This is a Plain English Papers summary of a research paper called MLLMs vs. Human Talk: New Benchmark Tests If AI 'Gets' Us. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Understanding Human Communication: The Challenge of Multimodal Language Analysis
Multimodal language analysis represents a rapidly evolving field that decodes high-level cognitive semantics in human utterances by leveraging multiple modalities (text, audio, video). This capability is crucial for applications like virtual assistants, recommender systems, and social behavior analysis. Despite the importance of understanding these complex semantics, there's been limited research into how well current multimodal large language models (MLLMs) comprehend cognitive-level meaning in human conversations.
The MMLA (Multimodal Language Analysis) benchmark addresses this gap as the first comprehensive framework designed to evaluate how well large language models and multimodal large language models understand complex conversational semantics across multiple modalities. Unlike existing benchmarks that focus mainly on perceptual-level tasks rather than cognitive understanding, MMLA provides a rigorous testbed for foundation models' ability to interpret human communication.
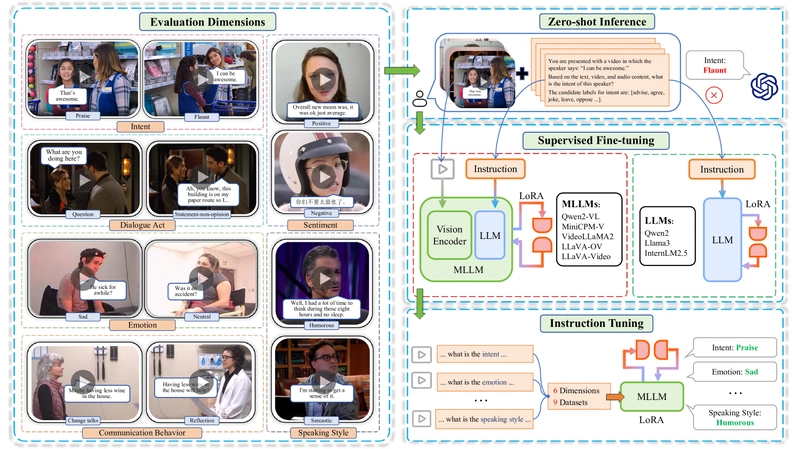
Overview of the MMLA benchmark showing six evaluation dimensions, nine datasets, and three evaluation methods.
The Evolution of Multimodal Language Understanding
Research in multimodal language analysis has evolved significantly over time. Early work focused primarily on sentiment and emotion recognition from social media videos and TV shows. Researchers then developed methods to learn complementary information across different modalities, addressing the challenge of their heterogeneous nature.
The field gradually expanded to more complex semantics like sarcasm and humor, with specialized fusion methods for binary classification tasks. More recently, researchers have begun analyzing coarse-grained and fine-grained intents using new datasets and taxonomies, though this area remains in its early stages.
Traditional multimodal fusion techniques built on lightweight neural networks show limited performance on complex reasoning tasks. With the advent of MLLMs, their scalable model parameters reveal enormous potential for cross-modal reasoning. However, existing MLLM benchmarks primarily focus on low-level perceptual semantics rather than high-level conversational understanding.
The MMLA benchmark specifically addresses this gap, providing the first comprehensive framework for evaluating foundation models on multimodal language analysis tasks.
The MMLA Benchmark: A Comprehensive Evaluation Framework
MMLA offers a comprehensive design covering six key dimensions across nine datasets, with over 61K multimodal utterances. This makes it one of the most extensive benchmarks for evaluating multimodal understanding capabilities of foundation models.
