Table of Contents
- cut: Extracting Specific Parts of a Line
- awk: Field-Based Processing and Pattern Matching
- grep & egrep: Pattern Search
- sort: Sorting Output
- uniq: Finding Unique Lines
- wc: Word, Line, and Character Count
- Conclusion
Description
Learn how to manipulate, filter, and analyze text in Linux using powerful tools like cut, awk, grep, sort, uniq, and wc — with examples.
cut: Extracting Specific Parts of a Line
The cut command allows you to extract parts of a line based on character position, byte size, or delimiter.
Common cut Examples:
| Command | Description |
|---|---|
cut --version |
Check version |
cut -c1 filename |
Show only the first character of each line |
cut -c1,2,4 filename |
Show characters 1, 2, and 4 |
cut -c1-3 filename |
Show a range of characters |
cut -b1-3 filename |
Cut by byte size |
cut -d: -f6 /etc/passwd |
Show the 6th field, using : as delimiter |
cut -d: -f6-7 /etc/passwd |
Show fields 6 and 7 |
| `ls -l | cut -c2-4` |
-
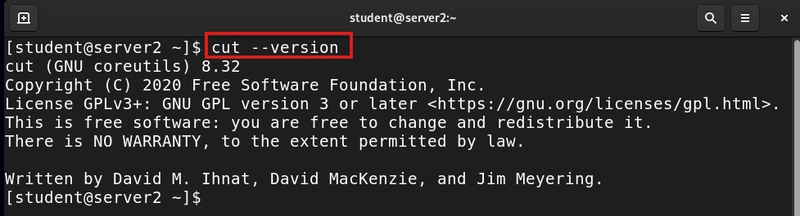
cut --version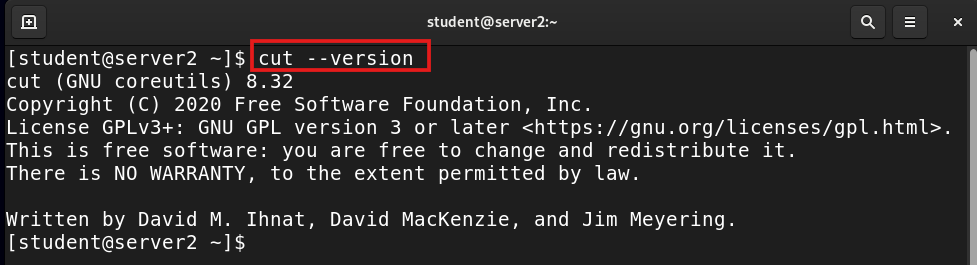
-
cut -c1 file6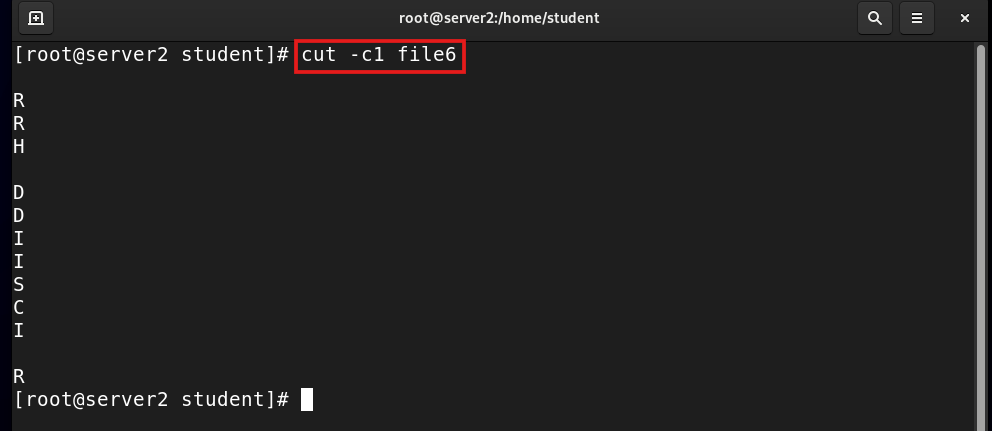
-
cut -c1,2,4 file6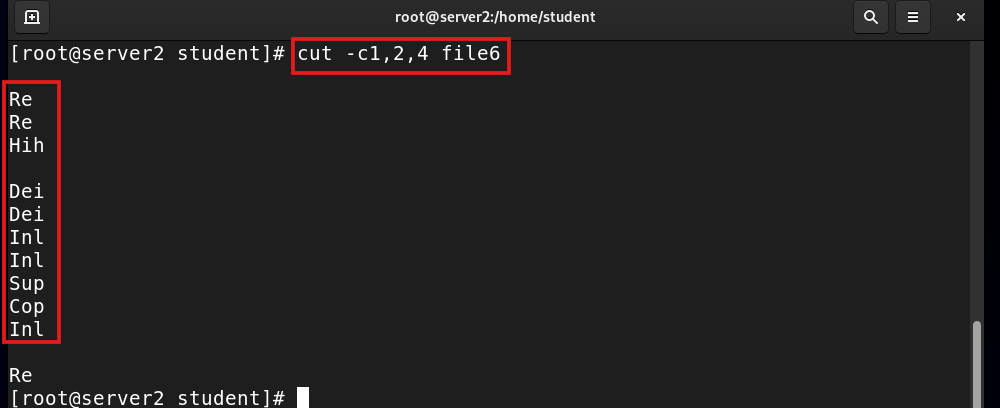
-
cut -c1-3 file6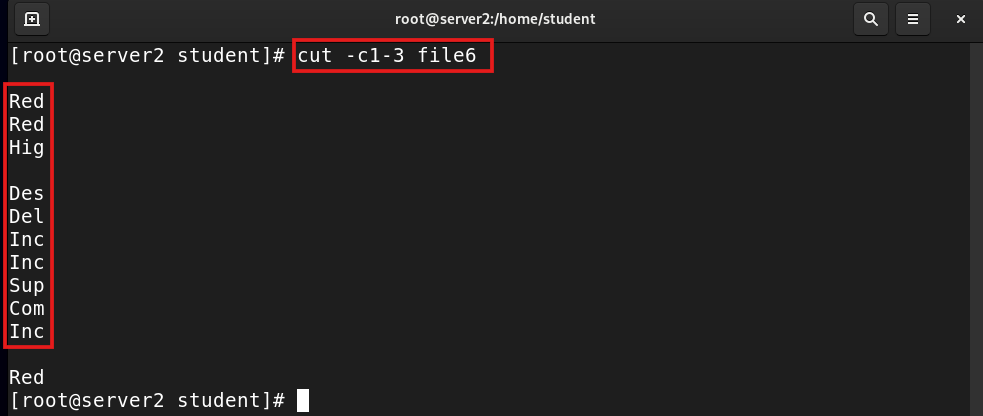
-
cut -b1-3 file6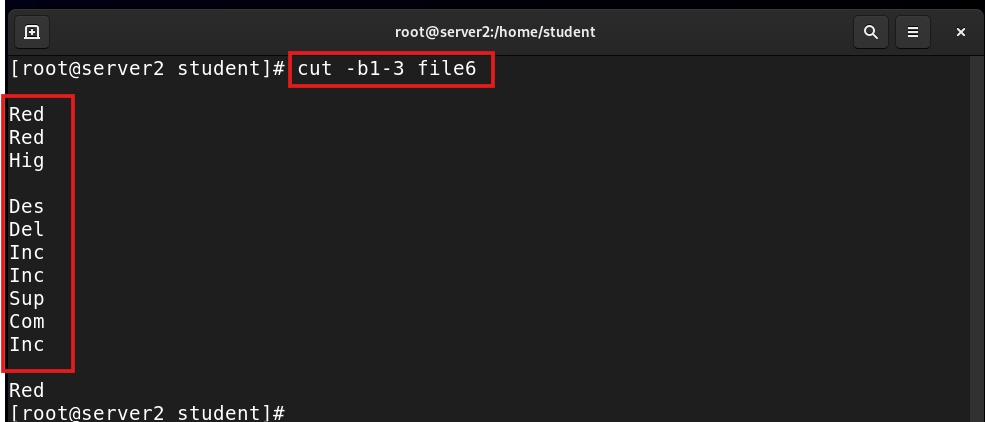
-
cut -d: -f6 /etc/passwd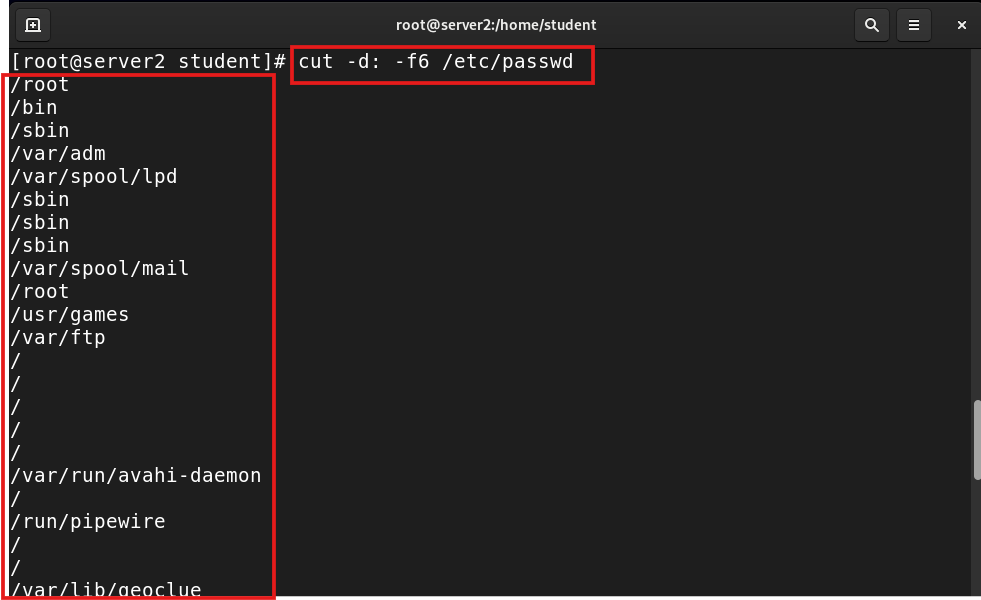
-
