I wrote my sample MCP server, client and agent… 🤷♂️
Introduction
Everyday, browsing tech sites (Medium, dev.to… duh 😅) I see a huge number of articles people saying how to write you own MCP server, client… so I decided to try to write my own “stuff”… but I still have questions 🤔
TLDR; — Let’s introduce the implementation as seriously as possible!
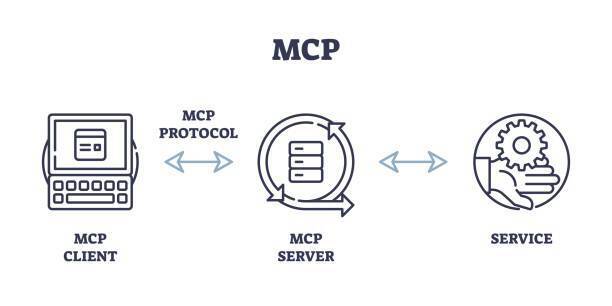
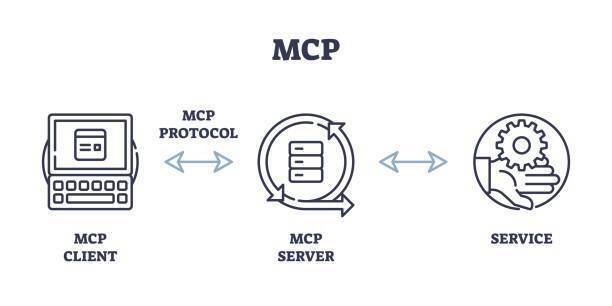
This suite of Python applications demonstrates a fundamental architecture for interacting with large language models (LLMs) using the Model Context Protocol (MCP). By separating the LLM service (the server) from the applications that utilize it (the client and agent), establishing a modular and approach. The server, in this case, hosts the open-source Granite LLM from Hugging Face, making its text generation capabilities available. The client provides a direct interface for invoking these capabilities, while the agent showcases a practical application of leveraging the LLM for a specific task.
The MCP Server
What is the MCP server?
The server.py sample app, acts as the central hub that makes the Granite language model accessible via the Model Context Protocol (MCP).
It initializes an MCP server named “SampleAgentServer” and defines a specific capability as an MCP “tool” called generate_text. This tool, when invoked by a client, loads the “ibm-granite/granite-3.3–2b-base” model using the transformers library.
Upon receiving a text prompt from a client, the generate_text tool uses the loaded Granite model to generate a textual response based on that prompt. This server then listens for incoming connections from MCP clients, ready to execute the registered tools whenever a request arrives.
As always, before implementing any code, we build our virtual environment.
python3.12 -m venv myenv
source myenv/bin/activateThe next step is to install all required librairies (sorry no requirement.txt here…😓).
# Using the python package
pip install --upgrade pip
pip install mcp transformers uv
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install 'numpy<2.0'Now let’s see the server.py (not very sophisticated, I acknowledge)!
# server.py
from mcp.server.fastmcp import FastMCP
from transformers import AutoModelForCausalLM, AutoTokenizer
server = FastMCP("SampleAgentServer")
model_name = 'ibm-granite/granite-3.3-2b-base'
tokenizer = None
model = None
async def load_model():
global tokenizer, model
if tokenizer is None:
tokenizer = AutoTokenizer.from_pretrained(model_name)
if model is None:
model = AutoModelForCausalLM.from_pretrained(model_name)
@server.tool()
async def generate_text(prompt: str) -> str:
"""Generate text based on the given prompt using a local LLM."""
await load_model()
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
if __name__ == "__main__":
server.run()Take a closer look to the “outputs” line, this is kind of limitation you impose for generated answers. You can play with it! For example;
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)The MCP Client
The client.py script demonstrates how to interact with an MCP server. It establishes a connection to the server.py (here, by launching it as a subprocess using uv).
Once the connection is established and an MCP session is initialized, the client can discover and call the tools offered by the server. In this specific example, the client calls the generate_text tool, providing the prompt “Write a short story about a robot learning to write a medium article or blog post.”
It then waits for the server’s response, which contains the generated text from the Granite model, and prints this response to the console. This script showcases the fundamental process of a client making a request to an MCP server and receiving the result.
The code is provided below.
# client.py
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
import os
async def main():
server_params = StdioServerParameters(
command="uv",
args=["run", "server.py"],
env=os.environ,
)
async with stdio_client(server_params) as (reader, writer):
async with ClientSession(reader, writer) as session:
await session.initialize()
response = await session.call_tool("generate_text", {"prompt": "Write a short story about a robot learning to write a medium article or blog post."})
print("Generated Text:")
if response and response.content:
print(response.content[0].text)
else:
print("No response received from the server.")
if __name__ == "__main__":
asyncio.run(main())The Agent
The agent.py script represents a simple application that leverages the capabilities exposed by the MCP server. Internally, it contains the logic to act as an MCP client, similar to client.py.
Its primary function is to query the language model hosted by the server for a specific task. In this case, it formulates a user query (“Describe me Quantum Computing concepts.”) and then uses the MCP client mechanism to send this query to the generate_text tool on the server.py.