| Dimensions | Datasets | #C | #U | #Train | #Val | #Test | Video Hours |
Source | #Video Length avg. / max. | #Test Length avg. / max. | Language |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Intent | MIntRec | 20 | 2,224 | 1,334 | 445 | 445 | 1.5 | TV series | 2.4 / 9.6 | 7.6 / 27.0 | English |
| MIntRec2.0 | 30 | 9,304 | 6,165 | 1,106 | 2,033 | 7.5 | TV series | 2.9 / 19.9 | 8.5 / 46.0 | ||
| Dialogue | MELD | 12 | 9,989 | 6,992 | 999 | 1,998 | 8.8 | TV series | 3.2 / 41.1 | 8.6 / 72.0 | English |
| IEMOCAP | 12 | 9,416 | 6,590 | 942 | 1,884 | 11.7 | Improvised scripts | 4.5 / 34.2 | 12.4 / 106.0 | ||
| Emotion | MELD | 7 | 13,708 | 9,989 | 1,109 | 2,610 | 12.2 | TV series | 3.2 / 305.0 | 8.7 / 72.0 | English |
| IEMOCAP | 6 | 7,532 | 5,354 | 528 | 1,650 | 9.6 | Improvised scripts | 4.6 / 34.2 | 12.8 / 106.0 | ||
| Sentiment | MOSI | 2 | 2,199 | 1,284 | 229 | 686 | 2.6 | Youtube | 4.3 / 52.5 | 12.5 / 114.0 | English |
| CH-SIMS v2.0 | 3 | 4,403 | 2,722 | 647 | 1,034 | 4.3 | TV series, films | 3.6 / 42.7 | 1.8 / 7.0 | Mandarin | |
| Speaking | UB-FUNNY-v2 | 2 | 9,586 | 7,612 | 980 | 994 | 12.9 | TED | 4.8 / 325.7 | 16.3 / 126.0 | English |
| Style | MUNARD | 2 | 690 | 414 | 138 | 138 | 1.0 | TV series | 5.2 / 20.0 | 13.1 / 68.0 | |
| Communication | Anno-MI (client) | 3 | 4,713 | 3,123 | 461 | 1,129 | 10.8 | YouTube | 8.2 / 600.0 | 16.3 / 266.0 | English |
| Behavior | Anno-MI (throqvist) | 4 | 4,773 | 3,161 | 472 | 1,140 | 12.1 | & Vimeo | 9.1 / 1316.1 | 17.9 / 205.0 |
Dataset statistics for each dimension in the MMLA benchmark, showing the number of label classes, utterances, training/validation/testing samples, video hours, sources, average and maximum lengths of video and text, and languages.
What We're Measuring: Six Core Dimensions of Human Communication
The MMLA benchmark evaluates foundation models across six representative dimensions that encapsulate the core aspects of multimodal language analysis:
Intent: Captures the ultimate purpose or goal of human communication, such as requesting information or making decisions. The benchmark includes up to 30 intent classes commonly occurring in daily life.
Dialogue Act: Focuses on the dynamic progression of communication, such as questioning or stating opinions. It includes 12 commonly occurring classes selected from the SwitchBoard tag set.
Emotion: Conveys the speaker's internal psychological state (e.g., happiness, anger). The benchmark includes Ekman's six universal emotion categories, with some datasets adding a neutral class.
Sentiment: Refers to the polarity (e.g., positive or negative) of subjective opinions. The benchmark includes datasets with both binary and ternary sentiment classifications.
Speaking Style: Individual expressive variations in communication (e.g., sarcasm, humor). The benchmark includes binary classification tasks for humor and sarcasm detection.
Communication Behavior: Interaction behaviors between individuals that facilitate conversation progression. The benchmark includes datasets analyzing behaviors in counseling dialogues.
Nonverbal cues (gestures, facial expressions, eye contact) are crucial for interpreting each dimension, making this a perfect test for multimodal models versus text-only approaches.
Diverse and Rich Data: Nine Multimodal Language Datasets
The MMLA benchmark incorporates nine publicly available multimodal language datasets corresponding to the six evaluation dimensions. These datasets contain a wide variety of characters, scenes, and background contexts in both English and Mandarin.
The data sources include popular TV series (e.g., Friends, The Big Bang Theory), films, online video-sharing platforms (YouTube, Vimeo), idea-sharing platforms (TED), and scripted dyadic sessions. Together, they provide 61,016 high-quality multimodal samples, totaling 76.6 hours of video.
This diversity is crucial for a comprehensive evaluation, as different scenarios present unique challenges in interpreting human communication. Compared to other multimodal benchmarks, MMLA's datasets focus specifically on conversational understanding rather than general visual recognition or content analysis.
Evaluation Methodologies: Zero-shot, SFT, and Instruction Tuning
The MMLA benchmark employs three evaluation methods to comprehensively assess foundation models:
Zero-shot Inference: Tests models' ability to generalize without task-specific training. For LLMs, the prompt includes transcribed utterances followed by a task-specific query with candidate labels. For MLLMs, a special token aligns video input with text.
Supervised Fine-tuning (SFT): Optimizes models for specific tasks by minimizing cross-entropy loss between predicted and ground-truth tokens. The Low-Rank Adaptation (LoRA) technique reduces the number of parameters to be fine-tuned while preserving generalization capabilities.
