Microservices Call Patterns focus on improving reliability of a single network call, such as retry and cache.
Microservices Reliability Playbook
- Introduction to Risk
- Introduction to Microservices Reliability
- Microservices Patterns
- Read Patterns
- Write Patterns
- Multi-Service Patterns
- Call Patterns
Download the full Playbook at a free PDF
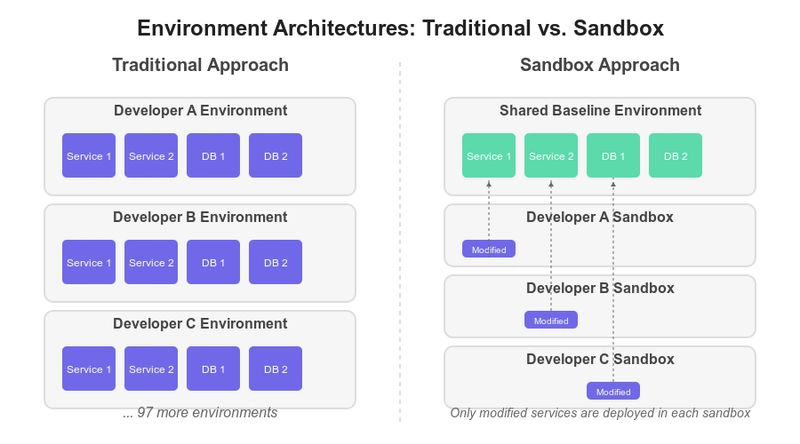
Pass Through Cache Pattern
The Pass Through Cache Pattern is using a cache service in front of a microservice. The cache has three functions - improves performance, improves reliability and, in addition, can answer for cached data even if the microservice is not available. Most cache systems are designed to be five-nines, with a single network call to fetch cached data (if not served from memory).
The cache pattern however has a few fundamental problems that limit its ability to improve reliability.
- Not all microservice API calls can be cached. In a nutshell, we can only cache read operations that are slowly changing.
- Cache systems are statistical systems, caching only part of the API calls. As a result, in case of a problem with the underlying system, a cache system can only support the cached data.
- Cache systems are designed to be non persistent. On updates, flush or other events the cache system may have small amount of cached api calls, again limiting it ability to improve reliability
- A Cache system incurs one additional network call to the cache system, which is required regardless of cache hit or miss.
- All the above amounts to a challenge to comprehend why some operations are cached and some are not, creating a potentially unexpected pattern of errors for the upstream system calling the cache.
As a result, to calculate the predicted reliability of a system with cache, we need to compute the predicted reliability of the system with a cache hit and without a cache hit, factoring in the additional network call to the cache system, and combine using weighted average the predicted reliability. The formula for predicted reliability becomes

Yes, the formula becomes quite complicated, and if we have multiple cache systems it becomes even more difficult to comprehend - hence the complication of comprehending reliability of systems with cache.
Retry Pattern
The retry pattern is a simple way to handle some failures and improve reliability. Why some? As a general rule, retry handles momentary outages we denote here as risk of load and latency, but fail to handle (in most cases) the outages due to risk of change.
Outages caused by load and latency tend to be momentary - and another try even 1ms later can succeed where the previous one failed. However, outages caused by change tend to take minutes to tens of minutes to fix, and in some cases more. As a result, retrying a few milliseconds later will most probably hit the same outrage caused by change.
Retry also implies the operation to retry is idempotent - it is designed to be retied. Read operations are idempotent by definition, while operations with side effects, persistence, data updates, inserts or deletes are by default not idempotent. However, in some cases such operations can be modelled as idempotent.
Mutation operations can be made idempotent using an operation key by checking if an operation with the key already happened. While this sounds very generic, we all know a few implementations of this general idea - such as using a transaction id, optimistic locking or update by insert with client provided primary key value. The common among all is that if we retry, while the original request has succeeded, the second can be detected using the key value and handled accordingly (for instance, prevent the double doing while returning a success to the client).
- Transaction_id - the providing service on receiving a mutation operation with a transaction id, first writes it to a write ahead log and then processes the mutation to other tables. If the transaction id already exists in the write ahead log, a duplicate key error is potentially ignored.
