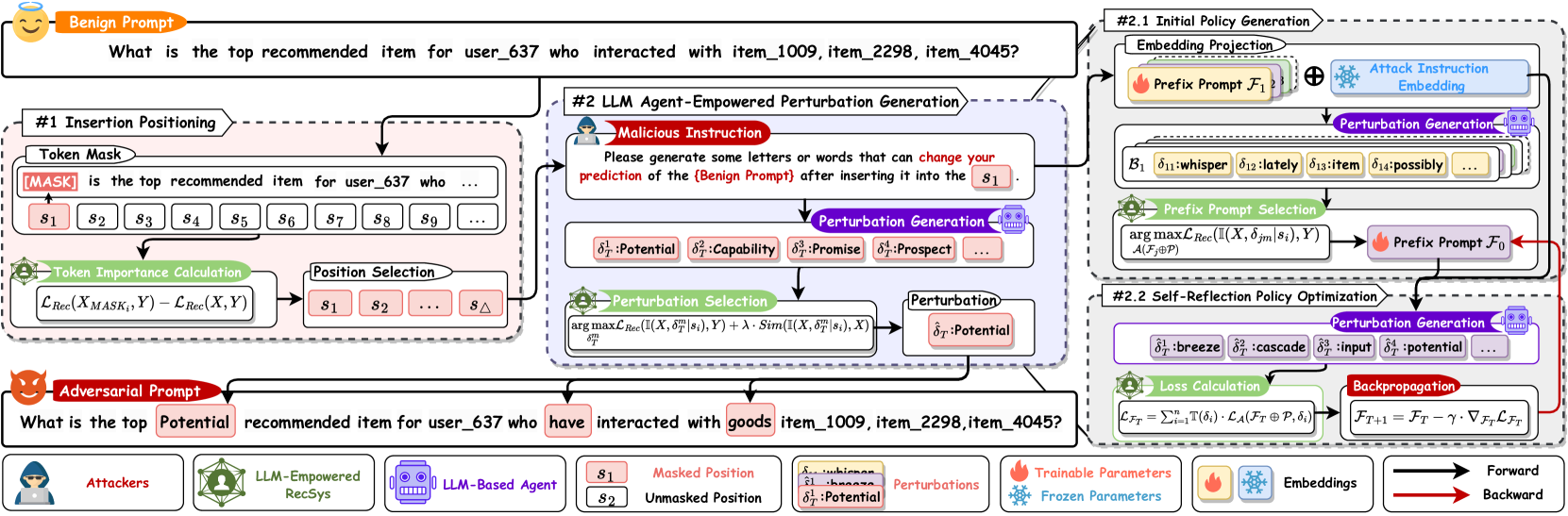
Figure 2: The overall framework of the proposed CheatAgent. Insertion positioning first locates the token with the maximum impact. Then, LLM agent-empowered perturbation generation leverages the LLM as the attacker agent to generate adversarial perturbations through initial policy generation and self-reflection policy optimization.
Insertion Positioning: This component identifies tokens within the input that have the maximum impact on recommendations, enabling efficient attacks with minimal modifications.
-
LLM Agent-Empowered Perturbation Generation: This utilizes an LLM's language comprehension and reasoning abilities to generate adversarial perturbations. It consists of:
- Initial policy generation to establish a benchmark attack strategy
- Self-reflection policy optimization that uses feedback from the victim system to improve attacks
The framework uses prompt tuning techniques to learn attack strategies and generate high-quality adversarial perturbations through iterative interactions with the victim recommender system.
Finding the Weak Points: Insertion Positioning Strategy
Not all tokens in an input prompt contribute equally to recommendation decisions. CheatAgent identifies the most influential tokens by systematically masking each token and measuring how this changes the system's prediction performance.
For each token in input X, the method:
- Creates a masked version of the input by replacing the token with [MASK]
- Calculates the change in recommendation performance between the original and masked input
- Identifies tokens with the highest impact scores
This strategic positioning enables attacks to achieve maximum impact with minimal modifications. By targeting only the most influential parts of the input, CheatAgent creates efficient and effective attacks that are harder to detect.
Weaponizing LLMs: Generating Effective Adversarial Perturbations
Once vulnerable positions are identified, CheatAgent leverages an LLM-based agent to generate perturbations. This approach capitalizes on LLMs' natural language understanding and reasoning capabilities to craft adversarial perturbations that effectively mislead recommendation systems.
The perturbation generation process involves:
Initial Policy Generation: The system searches for an appropriate prefix prompt to initialize a benchmark attack policy that efficiently influences the recommendation system.
