This is a Plain English Papers summary of a research paper called MLRC-Bench: Can LLMs Conquer Machine Learning Research Competitions? Objective Metrics Revealed!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Can Language Agents Solve Machine Learning Research Challenges?
Evaluating how well large language model (LLM) agents perform research tasks has been limited by a lack of objective metrics. Current benchmarks often rely on subjective judgments of innovation or focus solely on basic implementation tasks that don't capture true research abilities.
A new benchmark called MLRC-Bench addresses this gap by measuring how effectively language agents tackle actual Machine Learning Research Competitions. Unlike previous work, which either uses LLMs to judge research quality or tests simple engineering tasks, MLRC-Bench provides objective metrics based on research competitions from top ML conferences.
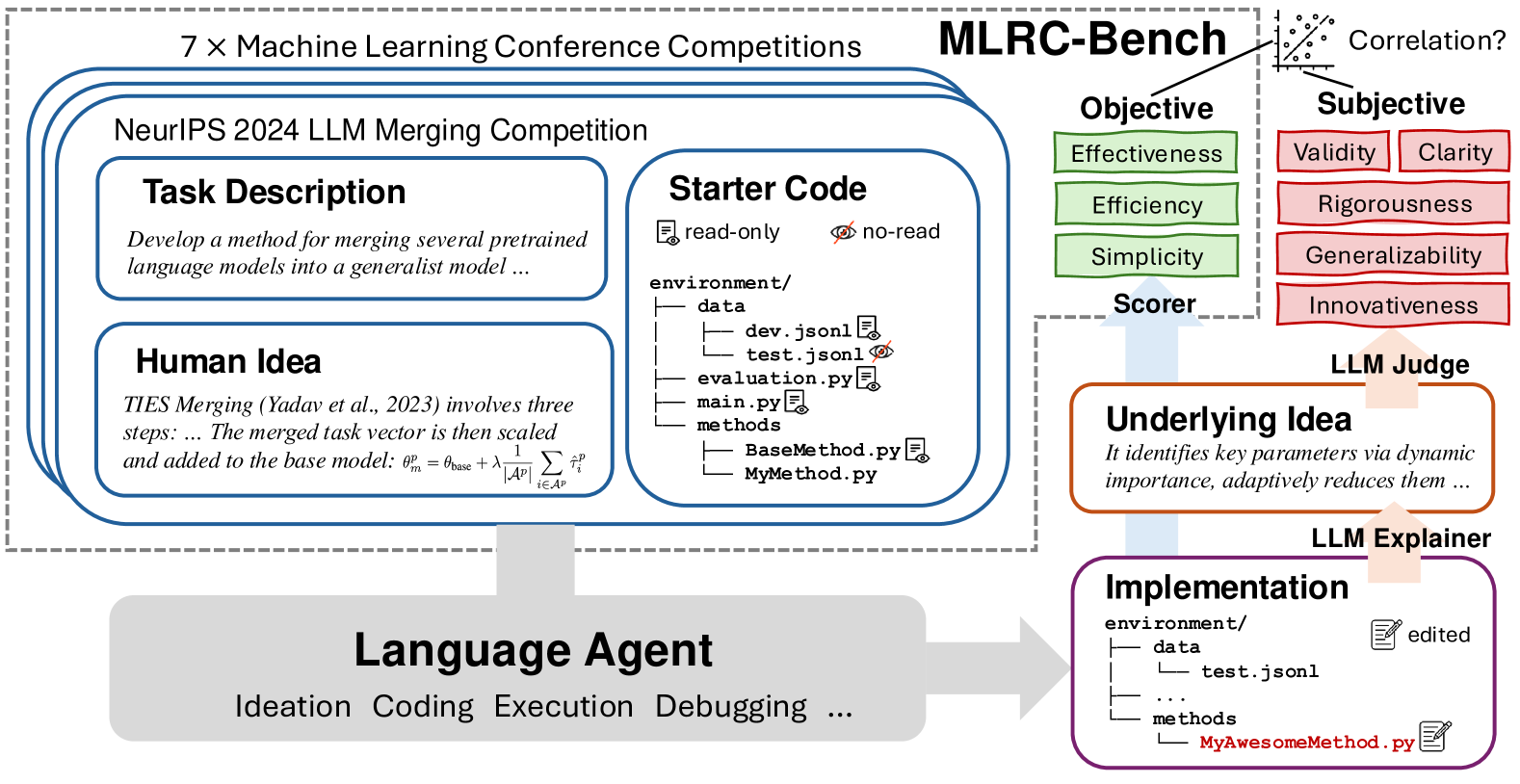
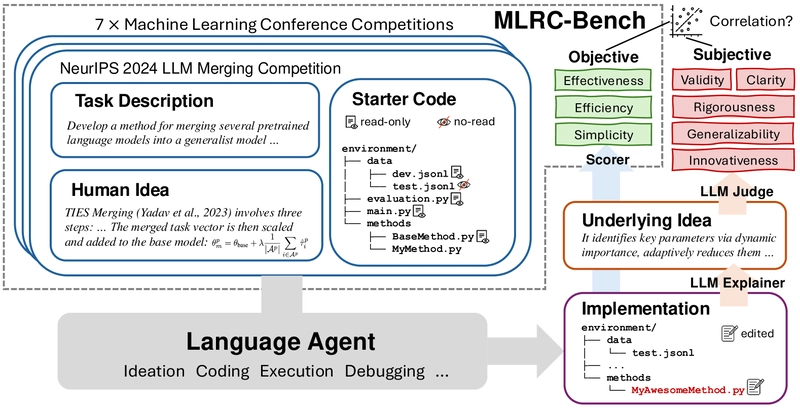
Overview of the MLRC-Bench evaluation pipeline, showing the standardized environment, agent scaffolding, and objective evaluation process.
How MLRC-Bench Differs from Previous Benchmarks
MLRC-Bench distinguishes itself from previous benchmarks by focusing specifically on method proposal and implementation for unsolved research problems. The framework evaluates both novelty and effectiveness against established baselines and top human solutions.