Instruction Tuning (IT): Trains a single model to handle multiple tasks simultaneously. This tests whether foundation models can develop general understanding across diverse multimodal language tasks.
These three approaches provide a holistic view of model capabilities, from out-of-the-box generalization to specialized performance and multi-task learning.
Experimental Setup: Models, Metrics, and Implementation
The evaluation uses six commonly used metrics: accuracy (ACC), weighted F1-score (WF1), weighted precision (WP), macro F1-score (F1), recall (R), and precision (P).
The benchmark evaluates three types of models:
LLMs: Three series of text-only models including Llama-3 (8B), InternLM-2.5 (7B), and Qwen2 (0.5B, 1.5B, and 7B).
MLLMs: Five series of multimodal models including VideoLLaMA2 (7B), Qwen2-VL (7B and 72B), LLaVA-Video (7B and 72B), LLaVA-OneVision (7B and 72B), and MiniCPM-V-2.6 (8B). The closed-source GPT-4o is also evaluated in zero-shot settings.
SOTA MML Methods: State-of-the-art multimodal machine learning methods specific to each dataset for comparison.
The experiments use FlashAttention-2 to optimize attention modules, the DeepSpeed library for distributed training, and BF16 precision for reduced computational costs.
Key Findings: How Well Do Models Understand Multimodal Language?
The evaluation reveals several surprising insights about how foundation models perform on multimodal language analysis tasks.
Surprising Zero-Shot Results and the Power of Fine-Tuning
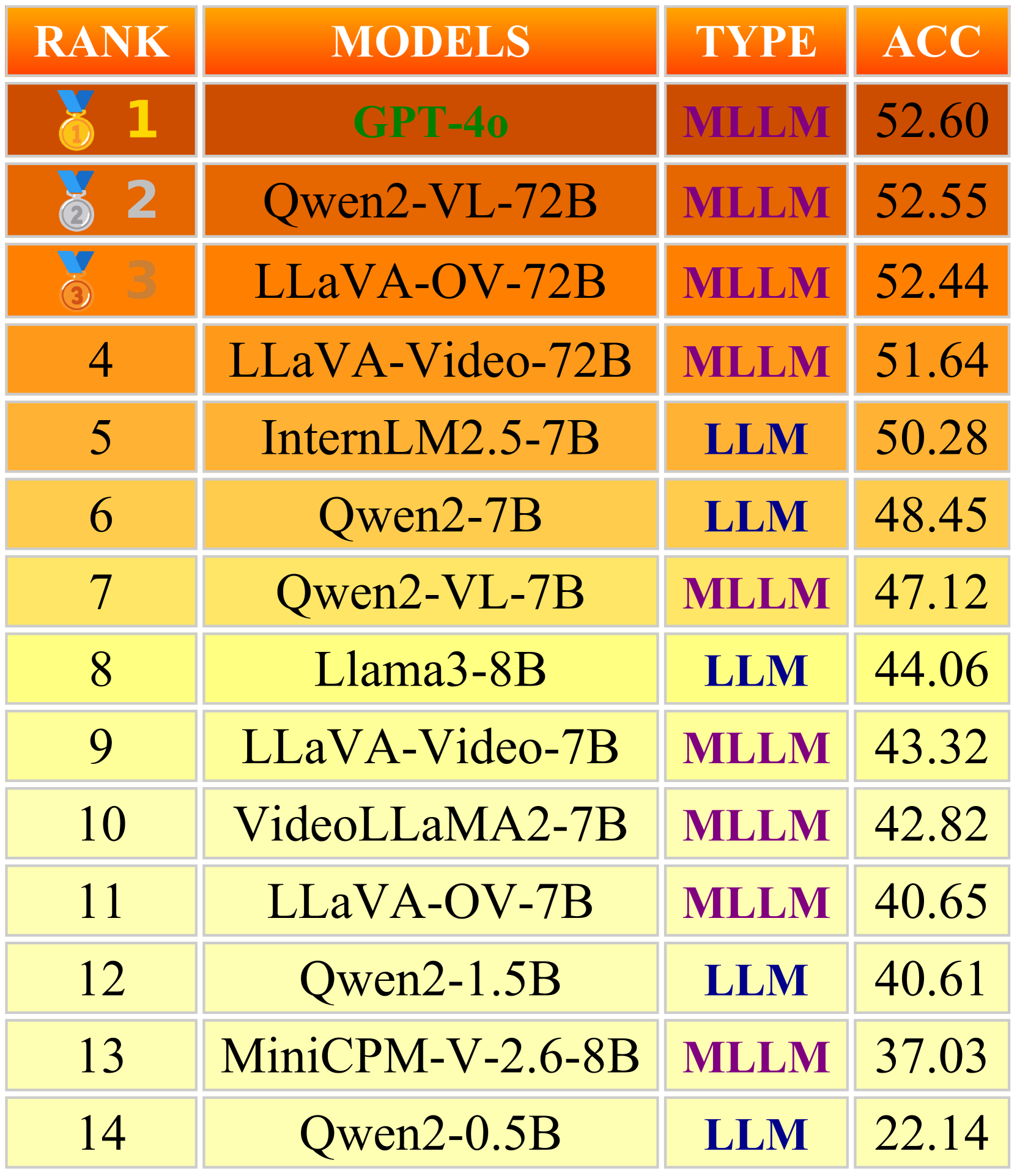
Ranking of foundation models based on zero-shot inference performance.