Self-Reflection Policy Optimization: CheatAgent fine-tunes the prefix prompt using feedback from the victim system, gradually improving the attack effectiveness through an iterative learning process.
Rather than fine-tuning the entire LLM, which would be impractical and inefficient, CheatAgent uses prompt tuning to adjust a trainable prefix prompt. This approach significantly reduces computational burden while maintaining attack effectiveness, representing a sophisticated evolution in attack techniques against LLM systems.
Experimental Setup: Testing Attack Effectiveness
CheatAgent was evaluated on three widely-used recommendation system datasets:
- MovieLens-1M (ML1M): Contains movie ratings and user information
- Taobao: Features e-commerce transaction data
- LastFM: Provides user listening histories and music information
Two state-of-the-art LLM-empowered recommender systems were tested:
- P5: Converts all data to natural language sequences and fine-tunes T5 model
- TALLRec: Transforms recommendation into a binary textual classification problem using LLaMA
CheatAgent was compared against multiple baseline methods including manually designed adversarial prompts (MD), reinforcement learning-based attacks (RL), genetic algorithm-based attacks (GA), and other approaches like BERT-based adversarial examples (BAE) and LLM-based attacks (LLMBA). This comprehensive evaluation helps position CheatAgent within the landscape of existing backdoor attack techniques.
Results: CheatAgent Outperforms Existing Attack Methods
The experiments demonstrate that CheatAgent significantly outperforms existing attack methods across multiple metrics and datasets:
| Methods | H@5 ↓ | H@10 ↓ | N@5 ↓ | N@10 ↓ | ASR-H@5 ↑ | ASR-H@10 ↑ | ASR-N@5 ↑ | ASR-N@10 ↑ |
|---|---|---|---|---|---|---|---|---|
| ML1M | ||||||||
| Benign | 0.2116 | 0.3055 | 0.1436 | 0.1737 | / | / | / | / |
| MD | 0.1982 | 0.2818 | 0.1330 | 0.1602 | 0.0634 | 0.0775 | 0.0735 | 0.0776 |
| RP | 0.2051 | 0.2940 | 0.1386 | 0.1671 | 0.0305 | 0.0374 | 0.0347 | 0.0380 |
| RT | 0.1949 | 0.2800 | 0.1317 | 0.1591 | 0.0790 | 0.0835 | 0.0826 | 0.0839 |
| RL | 0.1917 | 0.2788 | 0.1296 | 0.1576 | 0.0939 | 0.0873 | 0.0974 | 0.0926 |
| GA | 0.0829 | 0.1419 | 0.0532 | 0.0721 | 0.6080 | 0.5355 | 0.6298 | 0.5849 |
| BAE | 0.1606 | 0.2440 | 0.1047 | 0.1315 | 0.2410 | 0.2011 | 0.2712 | 0.2432 |
| LLMBA | 0.1889 | 0.2825 | 0.1284 | 0.1585 | 0.1072 | 0.0753 | 0.1061 | 0.0876 |
| RPGP | 0.1733 | 0.2588 | 0.1164 | 0.1439 | 0.1808 | 0.1528 | 0.1893 | 0.1715 |
| C-w/o PT | 0.0844 | 0.1392 | 0.0531 | 0.0706 | 0.6009 | 0.5442 | 0.6303 | 0.5935 |
| CheatAgent | 0.0614 | 0.1132 | 0.0389 | 0.0555 | 0.7097 | 0.6293 | 0.7290 | 0.6805 |
| LastFM | ||||||||
| Benign | 0.0404 | 0.0606 | 0.0265 | 0.0331 | / | / | / | / |
| MD | 0.0339 | 0.0477 | 0.0230 | 0.0274 | 0.1591 | 0.2121 | 0.1333 | 0.1713 |
| RP | 0.0394 | 0.0550 | 0.0241 | 0.0291 | 0.0227 | 0.0909 | 0.0921 | 0.1195 |
| RT | 0.0413 | 0.0550 | 0.0271 | 0.0315 | -0.0227 | 0.0909 | -0.0216 | 0.0463 |
| RL | 0.0294 | 0.0468 | 0.0200 | 0.0256 | 0.2727 | 0.2273 | 0.2460 | 0.2272 |
| GA | 0.0248 | 0.0431 | 0.0156 | 0.0216 | 0.3864 | 0.2879 | 0.4111 | 0.3477 |
| BAE | 0.0165 | 0.0339 | 0.0093 | 0.0149 | 0.5909 | 0.4394 | 0.6480 | 0.5497 |
