Introduction
Machine Learning is everywhere—from recommendation systems to self-driving cars. But have you ever wondered how these algorithms actually work under the hood? Many tutorials focus on using high-level libraries like scikit-learn and TensorFlow, but understanding the fundamentals requires building ML models from scratch.
That's why I created ML-Algorithms—an open-source repository with clean Python implementations of essential ML algorithms. It’s designed to help beginners and professionals understand, modify, and experiment with machine learning techniques without black-box magic.
🌟 Why This Repo Stands Out
- 🔍 Clear, well-structured implementations for easy learning.
- 📝 Jupyter Notebooks for interactive exploration.
- ⚡ Minimal dependencies—just Python & NumPy.
- 🎯 Beginner-friendly yet deep enough for pros.
💬 Join the conversation: Share your thoughts, ask questions, and contribute ideas in the GitHub Discussions.
🔎 What’s Inside?
The repository includes well-documented Python implementations of:
✅ Supervised Learning (Linear Regression, Decision Trees)
✅ Unsupervised Learning (K-Means Clustering, PCA)
✅ Reinforcement Learning (Q-Learning, Deep Q-Network)
✅ Deep Learning (Neural Networks, CNNs)
Each algorithm comes with:
- Simple Python implementations (no unnecessary dependencies).
- Clear explanations with comments.
- Jupyter Notebooks to visualize results.
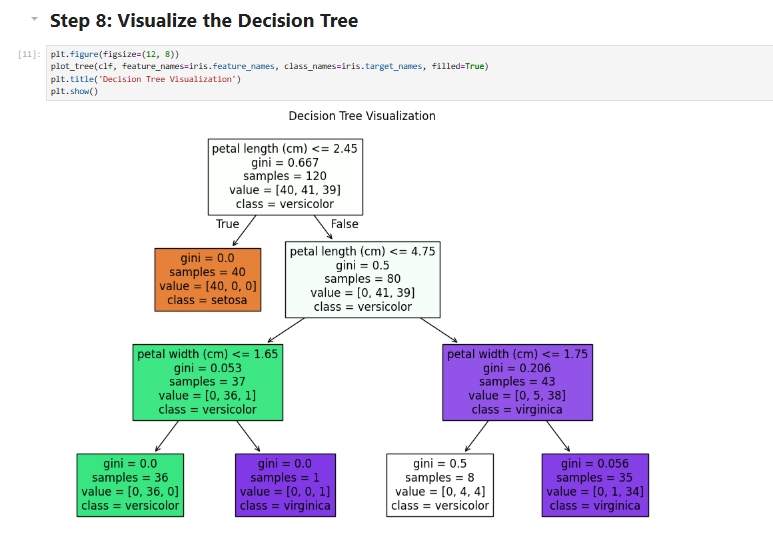
⚙️ How It Works (Example: Decision Trees 🌳)
Let's break down a simple Decision Tree implementation from the repo.
class DecisionTree:
def __init__(self, max_depth=None):
self.max_depth = max_depth
def fit(self, X, y):
self.tree = self._grow_tree(X, y)
def _grow_tree(self, X, y, depth=0):
if depth == self.max_depth or len(set(y)) == 1:
return np.argmax(np.bincount(y))
feature, threshold = self._best_split(X, y)
left_idx, right_idx = X[:, feature] <= threshold, X[:, feature] > threshold
return (feature, threshold,
self._grow_tree(X[left_idx], y[left_idx], depth + 1),
self._grow_tree(X[right_idx], y[right_idx], depth + 1))🔹 What’s happening here?
- The
_grow_treemethod recursively splits the dataset based on the best feature. - Once it reaches the max depth, it assigns the most common class.
- Simple, effective, and easy to modify!
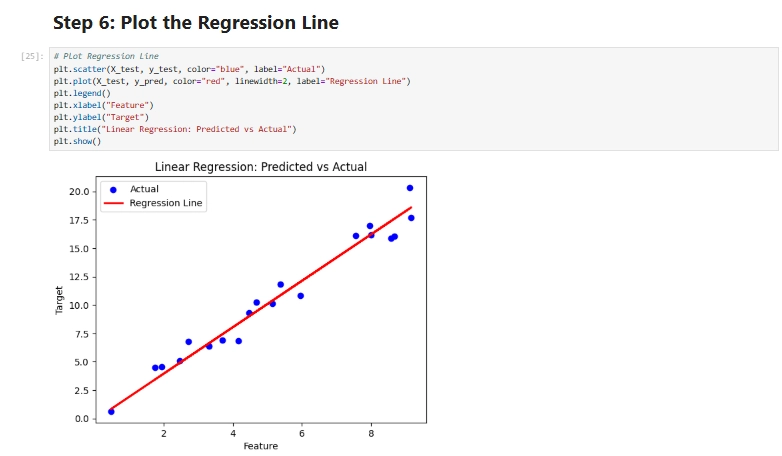
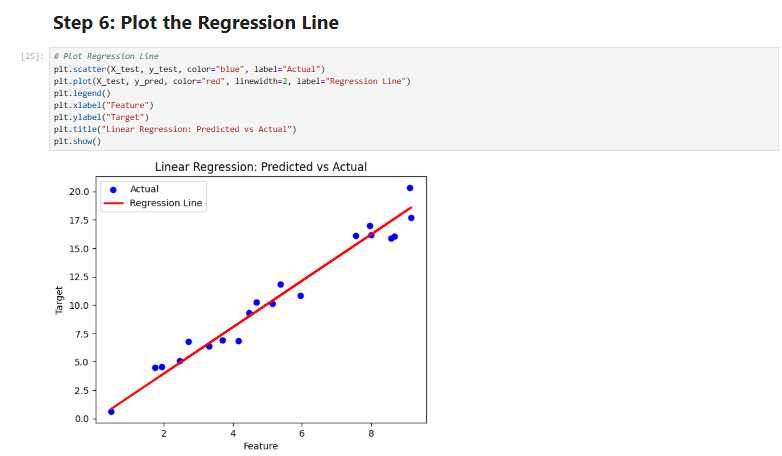
📸 Want to see it in action? Here’s an example output visualization:
💻 Try It Yourself (Google Colab 🚀)
Want to run the code without setting up anything? Click below to open the repo in Google Colab:
![]()
📣 Boosting Open-Source Visibility – Join the Movement!
🚀 If you find this project valuable, here’s how you can help it grow:
✅ Star the repo on GitHub ⭐
✅ Share the repo on X (Twitter), LinkedIn, or Dev.to
✅ Contribute by adding new algorithms or improvements 🛠️
🌍 Join the discussion & connect with ML enthusiasts!
💬 GitHub Discussions – Ask questions, suggest features, and share insights!
🔗 Follow Me for More ML & AI Content
📢 I share AI research, coding projects, and ML insights on my socials:
📌 X (Twitter): @tomlikestocode
🌍 Personal Website: tomboyle.io
🔗 Let’s connect and build amazing AI projects together!
What’s an ML algorithm you’ve struggled with before? Let me know in the comments! 🚀