In zero-shot inference, the closed-source GPT-4o achieves the best performance, followed by the three open-source 72B MLLMs. However, the much smaller InternLM2.5-7B achieves comparable performance, within approximately a 2% difference.
Perhaps most surprising, among models with similar parameter scale (7B or 8B), most MLLMs actually perform worse than text-only LLMs. For example, InternLM2.5 and Qwen2 outperform most MLLMs (e.g., LLaVA-Video, VideoLLaMA2) by 5-8%. This indicates that existing MLLMs struggle to leverage non-verbal information for capturing complex high-level semantics without domain-specific training.
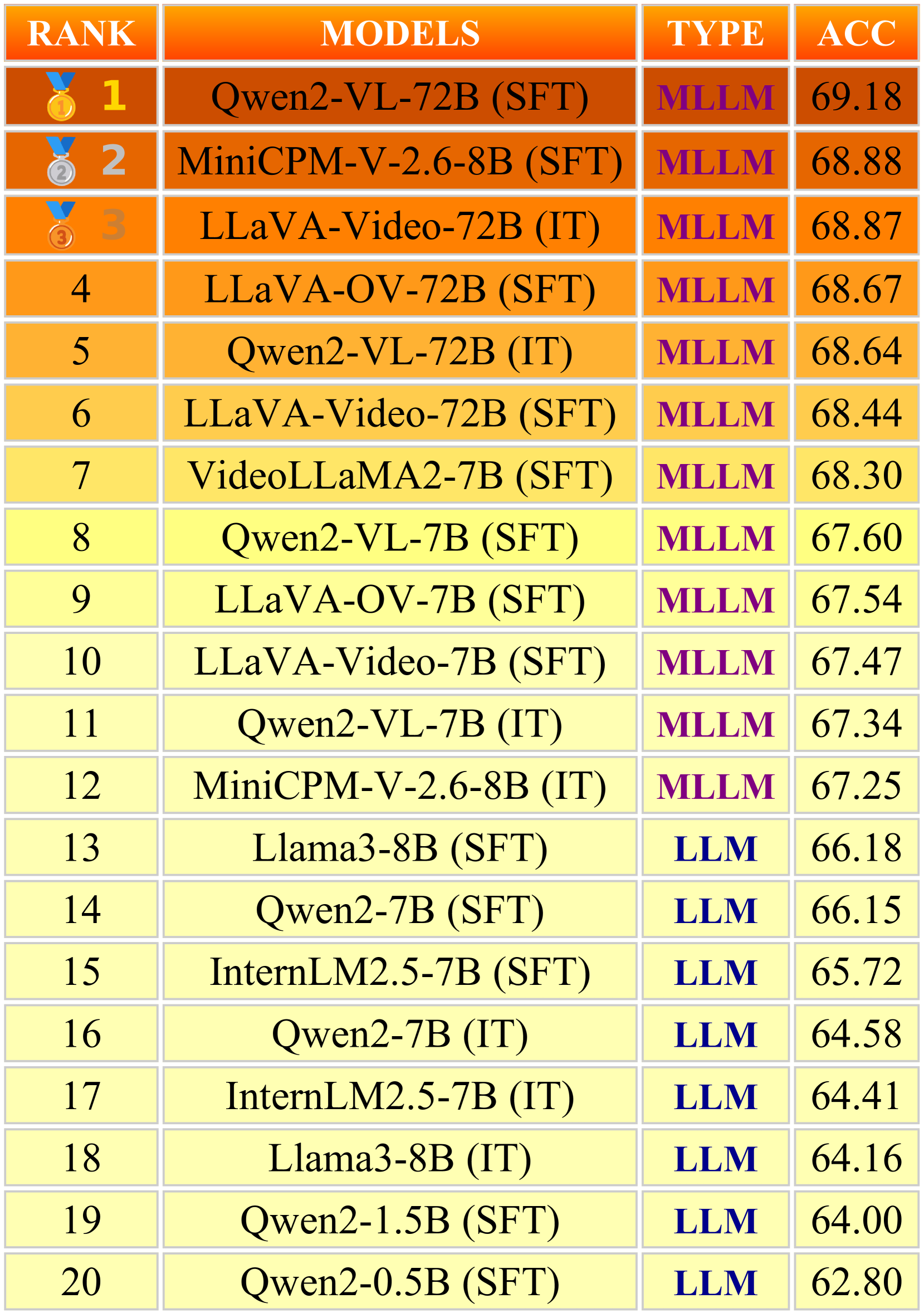
Ranking of foundation models after supervised fine-tuning (SFT) and instruction tuning (IT).