| LLMBA | 0.0404 | 0.0541 | 0.0291 | 0.0336 | 0.0000 | 0.1061 | -0.0969 | -0.0150 |
| RPGP | 0.0294 | 0.0514 | 0.0184 | 0.0253 | 0.2727 | 0.1515 | 0.3076 | 0.2349 |
| C-w/o PT | 0.0138 | 0.0275 | 0.0091 | 0.0135 | 0.6591 | 0.5455 | 0.6580 | 0.5924 |
| CheatAgent | 0.0119 | 0.0257 | 0.0072 | 0.0118 | 0.7045 | 0.5758 | 0.7269 | 0.6445 |
| Taobao | ||||||||
| Benign | 0.1420 | 0.1704 | 0.1100 | 0.1191 | / | / | / | / |
| MD | 0.1365 | 0.1624 | 0.1085 | 0.1170 | 0.0392 | 0.0471 | 0.0130 | 0.0180 |
| RP | 0.1250 | 0.1512 | 0.0977 | 0.1061 | 0.1200 | 0.1125 | 0.1117 | 0.1091 |
| RT | 0.1396 | 0.1658 | 0.1090 | 0.1174 | 0.0173 | 0.0269 | 0.0092 | 0.0145 |
| RL | 0.1376 | 0.1650 | 0.1075 | 0.1163 | 0.0311 | 0.0317 | 0.0222 | 0.0234 |
| GA | 0.1294 | 0.1579 | 0.0993 | 0.1086 | 0.0888 | 0.0731 | 0.0966 | 0.0886 |
| BAE | 0.1278 | 0.1519 | 0.0989 | 0.1066 | 0.1003 | 0.1087 | 0.1009 | 0.1050 |
| LLMBA | 0.1353 | 0.1624 | 0.1050 | 0.1138 | 0.0473 | 0.0471 | 0.0452 | 0.0448 |
| RPGP | 0.1258 | 0.1512 | 0.0971 | 0.1053 | 0.1142 | 0.1125 | 0.1167 | 0.1159 |
| C-w/o PT | 0.1017 | 0.1258 | 0.0737 | 0.0815 | 0.2837 | 0.2615 | 0.3298 | 0.3161 |
| CheatAgent | 0.0985 | 0.1229 | 0.0717 | 0.0796 | 0.3068 | 0.2788 | 0.3480 | 0.3319 |
Table 1: Attack Performance of different methods with P5 as the victim model using sequential indexing. Lower Hit@k and NDCG@k values indicate better attack performance, while higher ASR values show better attack success rates.
Key findings include:
Even random token insertions (RT and RP) reduce recommendation performance, revealing fundamental vulnerabilities in LLM-based recommender systems.
Manually designed adversarial examples (MD) perform poorly compared to automated approaches, highlighting the need for more sophisticated attack strategies.
CheatAgent consistently outperforms all baselines across datasets and metrics, with attack success rates (ASR) reaching 70-73% in some scenarios.
The strategic insertion positioning component significantly contributes to attack effectiveness, as shown by comparing RPGP (random perturbations at strategic positions) with RT and RP (random perturbations at random positions).
The effectiveness of CheatAgent across both P5 and TALLRec demonstrates its resilience against different recommender system architectures.
Maintaining Stealth: Semantic Similarity Analysis
For attacks to remain undetected, adversarial inputs must maintain semantic similarity to the original inputs. CheatAgent excels in this area, achieving high cosine similarity and low 1-norm difference compared to other effective attack methods.
The semantic similarity analysis shows that:
All methods maintain relatively high similarity due to the constraint on perturbation intensity.
Inserting perturbations into users' profiles (RP) is more stealthy than modifying input prompts.
Among methods that modify input prompts, CheatAgent maintains the highest semantic similarity while achieving superior attack performance.
This stealthiness makes CheatAgent particularly dangerous, as its adversarial perturbations are difficult to detect through semantic analysis while still effectively compromising recommendation quality.