| Problem Identification | Method Proposal | Experiment Design | Code Implementation | Evaluation Method | Evaluation Object | Compute Constraints | |
|---|---|---|---|---|---|---|---|
| AI Scientist (Lu et al., 2024b) | ✓ | ✓ | ✓ | ✓ | LLM & Human Judge | Paper | |
| Can LLMs Generate Novel Research Ideas? (Si et al., 2024) | ✓ | ✓ | ✓ | Human Judge | Idea Proposal | ||
| DiscoPOP (Lu et al., 2024a) | ✓ | ✓ | Performance-Based | Function-Level Code | |||
| MLE-Bench (Chan et al., 2024) | ∼ | ✓ | Performance-Based | File-Level Code | |||
| MLAgentBench (Huang et al., 2024a) | ∼ | ✓ | Performance-Based | File-Level Code | |||
| MLRC-BENCH (Ours) | ✓ | ✓ | Performance-Based | Repository-Level Code | ✓ |
Table 1: Comparison between MLRC-Bench and existing work on automated scientific discovery in machine learning with LLM agents. "∼" means that some but not all of the tasks in that benchmark require the indicated capability. "Compute Constraints" indicates whether the solution code must adhere to specified runtime and GPU memory limitations, an important aspect ignored by most prior work.
Unlike benchmarks like MLE-Bench that focus on engineering tasks, MLRC-Bench requires genuine methodological innovation. It also differs from frameworks like MLR-Copilot by providing objective performance metrics rather than relying on subjective paper evaluations.
