This is a Plain English Papers summary of a research paper called MedHal: New Dataset Flags Medical AI Lies - Can AI Detect False Health Info?. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
MedHal: A New Dataset for Detecting Medical Hallucinations in AI Systems
Hallucinations in AI-generated content present significant challenges, especially in the medical domain where inaccurate information can have serious consequences. While current hallucination detection methods work reasonably well for general content, they fall short when applied to specialized domains like medicine.
Researchers from Polytechnique Montreal and Mila have introduced MedHal, a large-scale dataset specifically designed to evaluate if models can detect hallucinations in medical texts. This resource addresses critical gaps in existing medical hallucination datasets, which are typically too small or too narrowly focused on single tasks.
The Critical Need for Better Medical Hallucination Detection
Current approaches to hallucination detection in medicine rely heavily on expert review—a process that is both costly and time-consuming. Existing evaluation datasets suffer from significant limitations: they either contain only a few hundred samples (insufficient for training models) or focus on narrow tasks like Question Answering.
MedHal addresses these gaps through three key innovations:
- Incorporating diverse medical text sources and tasks
- Providing a substantial volume of annotated samples suitable for training
- Including explanations for factual inconsistencies to guide model learning
The researchers demonstrate MedHal's utility by training and evaluating a baseline medical hallucination detection model, showing significant improvements over general-purpose hallucination detection approaches.
How MedHal Transforms Medical Datasets
The researchers developed a unified approach to transform existing medical datasets from various tasks—question answering, information extraction, natural language inference, and summarization—into a standardized hallucination detection framework.
Each sample in MedHal follows a consistent structure:
- Statement: A proposition to be classified as factual or non-factual
- Context (optional): Contextual information relevant to the statement
- Factual label: A binary indicator (Yes/No)
- Explanation: For non-factual statements, details about the inconsistency
| Task | Datasets | Sample | Generated Statement |
|---|---|---|---|
| Information Extraction |
Augmented- Clinical Notes |
A 10-year-old girl first noted a swollen left knee and underwent repeated arthrocentesis. She underwent arthroscopic surgery and was diagnosed with ... $\rightarrow$ age: 10 years old | The patient is 10 years old. |
| Summarization | SumPubMed | the large genotyping studies in the last decade have revolutionize genetic studies. our current ability to ... $\rightarrow$ genetic admixture is a common caveat for genetic association analysis. these results... | genetic admixture is a common caveat for genetic association analysis. these results... |
| NLI | MedNLI | Labs were notable for Cr 1.7 (baseline 0.5 per old records) and lactate 2.4. $\rightarrow$ Patient has normal Cr | Patient has normal Cr |
| QA | MedQA, MedMCQA |
Which of the following medications is most commonly used as first-line treatment for newly diagnosed type 2 diabetes mellitus in patients without contraindications? $\rightarrow$ Metformin | Metformin is most commonly used as first-line treatment for newly diagnosed type 2 diabetes mellitus in patients without contraindications. |
Examples of how statements are generated from samples across different task types
Creating Hallucination Examples from Medical Questions
For question-answering datasets, the researchers transformed questions and their correct answers into factual statements using a large language model. To create hallucinated samples, they paired questions with incorrect answers and converted these into statements.
| Sample Type | Question | Answer | Generated Statement |
|---|---|---|---|
| Factual | Which of the following medications is most commonly used as first-line treatment for newly diagnosed type 2 diabetes mellitus in patients without contraindications. | Metformin | Metformin is most commonly used as first-line treatment for newly diagnosed type 2 diabetes mellitus in patients without contraindications. |
| Non-Factual | Insulin | Insulin is most commonly used as first-line treatment for newly diagnosed type 2 diabetes mellitus in patients without contraindications. |
Example of Question-Answering Dataset Transformation
Leveraging Clinical Information Extraction
For information extraction datasets (like clinical notes), the researchers used source documents as context and corresponding extractions as statements. To generate non-factual samples, they randomly interchanged extractions between different documents.