cut -d: -f6-7 /etc/passwd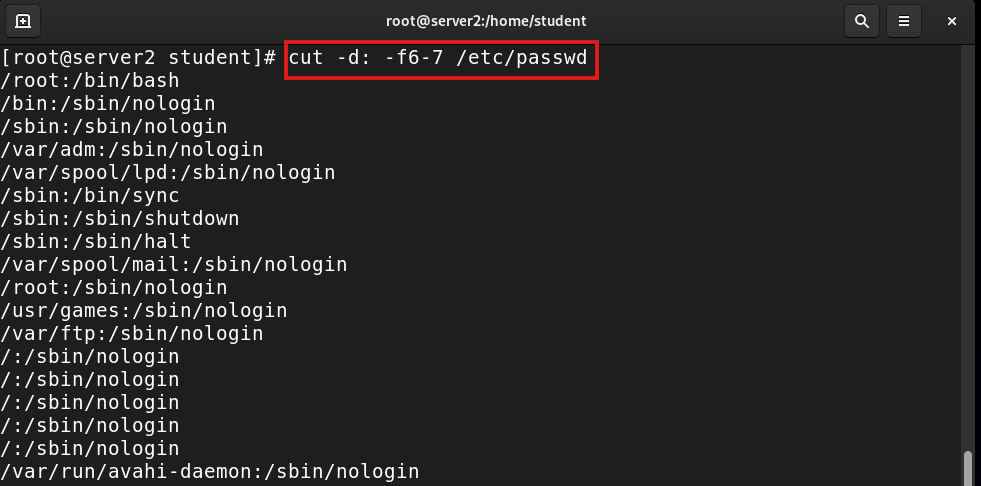
-
ls -l | cut -c1-4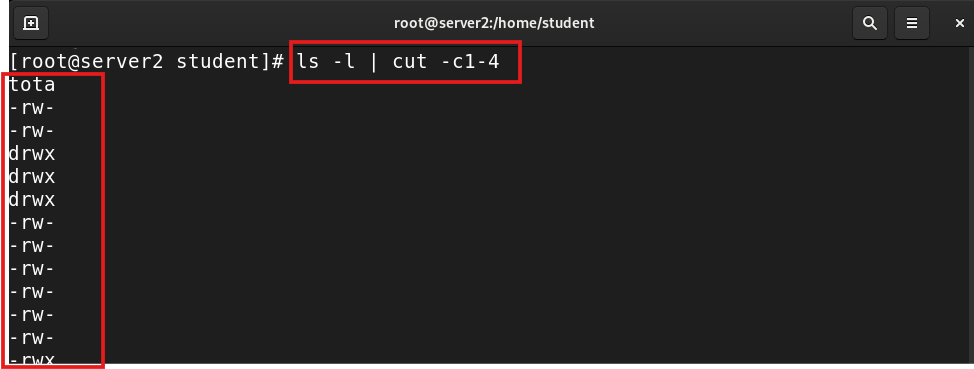
awk: Field-Based Processing and Pattern Matching
awk is a powerful text-processing language great for extracting and analyzing structured data.
Common awk Examples:
| Command | Description |
|---|---|
awk --version |
Check version |
awk '{print $1}' file |
Show the first field of each line |
| `ls -l | awk '{print $1,$3}'` |
| `ls -l | awk '{print $NF}'` |
awk '/Jerry/ {print}' file |
Show lines containing "Jerry" |
awk -F: '{print $1}' /etc/passwd |
Show the first field using : as delimiter |
| `echo "Hello Tom" | awk '{$2="Adam"; print $0}'` |