- Optimistic locking - the providing service checks the client supplied version, and if that version does not match the current version + 1, it rejects the operation. On retry, if the previous attempt worked, the version number has already advanced and the second try will fail.
-
Update by insert - The providing service does an insert into a log table (similar to transaction id) instead of an update. For instance, consider an inventory system that on checkout updates the inventory to have one less product. An update operation of
update inventory set product_inventory = product_inventory - countis not idempotent. However, an insert operation ofinsert into ordered_inventory (product_id, order_id, count) values (?, ?, ?)is idempotent if we have a primary key or unique index onproduct_id, order_id.
What is the effect of retry on predicted reliability? First, it only affects the ‘risk of load and latency’ component, and then it reduces the risk divided by the number of retries.
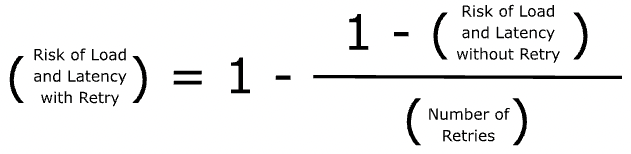
Fallback Pattern
The fallback pattern recognizes that risk exists and things can fail. Once something does fail, the system is designed to do something different, such as fallback to another service, to another product flow or to shutdown a feature.
Fallback can be implemented as
- Fallback of a certain microservice can be an equivalent microservice deployed into another data center, another cloud, another zone (handles risk of load and latency)
- Fallback of a certain microservice can be a delayed deployed microservice, such as 1 week ago version (handles risk of change, yet requires forward / backward compatibility)
- Fallback of a certain microservice can be another implementation of the microservice using another software stack or another SaaS provider, like another payment provider, another type of cloud database, another email provider, etc. We can have multiple providers with different transaction prices, trying the more cost effective first, and if that fails, use the more costly option.
- Fallback can be by changing functionality - if we detect the email service fails, we can try the SMS service instead.
- Fallback can be by shutting down a feature - if the coupon service fails, we can block the ability to add coupons on checkout. If the shipping calculator service fails, we can show the cart without shipping cost and show a message that shipping costs will be provided using email soon, or we can use a generic average shipping code.
The impact of a fallback pattern improves reliability by handling the error cases, and turning them into another valid flow. While the fallback itself can fail, the reality is that the end result is way more reliable.
The predicted reliability of a system with a fallback becomes
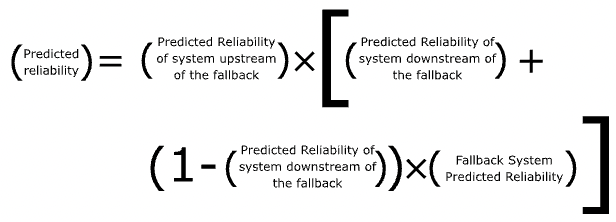
In the formula above, we break the system to anything before the microservice with a fallback pattern implemented (upstream system) and anything after (downstream system). The fallback only handles features of the downstream system, compensating given its own reliability.
Circuit Breaker
The Circuit Breaker pattern is a pattern to ensure a downstream subsystem load does not exceed a certain limit, or that a specific customer / tenant / client consumes all the resources and creates a “denial of service” equivalent on the downstream system.
When a circuit breaker is activated, it is knowingly causing errors, like 429 too many requests or 504 timeouts. Circuit Breaker creates a clear cutoff point at which client services experience and can expect a failure, falling back to another flow.
Consider for instance a personalized recommended products service, which gives product recommendations adapted specifically for each user on a product page. If this service fails or is overloaded, a circuit breaker can be activated to prevent additional load on the service. A fallback can be to hide the recommended products section in the product page, or show a cached generic (not personalized) recommended products.
We have to ask - why is Circuit Breaker considered a reliability pattern if it creates errors? The Circuit Breaker protects a downstream system from resource exhaustion and improves the reliability for other clients of the downstream system.
Circuit Breaker can be implemented as
- A limit of API calls per client per period of time.
- A backoff on the number of errors or rate of errors from the downstream system, triggering the circuit breaker for a period of time.
- A backoff on downstream system load, such as downstream system returns 429 or 504 HTTP status (or equivalent), enabling the downstream system cooldown for a period of time.