Hi y’all, it’s Creamy again🌷✨ long time no blog!
I know I’ve been real quiet on here, blame it on endless studying, deadlines, and debugging nightmares🐻💀
But finally, something cool happened that’s totally worth sharing!
A few days ago, I got the chance to join an invited talk with University of Waterloo on the topic:
“Meta Concerns in ML Security and Privacy.”
At first, I thought it was gonna be another typical boring session, but turns out, this talk went way deeper which is really interesting, and honestly made me rethink a lot of things about AI security 🤯
But hey, since this is a blog and I don’t wanna bore y’all with a wall of technical jargon, I’m just gonna summarize the coolest things I learned and why I think they’re super relevant for anyone working on or using machine learning today. Let’s dive in !! (lemme cook🔥)
Ok but first... Why are we even talking about "meta" concerns???
So like… AI is being used in every field and literally everywhere now like predicting diseases, detecting fraud, debug the code, and even use in cybersecurity field too😅 and in my opinion, honestly it’s the most powerful and helpful tool in these day for real!!
But the question is.....
how can we protect them if they’re under attack?
This talk didn’t just throw around random hacks or fixes. Instead, it zoomed way out to explore the meta problems, the big-picture stuff which is really important because protecting machine learning models isn’t just about slapping on quick fixes or random hacks, it’s about thinking in big picture and tackling the core issues. We need to understand who might want to mess with our models, whether they’re trying to steal them, manipulate them, or bypass our defenses. And while techniques like watermarking and fingerprinting can help, they’re not foolproof😞, malicious actors can still find ways to manipulate them. The real challenge is making sure that any defense we put in place actually holds up in the real world and doesn’t create new weaknesses. To truly protect our ML models, we need to think through all the possible threats, make sure our defenses work together, and keep our models as secure as possible!!