awk 'length($0) > 15' file |
Show lines longer than 15 characters |
| `ls -l | awk '{if($9=="seinfeld") print $0;}'` |
| `ls -l | awk '{print NF}'` |
-
awk --version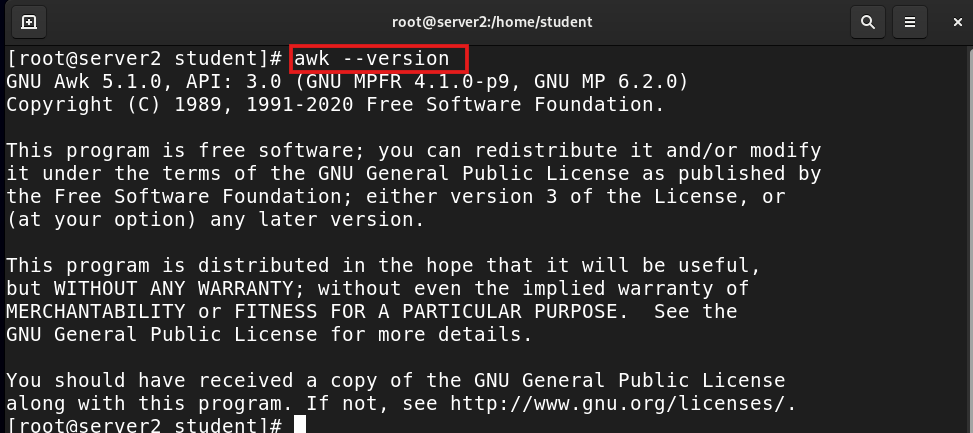
-
awk '{print $1}' file6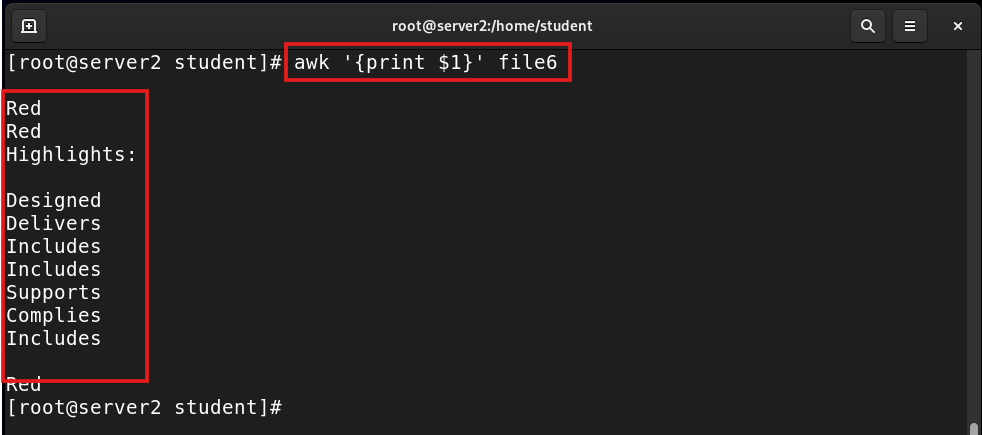
-
ls -l | awk '{print $1,$3}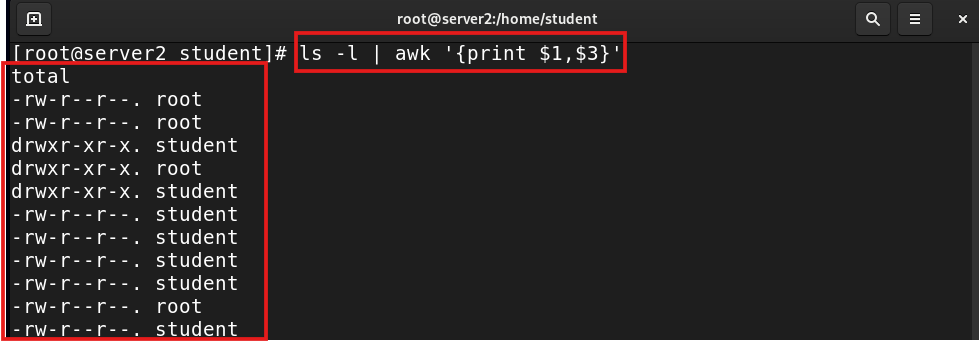
grep & egrep: Pattern Search
Use grep to search for patterns in text files.
| Command | Description |
|---|---|
grep 'error' logfile.txt |
Search for "error" in a file |
| `egrep 'warn | fail' logfile.txt` |
grep -i 'login' file |
Case-insensitive search |
grep -v 'debug' file |
Exclude lines with "debug" |
grep -r 'main' /etc/ |
Recursively search through directories |