After supervised fine-tuning (SFT), the performance landscape changes dramatically. Parameter size matters far less once models are fine-tuned with domain-specific data. Models with 7B-8B parameters achieve accuracy scores within 1-2% of their 72B counterparts. The 8B MiniCPM-V-2.6 reaches second place after SFT, only 0.3% behind the top model (72B Qwen2-VL) and surpassing several much larger MLLMs.
Similarly, models trained with instruction tuning (IT) show comparable performance regardless of size, with 7B, 8B, and 72B MLLMs achieving accuracy scores within 2% of each other. This suggests that lightweight foundation models can effectively capture cognitive semantics with proper training, significantly reducing computational costs.
Performance Across Different Dimensions: Where Models Excel and Struggle
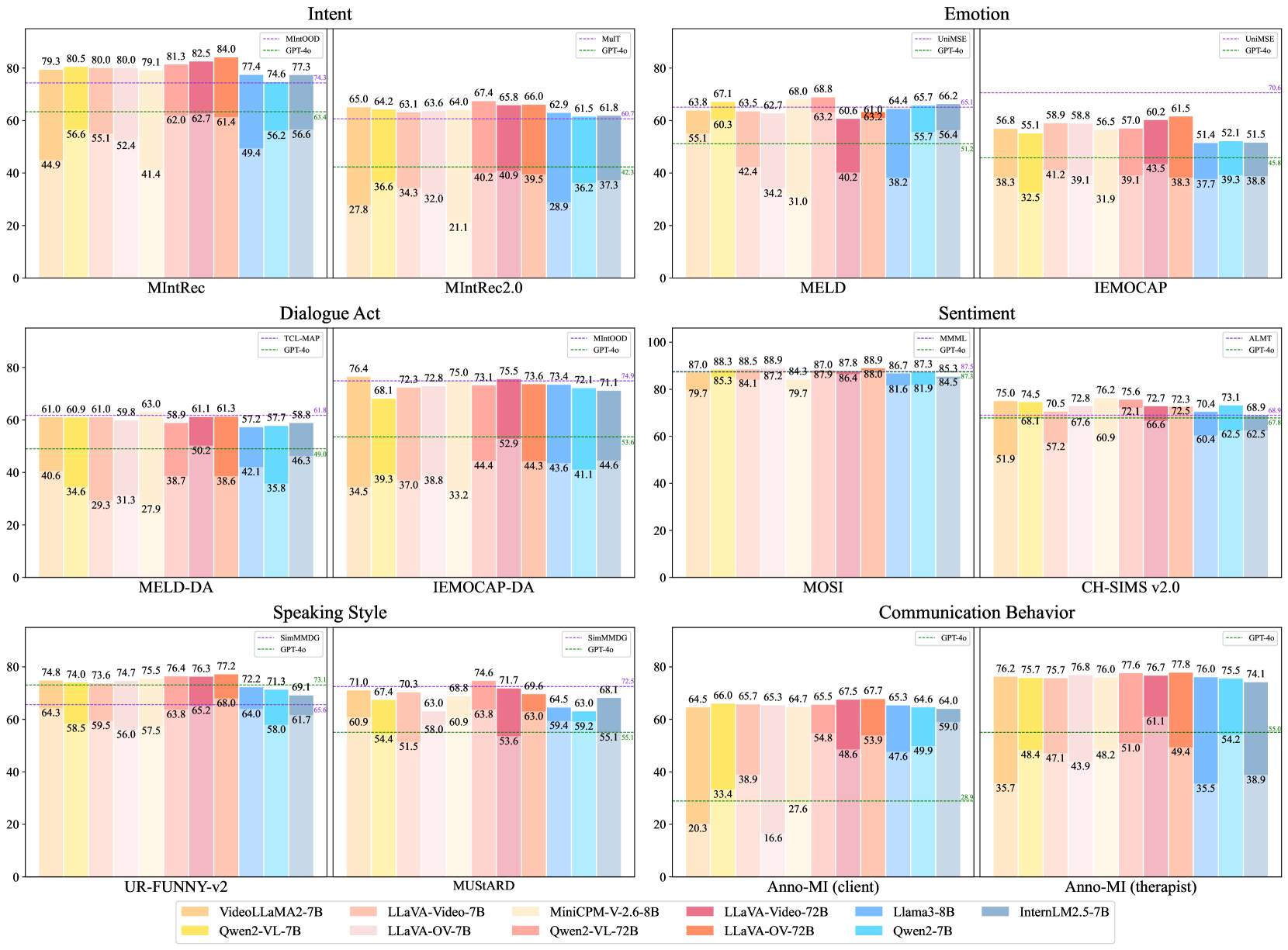
Fine-grained zero-shot and SFT performance across different dimensions and datasets.
Zero-shot performance is substantially limited across most dimensions, with accuracy scores below 60% on many challenging semantic dimensions (Intent, Emotion, Dialogue Act, and Communication Behavior). These dimensions typically involve numerous categories with nuanced differences. In contrast, performance on Sentiment and Speaking Style is generally higher because these tasks involve fewer categories.