What kinds of attacks are we dealing with in nowadays?
Actually, from the talk, professor Asokan (The speaker) gave me a bunch of realistic threat models but here is a few example that I think y’all might be familiar:
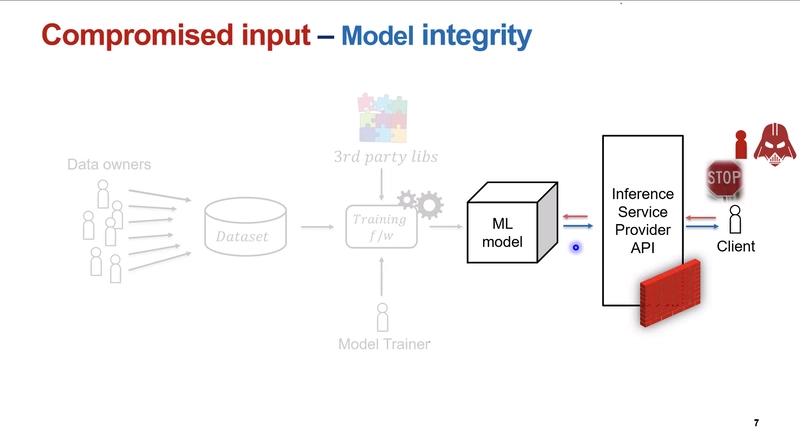
- Compromised Input (Model Integrity Attacks): Adversary gives malicious inputs to evade the model. Like tricking a spam filter or facial recognition system. There’s even a new attack that works on major AI chatbots and we don’t have a 100% fix yet.💀
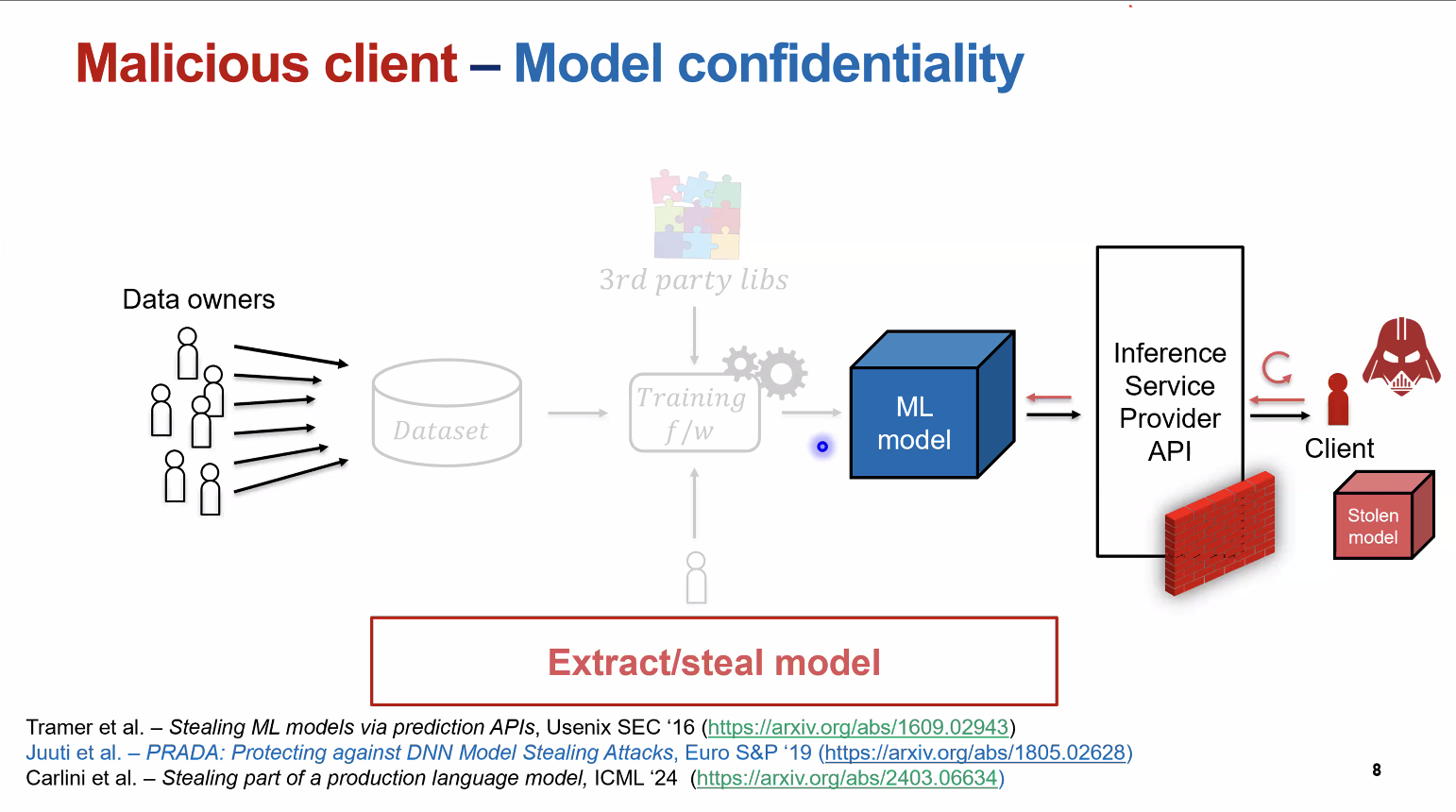
- Malicious Client (Model Confidentiality Attacks): In federated learning or API-based models, the attacker pretends to be a client and slowly extracts the model by querying it strategically.
Are We Using the Right Adversary Models?
When it comes to securing ML models, we need to ask ourselves if we're using the right adversary models. Model ownership resolution (MOR) must be strong enough to handle adversaries who are either trying to steal models or falsely claim ownership. There are two types of adversaries to consider:
- Malicious Suspects: These adversaries will try to get around verification using techniques like pruning, fine-tuning, or adding noise to the model.
- Malicious Accusers: These adversaries will falsely claim they own the model, trying to frame someone else.
One of my PSU professor asked the interesting question to professor Asokan that "what is the criteria to successfully steal the model?" he answered the simple answer that "well... if your stolen model performs nearly as well as the original, then yeah ,you basically succeeded in model theft" 💀
We also got a deep dive into one of the most slept-on topics in ML security: “Defending Model Ownership” and this part was super interesting. Like, let’s say you trained a ML model and someone steals it so...how the heck can even you prove it’s yours?