Component Analysis: What Makes CheatAgent Effective
An ablation study was conducted to understand the contribution of each component in CheatAgent:
| Datasets | Methods | H@5 ↓ | H@10 ↓ | N@5 ↓ | N@10 ↓ | ASR-H@5 ↑ | ASR-H@10 ↑ | ASR-N@5 ↑ | ASR-N@10 ↑ |
|---|---|---|---|---|---|---|---|---|---|
| LastFM | CheatAgent | 0.0119 | 0.0257 | 0.0072 | 0.0118 | 0.7045 | 0.5758 | 0.7269 | 0.6445 |
| CheatAgent-RP | 0.0193 | 0.0358 | 0.0111 | 0.0166 | 0.5227 | 0.4091 | 0.5816 | 0.4995 | |
| CheatAgent-I | 0.0147 | 0.0284 | 0.0096 | 0.0140 | 0.6364 | 0.5303 | 0.6377 | 0.5769 | |
| CheatAgent-T | 0.0128 | 0.0259 | 0.0074 | 0.0120 | 0.6818 | 0.5730 | 0.7199 | 0.6371 | |
| ML1M | CheatAgent | 0.0614 | 0.1132 | 0.0389 | 0.0555 | 0.7097 | 0.6293 | 0.7290 | 0.6805 |
| CheatAgent-RP | 0.1336 | 0.2036 | 0.0881 | 0.1107 | 0.3685 | 0.3333 | 0.3866 | 0.3630 | |
| CheatAgent-I | 0.0810 | 0.1354 | 0.0512 | 0.0686 | 0.6174 | 0.5566 | 0.6437 | 0.6050 | |
| CheatAgent-T | 0.0727 | 0.1205 | 0.0456 | 0.0608 | 0.6565 | 0.6054 | 0.6825 | 0.6497 | |
| Taobao | CheatAgent | 0.0985 | 0.1229 | 0.0717 | 0.0796 | 0.3068 | 0.2788 | 0.3480 | 0.3319 |
| CheatAgent-RP | 0.1258 | 0.1497 | 0.0960 | 0.1037 | 0.1142 | 0.1212 | 0.1271 | 0.1293 | |
| CheatAgent-I | 0.1024 | 0.1263 | 0.0744 | 0.0821 | 0.2791 | 0.2587 | 0.3233 | 0.3107 | |
| CheatAgent-T | 0.0985 | 0.1243 | 0.0718 | 0.0802 | 0.3068 | 0.2702 | 0.3468 | 0.3272 |
Table 2: Comparison between CheatAgent and its variants on three datasets. Bold fonts denote the best performance.
The variants tested include:
- CheatAgent-RP: Uses LLM agent for perturbation generation but inserts them at random positions
- CheatAgent-I: Fine-tunes the prefix prompt with random initialization
- CheatAgent-T: Uses the initial prefix prompt without further policy tuning
Comparing CheatAgent with these variants reveals that:
Strategic positioning is crucial, as shown by the significant performance drop in CheatAgent-RP.
Both initial policy generation and self-reflection policy optimization contribute to attack effectiveness, though their relative importance varies across datasets.
These findings demonstrate that CheatAgent's superior performance stems from the synergistic combination of all its components.
Practical Considerations: Parameter Sensitivity
Two key parameters influence CheatAgent's performance:
- k: The number of randomly initialized prefix prompts during initial policy generation
- n: The number of generated perturbations from the LLM-based agent
The parameter analysis shows that:
CheatAgent is robust to variations in k, with attack performance fluctuating within a small range.
Attack effectiveness improves as n increases, but with diminishing returns and increased computational cost.
For practical deployments, n=10 provides a good balance between attack performance and efficiency.
Positioning Within Existing Research
Adversarial attacks against recommender systems generally fall into two categories:
- Evasion Attacks (like CheatAgent): Occur during inference by modifying inputs to manipulate recommendations
- Poisoning Attacks: Happen during data collection by injecting poisoned data to compromise model training
Early approaches used heuristic or gradient-based methods, which were effective against white-box systems but struggled with black-box scenarios. More recent approaches employ reinforcement learning but lack the language processing capabilities needed for LLM-based recommenders.
CheatAgent represents a significant advancement by leveraging LLMs' language understanding and reasoning capabilities to attack other LLM-based systems. It demonstrates how the vulnerabilities of LLMs can create new attack vectors for AI systems that incorporate them.
Implications and Future Directions
CheatAgent reveals significant vulnerabilities in LLM-empowered recommender systems, which has important implications for their deployment in sensitive domains like finance or healthcare.
The research provides three key insights:
LLM-empowered recommender systems are highly vulnerable to adversarial attacks, with even simple perturbations degrading performance.
LLMs themselves can be weaponized as attack agents, creating a concerning scenario where AI systems attack other AI systems.
Strategic positioning of adversarial perturbations significantly enhances attack effectiveness while maintaining stealthiness.
These findings emphasize the urgent need for robust defensive measures against adversarial attacks on LLM-empowered recommender systems. As these systems become more prevalent, ensuring their security and trustworthiness becomes increasingly critical for maintaining user trust and system integrity.