After SFT, foundation models show remarkable improvements: 20-40% on Intent, 10-40% on Dialogue Act, 4-20% on Speaking Style, and 5-50% on Communication Behavior. MiniCPM-V-2.6 achieves improvements of over 30% across most dimensions.
While both MLLMs and LLMs benefit from SFT, MLLMs consistently outperform LLMs despite showing similar zero-shot performance. This suggests that SFT not only aligns modalities better to activate multimodal reasoning but also that incorporating non-verbal information reduces hallucinations more effectively than using text alone.
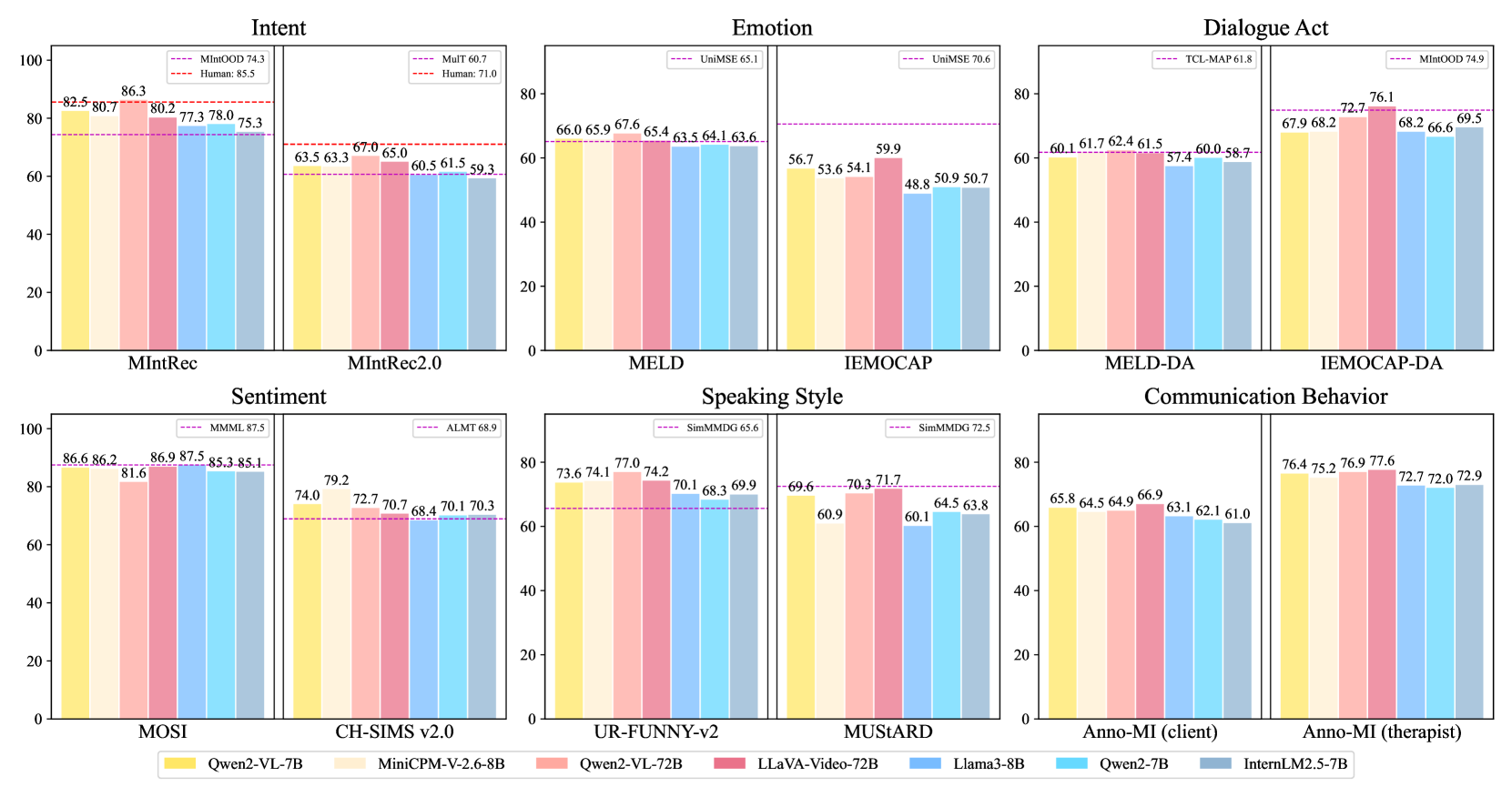
Fine-grained performance of instruction-tuned models across all datasets and dimensions.
After instruction tuning, MLLMs match or exceed previous SOTA methods on most datasets. Remarkably, 72B Qwen2-VL is the first to exceed human performance on MIntRec (86.3% vs. 85.5%), marking significant progress toward human-level semantic comprehension. On MIntRec2.0, 72B LLaVA-Video improves over the SOTA method by 6.3% and approaches human performance.
The small-scale MiniCPM-V-2.6 (8B) outperforms SOTA on seven datasets across five dimensions and achieves the best score on Ch-sims-v2. Moreover, small-scale MLLMs consistently outperform LLMs on nearly every dataset and task, demonstrating the potential of training unified MLLMs to tackle multiple complex multimodal language tasks.