Well… here’s what I learned !👇🏻🎀
🔐 Watermarking ,aka “trap data” for model thieves
The idea is to sneak in some weird, carefully chosen data during training stuff like out-of-distribution (OOD) images with intentionally wrong labels. These are your watermarks.
Here’s how it works:
Watermark Generation
- Choose OOD samples and label them wrong on purpose
- Train your model with both normal data and watermark samples
- The model memorizes those strange labels
- Then, commit to this watermark by generating a timestamp (kind of like proof that you trained this version first)
Watermark Verification
- Test the suspect model with the same watermark samples.
- Compare its predictions to the incorrect labels: If the predictions match a lot, the model is likely stolen. If the predictions don’t match much, it’s probably not stolen. The timestamp helps verify if someone else is falsely claiming ownership.
sounds smart!!!!
Fingerprinting , like giving your model a secret ID
fingerprinting embeds a kind of unique identity into the model, like a digital signature or password.
It’s usually more robust than watermarking because there’s no obvious "trap" data involved, but:
implementing fingerprinting effectively can be complex, as it requires careful integration to avoid impacting the model’s performance. If not executed properly, it could lead to a reduction in the model's accuracy or efficiency. Therefore, while fingerprinting offers a stronger method for proving ownership, it demands careful attention to avoid unintended consequences.😎
Mitigating False Claims Against MORs
Watermarking is a good defense, but it has its own challenges. For one, generating and verifying watermarks or fingerprints can be a bottleneck. Verifying the watermark properly can be expensive and difficult. So, improving the ability to defend against false claims is something we still need to work on.
So yeah… model ownership resolution (MORs) sounds great on paper, but in practice? Still need to be improved anyways...
💀Meta Problem: Sensible Adversary Models
It’s important to identify the right adversary models and figure out what they’re trying to do. This includes looking at the adversary’s knowledge and capabilities, such as:
- Data Access
- Target Model Access
- Adversary Type (e.g., malicious accuser vs. malicious suspect)
- Interaction Type (e.g., zero-shot, one-shot, etc.)
When we talk about adversaries, we should avoid using vague terms. For example, calling everything “adversarial attacks” or saying an adversary is “adaptive” without specifying what they can actually do doesn’t help us understand the real threats.
Can We Deploy Defense Against Multiple Concerns?
One major challenge in ML security is how to protect against multiple risks at once. In previous research, defenses have focused on specific risks, but in real-life applications, we need to defend against a mix of threats.
Unintended Interaction: Different defenses might clash with each other, making things worse or introducing new vulnerabilities. For example, one defense might make the model more susceptible to a different attack.
Defense vs. Other Risks: We need to understand how a defense can influence the model's susceptibility to other unrelated risks.
ok last but not least....
Takeaways, for y'all 😎
Are we using the right adversary models?
This is a work in progress. Currently, there's a gap in robustness against false accusations in Model Ownership Resolution (MORs). We also don’t have widely accepted, streamlined adversary models in the ML security/privacy space. This needs to be addressed to improve how we defend against attacks and ensure trust in models.Can we deploy defenses against multiple concerns?
Another big challenge. Right now, defenses are often designed for specific risks, but we don’t fully know how they interact when combined. Some might even worsen other vulnerabilities. It’s important to figure out how to deploy multiple defenses in a way that they don't cancel each other out or create new weaknesses.
Tip🔥: You can use Amulet which is a toolkit designed for exploring different attacks and defenses, and it’s available as open-source. It’s a great resource for testing and understanding various security risks in ML models, and it can help you experiment with defenses in a more controlled way.😎
Final thoughts about this talk😎🔥
This talk honestly changed how I think about AI security. It’s not just about stopping bad guys, it’s about building systems we can actually trust in messy, realistic environments.
If you’re working on ML security or privacy, or even just using AI in your project, ask yourself:
Are we solving the right problems, or just the easy ones?
I feel like i'm gonna keep learning more in this area for sure. Hit me up if you’re also into privacy-preserving AI or model protection too!!!!,maybe we can build something cool together 😎
And hey ,this is just episode one! I’ve got another blog coming soon on “Lamination verification: verifying ML property cards using hardware-assisted attestations” ,so stay tuned🔥 if you’re curious about the hardware side of trustworthy AI 🛠️💻