-
grep 'error' logfile.txt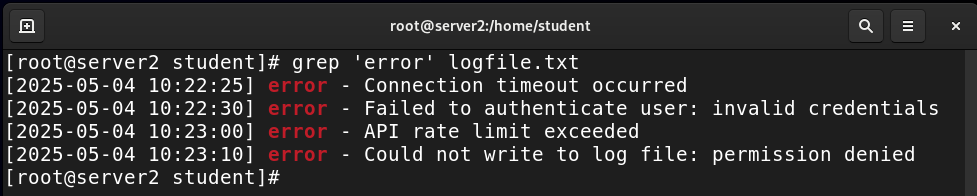
-
egrep 'warn|fail' logfile.txt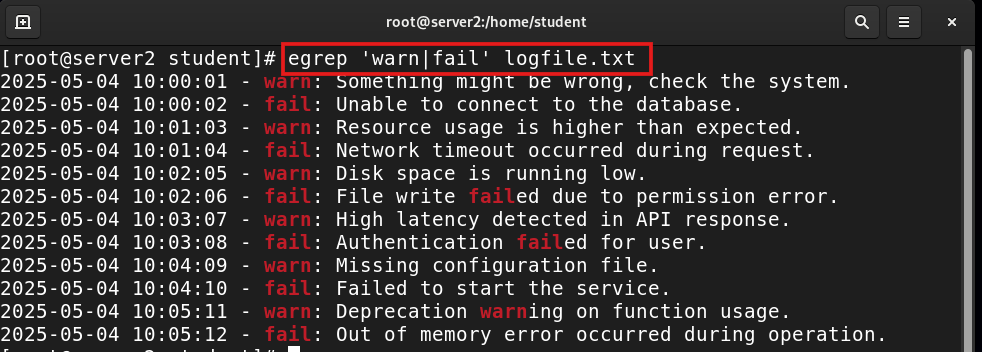
-
grep -v 'fail' logfile.txt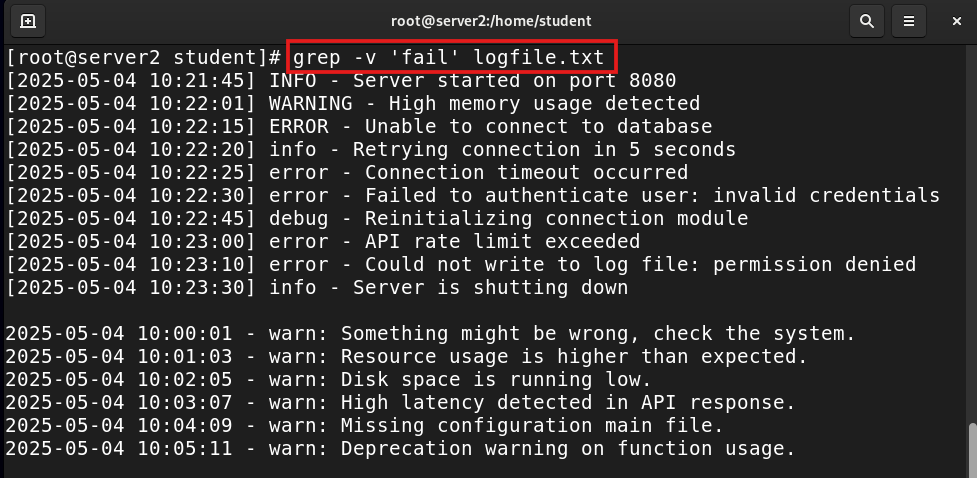
-
grep -r 'main' /etc/
sort: Sorting Output
Sort lines in alphabetical or numerical order.
| Command | Description |
|---|---|
sort file.txt |
Sort file alphabetically |
sort -r file.txt |
Reverse sort |
sort -n numbers.txt |
Sort numerically |
sort -u file.txt |
Remove duplicates after sorting |
uniq: Finding Unique Lines
Filters repeated lines. Often used with sort.
| Command | Description |
|---|---|
uniq file.txt |
Show unique lines (removes duplicates) |
| `sort file.txt | uniq` |
uniq -c file.txt |
Count occurrences of each line |
wc: Word, Line, and Character Count
wc stands for word count and can be used for multiple metrics.
| Command | Description |
|---|---|
wc -l file.txt |
Count lines |
wc -w file.txt |
Count words |
wc -c file.txt |
Count characters (bytes) |
| `cat file.txt | wc` |
-
wc logfile.txt
-
wc -w logfile.txt
-
wc -c logfile.txt
-
cat logfile.txt | wc
Conclusion
These commands are the backbone of text processing and data filtering on the Linux command line. Whether you're working with logs, config files, or large datasets, knowing how to combine and use cut, awk, grep, sort, uniq, and wc will make your life a lot easier.