Does Size Matter? Examining Model Scalability on MMLA
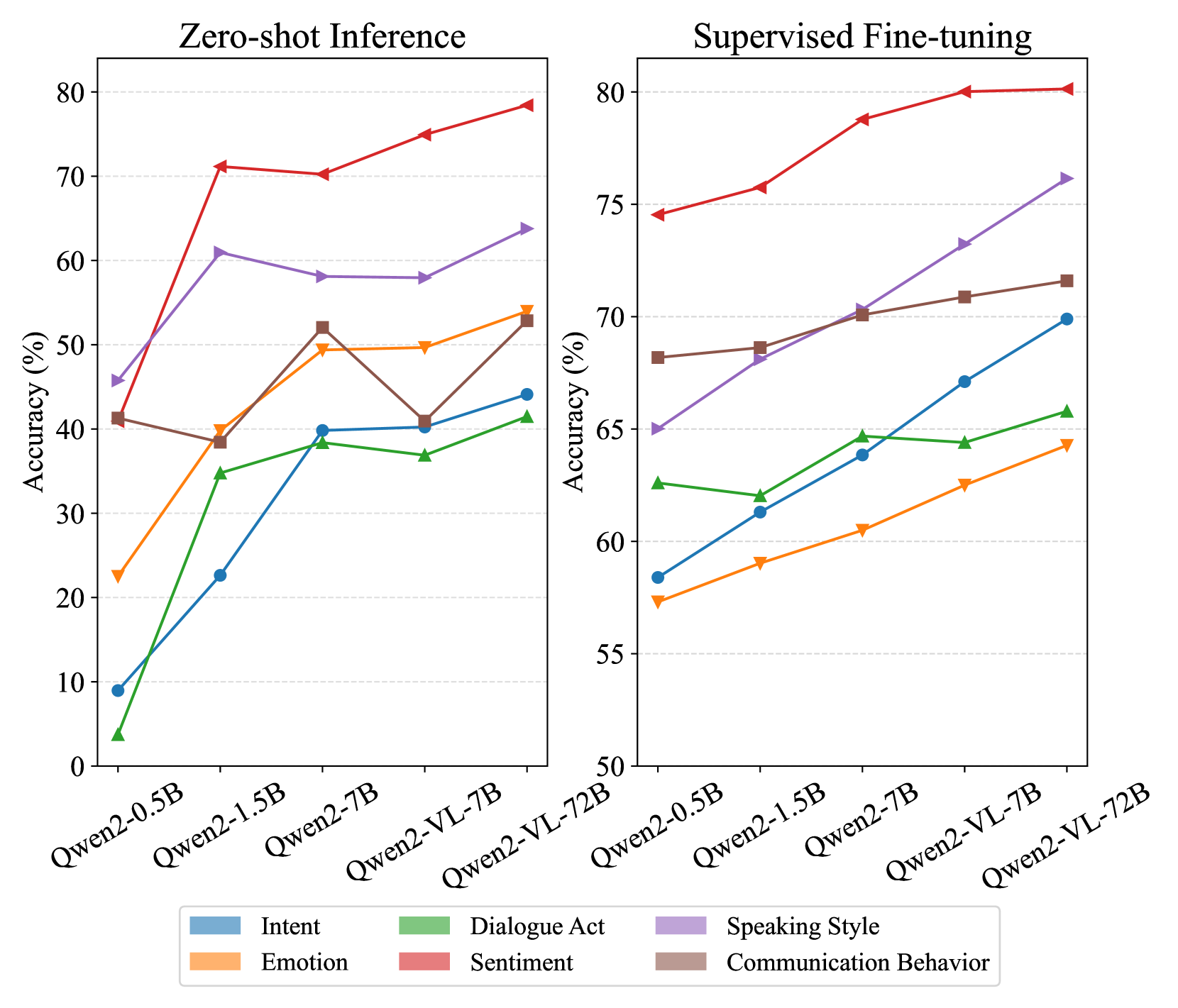
Scalability analysis of Qwen2 and Qwen2-VL models across different parameter sizes.
To examine the effect of model size, the researchers analyzed the scalability of Qwen2 (text-only) and Qwen2-VL (multimodal) models. In zero-shot inference, scaling from smaller to larger models generally shows improvements, validating the scalability principle of foundation models.
However, after supervised fine-tuning, the benefits of increasing model size become less pronounced. Scaling Qwen2 from 0.5B to 7B yields modest improvements of 3-5% on Intent, Sentiment, Speaking Style, and Emotion dimensions. Similarly, scaling Qwen2-VL from 7B to 72B achieves substantial improvements only on Speaking Style and Intent dimensions (over 5%), with under 2% gains in Sentiment, Communication Behavior, and Dialogue Act.
These results suggest that simply enlarging model parameters provides little benefit for analyzing complex multimodal language semantics when using supervised instructions as prior knowledge. This underscores the need for appropriate architectures and high-quality data rather than just bigger models.
Looking Forward: The Future of Multimodal Language Understanding
The MMLA benchmark provides the first comprehensive evaluation of foundation models on multimodal language analysis. The findings reveal several important insights:
Existing MLLMs show no advantage over LLMs in zero-shot settings but excel after supervised fine-tuning, demonstrating the importance of domain-specific training for multimodal understanding.
Smaller MLLMs (7B-8B parameters) can achieve performance comparable to much larger models (72B) after fine-tuning, making lightweight models a feasible and cost-effective option.
Instruction tuning enables training a single unified model to excel across multiple tasks with performance comparable to specialized models.
Despite these advances, even the best models achieve below 70% average accuracy, highlighting the significant challenge posed by complex multimodal language understanding.
These findings from the MMLA benchmark establish a rigorous foundation for advancing multimodal language understanding. The comprehensive evaluation approach pushes the boundaries of existing MLLMs and sets new directions for research in cognitive-level human-AI interaction.
As foundation models continue to evolve, the MMLA benchmark will serve as a crucial testbed for measuring progress in machines' ability to understand the nuanced, multimodal nature of human communication.