| Sample Type | Source Document |
Extraction | Statement | Explanation |
|---|---|---|---|---|
| Factual | A 10-year-old girl first noted a swollen left knee and underwent repeated arthrocento- sis... |
age: 10 years old | The patient is 10 years old |
- |
| Non-Factual | A 10-year-old girl first noted a swollen left knee and underwent repeated arthrocente- sis... |
age: 16 years old | The patient is 16 years old |
The patient is 10 years old |
Example of Information Extraction Dataset Transformation
Detecting Small Errors in Medical Summaries
For summarization datasets, the researchers used genuine summaries as factual samples. To create hallucinated samples, they extracted a sentence from the original summary and modified it to introduce contradictory information.
| Sample Type | Source Document |
Summary | Statement | Explanation |
|---|---|---|---|---|
| Factual | a central feature in the maturation of hearing is a transition in the electrical signature of cochlear hair cells from spontaneous calcium... | cochlear hair cells are high-frequency sensory receptors... | cochlear hair cells are high-frequency sensory receptors... | - |
| Non-Factual | cochlear hair cells are low-frequency sensory receptors... | According to the source document, cochlear hair cells are high-frequency sensory receptors... |
Example showing how hallucinations are introduced into medical summaries
Dataset Composition and Scale
MedHal incorporates a diverse range of datasets spanning multiple tasks and content types. The resulting dataset includes over 348,000 samples, significantly larger than existing medical hallucination datasets.
| Dataset | Task | S | Content Type | Source | # Samples | # Gen |
|---|---|---|---|---|---|---|
| MedMCQA | QA | $\boldsymbol{x}$ | Medical Content | Pal et al. (2022) | 183,000 | 70,730 |
| MedNLI | NLI | $\boldsymbol{x}$ | Clinical Notes | Herlihy & Rudinger (2021) | 11,232 | 7,488 |
| ACM | IE | $\checkmark$ | Clinical Notes | Bonnet & Boulenger (2024) | 22,000 | 73,040 |
| MedQA | QA | $\boldsymbol{x}$ | Medical Content | Jin et al. (2020) | 12,723 | 18,906 |
| PubMedSum | Sum | $\boldsymbol{x}$ | Clinical Trials | Gupta et al. (2021) | 33,772 | 178,657 |
Overview of datasets used to generate MedHal (S indicates whether the source dataset is synthetic)
Evaluating Model Performance on MedHal
The researchers evaluated several models on MedHal, including general-purpose LLMs and medical-specific models. They also fine-tuned a small (1 billion parameter) Llama model on the MedHal dataset to create a baseline detector.
Two types of metrics were used to evaluate performance:
- Factuality metrics: precision, recall, and F1-score
- Explanation metrics: BLEU and ROUGE scores to evaluate the quality of explanations
| FT | Type | Models | Factuality | Explanation | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | F1 | BLEU | R1 | R2 | |||
| $\boldsymbol{x}$ | General | Llama-1B-Instruct | 0.53 | 0.32 | 0.40 | 0.01 | 0.13 | 0.03 |
| Llama-8B-Instruct | 0.59 | 0.62 | 0.60 | 0.05 | 0.24 | 0.14 | ||
| Medical | BioMistral-7B | 0.56 | 0.43 | 0.49 | 0.03 | 0.22 | 0.11 | |
| MedLlama-8B | 0.52 | 0.59 | 0.55 | 0.03 | 0.21 | 0.08 | ||
| OpenBioLLM-8B | 0.52 | 0.77 | 0.62 | 0.04 | 0.21 | 0.10 | ||
| $\checkmark$ | General | MedHal-Llama (Ours) | 0.75 | 0.77 | 0.76 | 0.45 | 0.70 | 0.59 |
Results of various models on the MedHal test set (FT: Fine-Tuned, P: Precision, R: Recall)
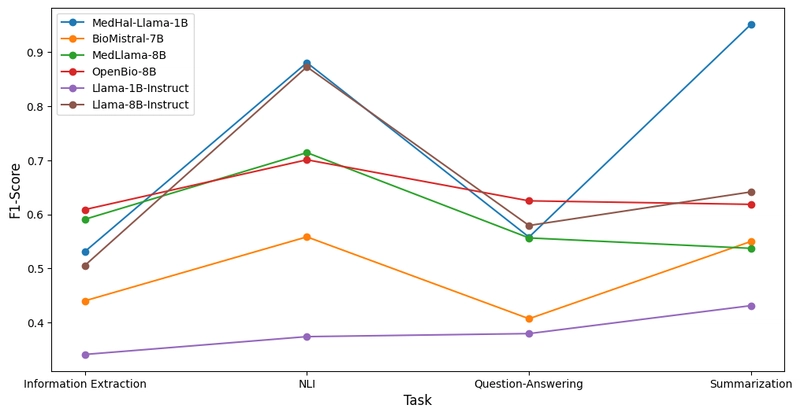
Performance comparison across different source datasets in MedHal
Surprising Insights from Model Performance