Finally, it receives the joke generated by the Granite model from the server and prints both the original user query and the agent’s response (‘Quantum Computing concepts’) to the console, demonstrating a basic interaction flow where an agent utilizes the LLM’s abilities.
# agent.py
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
import os
async def query_llm(prompt: str):
server_params = StdioServerParameters(
command="uv",
args=["run", "server.py"],
env=os.environ,
)
async with stdio_client(server_params) as (reader, writer):
async with ClientSession(reader, writer) as session:
await session.initialize()
response = await session.call_tool("generate_text", {"prompt": prompt})
if response and response.content:
return response.content[0].text
else:
return "Failed to get a response."
async def main():
user_query = "Describe me Quantum Computing's concepts."
llm_response = await query_llm(user_query)
print(f"User Query: {user_query}")
print(f"Agent Response: {llm_response}")
if __name__ == "__main__":
asyncio.run(main())Running all these parts together
In order to test the server, client and the agent, run them one after another.
# python server.py
########
# python client.py
python client.py ✔ took 11s base at 12:43:35 ▓▒░
[04/18/25 12:45:12] INFO Processing request of type CallToolRequest server.py:534
model.safetensors.index.json: 100%|███████████████████████████████████████████████████████████████████| 29.8k/29.8k [00:00<00:00, 21.9MB/s]
model-00002-of-00002.safetensors: 100%|███████████████████████████████████████████████████████████████| 67.1M/67.1M [00:06<00:00, 10.3MB/s]
model-00001-of-00002.safetensors: 100%|███████████████████████████████████████████████████████████████| 5.00G/5.00G [04:10<00:00, 19.9MB/s]
Fetching 2 files: 100%|█████████████████████████████████████████████████████████████████████████████████████| 2/2 [04:10<00:00, 125.50s/it]
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████| 2/2 [00:12<00:00, 6.00s/it]
generation_config.json: 100%|██████████████████████████████████████████████████████████████████████████████| 132/132 [00:00<00:00, 684kB/s]
Generated Text:
Write a short story about a robot learning to love.
Once upon a time, in a bustling city filled with humans and robots, there lived a robot named Robo. Robo was a simple machine, designed to perform tasks with precision and efficiency. However, as time passed, Robo began to feel a sense of longing for something more...
########
# python agent.py
python agent.py ✔ took 1m 6s base at 12:53:34 ▓▒░
[04/18/25 12:59:18] INFO Processing request of type CallToolRequest server.py:534
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████| 2/2 [00:07<00:00, 3.87s/it]
/Users/alainairom/miniforge3/lib/python3.12/multiprocessing/resource_tracker.py:255: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
User Query: Describe me Quantum Computing's concepts.
Agent Response: Describe me Quantum Computing's concepts.
Quantum computing is a field of study that leverages the principles of quantum mechanics to process information. Unlike classical computers that use bits (0s and 1s) to process information, quantum computers use quantum bits, or qubits. Qubits can exist in multiple states at once, thanks to a property called superposition. This allows quantum computers to perform complex calculations much faster than classical computers...You can get rid of the models on your local machine later on if you need regain the lost space of your hard drive (example below)!
~/Library/Caches/huggingface/transformers/As we see, these three components work together in a coordinated manner. The server.py acts as the service provider, offering the text generation capability powered by the Granite model. The client.py (and the client logic within agent.py) acts as the consumer, initiating requests to the server to utilize its tools. The agent.py specifically demonstrates a use case where an application (the agent) needs the language model’s generative abilities to fulfill a task. The client sends a structured request to the server (tool name and parameters), the server processes this request by running the LLM, and the result is sent back to the client, enabling the agent to provide a response to the user.
Conclusion 1
These sample scripts provide a working blueprint for building applications that harness the power of locally hosted LLMs through the Model Context Protocol. We’ve seen how an MCP server can expose the text generation capabilities of a model like Granite, and how clients and agents can interact with this server to perform tasks. While this is a basic example, it lays the groundwork for more sophisticated systems where multiple agents can interact with various LLM-powered tools, fostering a collaborative and intelligent ecosystem. Further development could involve adding more tools to the server, implementing more complex agent logic, and refining the communication between the client and server for enhanced functionality and robustness.
My thoughts (conclusion 2)…
In conclusion, while the exercise of building a rudimentary MCP server and client from scratch provides invaluable insight into the underlying concepts and mechanisms of model interaction, the practicality of deploying such a custom solution in a real-world scenario is questionable. The landscape of open-source (or commercial) tools offers robust, well-tested, and often highly optimized frameworks for serving and accessing language models. For industrial-grade, scalable solutions, established platforms and services with mature infrastructure and comprehensive features would undoubtedly be the preferred choice. Nevertheless, the in-depth knowledge gained from understanding the fundamental principles demonstrated in these sample applications is more than primordial. It equips developers with the necessary conceptual foundation to effectively leverage these more sophisticated tools and to troubleshoot and customize solutions with a deeper understanding of the core processes at play.
Thanks for reading 🤗!
Links
- IBM Granite models: https://huggingface.co/ibm-granite
- Model Context Protocol: https://github.com/modelcontextprotocol