The evaluation revealed several unexpected findings. General-purpose models demonstrated surprising aptitude for identifying medical inaccuracies, with Llama-8B-Instruct achieving the highest precision (0.59) among non-fine-tuned models.
In contrast, specialized medical models—despite extensive domain-specific training—often performed worse at hallucination detection. Only OpenBioLLM-8B demonstrated relatively strong performance with an F1-score of 0.62, though it showed higher recall than precision, suggesting a tendency to overclassify statements as factual.
Another unexpected finding was that general-purpose models outperformed medical models in generating explanations for hallucinations. Manual evaluation revealed this was partly because medical models often failed to follow instructions to explain their judgments.
Task-Specific Performance Variations
Performance varied significantly across different data sources and tasks. Information extraction proved challenging for all models—even the fine-tuned MedHal-Llama performed only slightly better than random chance. The researchers hypothesize this might be due to the synthetic nature of the information extraction dataset.
Interestingly, the researchers found no significant performance difference between tasks requiring contextual analysis (like summarization) and tasks operating on isolated statements (like question-answering). This suggests that the presence or absence of context doesn't substantially impact hallucination detection capability.
The Impressive Impact of Fine-Tuning
One of the most striking findings was the performance of the fine-tuned MedHal-Llama model. Despite having only 1 billion parameters, this model significantly outperformed much larger models (7-8B parameters), including those with extensive medical domain fine-tuning.
The MedHal-Llama model achieved a 0.76 F1-score on factuality detection—substantially higher than the best non-fine-tuned model (0.62). It also excelled at generating explanations for hallucinated content, with explanation metrics 5-10x higher than other models.
This finding suggests that specialized medical fine-tuning alone doesn't guarantee strong performance in hallucination detection. A smaller model specifically trained on hallucination detection can outperform larger, more generally trained medical models.
Limitations and Future Directions
The researchers acknowledge several limitations of their approach. Most significantly, MedHal relies on generated content, with validity assessed primarily through visual inspection of samples. Ideally, comprehensive evaluation by medical professionals would further validate the dataset's accuracy and clinical relevance.
Additionally, the dataset is imbalanced across different tasks, with summarization samples over-represented. Future work should focus on balancing the dataset to ensure more equitable evaluation.
Advancing Medical AI Safety
MedHal represents a significant step forward in addressing the critical challenge of hallucination detection in medical AI. By providing a large-scale, diverse dataset that spans multiple medical text types and tasks, it enables more effective training and evaluation of hallucination detection models.
The impressive performance of the fine-tuned MedHal-Llama model demonstrates that even relatively small models can achieve strong performance when specifically trained on this task. This approach could significantly reduce the cost and effort associated with medical AI research while improving safety.
As the field of medical hallucination detection continues to evolve alongside other domain-specific approaches like vision-based medical hallucination detection, resources like MedHal will play a crucial role in developing more reliable and trustworthy medical AI systems.