The MLRC-Bench Framework
Task Selection
MLRC-Bench includes seven tasks from recent ML conferences and workshops, selected based on three criteria:
- Novel Research-Focused: Tasks require genuine methodological innovation, not just hyperparameter tuning
- Non-Trivial: Problems must involve complexity beyond standard ML algorithms
- Feasible: Starter code, data splits, and evaluation procedures must be publicly available
| Competition | Venue | Research Area | Modality | Metric | Test Runtime | GPU Memory |
|---|---|---|---|---|---|---|
| LLM Merging (Tam et al., 2024) | NeurIPS 2024 | Efficient LLM | Text | Accuracy, ROUGE | 1 hour | 48 GB |
| Backdoor Trigger Recovery (Xiang et al., 2024) | NeurIPS 2024 | LLM Safety | Text | REASR, Recall | 0.5 hour | 48 GB |
| Temporal Action Localisation (Heyward et al., 2024) | ECCV 2024 Workshop | Multimodal Perception | Video, Audio | mAP | 0.5 hour | 16 GB |
| Rainfall Prediction (Gruca et al., 2022) | NeurIPS 2023 | AI for Science | Satellite Data | Critical Success Index | 0.5 hour | 48 GB |
| Machine Unlearning (Triantafillou et al., 2024) | NeurIPS 2023 | Data Privacy | Image | Forgetting Quality, Accuracy | 0.5 hour | 16 GB |
| Next Product Recommendation (Jin et al., 2023) | KDD Cup 2023 | Recommendation System | Text | Mean Reciprocal Rank | 0.5 hour | 16 GB |
| Cross-Domain Meta Learning (Carrión-Ojeda et al., 2022) | NeurIPS 2022 | Few-Shot Learning | Image | Accuracy | 3.5 hours | 16 GB |
Table 2: 7 MLRC-Bench tasks representing cutting-edge machine learning research. For each competition, we show the venue where the competition is held, research area, data modality, performance metric, along with the constraints presented to the agents, including maximum allowed runtime and GPU memory based on our hardware configurations.
The benchmark is designed to be continuously updated with new competitions, reducing the risk of data contamination as newer LLMs are released.
Task Environment
For each task, MLRC-Bench provides:
- Task Description: Details about the research problem and constraints
- Starter Code: A baseline model, evaluation scripts, and data splits
- Human Idea: Insights from state-of-the-art papers or top participant solutions
The environment features a standardized code structure where agents can modify only the methods directory while evaluation scripts remain read-only. This ensures fair comparison while preserving evaluation integrity.
Evaluation Metrics
MLRC-Bench evaluates solutions on three objective dimensions:
- Effectiveness: Performance on the competition's primary metric
- Efficiency: Runtime during training and inference
- Simplicity: Logical lines of code (complexity)
To compare across different tasks, the benchmark uses a "Relative Improvement to Human" metric that normalizes scores, setting the baseline solution to 0 and the top human solution to 100.
Experimental Results
Agent Performance
Researchers tested five leading LLMs (Claude 3.5 Sonnet v2, gemini-exp-1206, Llama 3.1 405B Instruct, o3-mini, and GPT-4o) using the MLAB scaffolding, which allows agents to iteratively modify code and run experiments.
| Agent | temporal -action-loc | llm -merging | meta -learning | product -rec | rainfall -pred | machine -unlearning | backdoor -trigger | Avg |
|---|---|---|---|---|---|---|---|---|
| MLAB (gemini-exp-1206) | -0.5 | 5.0 | -1.1 | 0.1 | 43.1 | 5.6 | 12.9 | 9.3 |
| MLAB (llama3-1-405b-instruct) | 0.5 | -1.0 | -4.9 | 0.0 | 31.5 | 6.2 | 11.5 | 6.3 |
| MLAB (o3-mini) | 0.3 | -1.0 | -4.9 | 0.1 | 25.1 | 3.6 | 6.2 | 4.2 |
| MLAB (claude-3-5-sonnet-v2) | 0.8 | 5.0 | -4.9 | 3.0 | 14.6 | -94.7 | 39.9 | -5.2 |
| MLAB (gpt-4o) | 0.3 | 2.0 | -4.9 | 0.6 | 47.5 | -18.0 | 10.4 | 5.4 |
| Human Idea + MLAB (gpt-4o) | 0.5 | -1.0 | -4.9 | 2.2 | 12.3 | 6.8 | 8.8 | 3.5 |
| CoI-Agent Idea (o1) + MLAB (gpt-4o) | 0.4 | -1.0 | -4.9 | 0.1 | 39.4 | 11.8 | 4.0 | 7.1 |
Table 3: For each research competition and agent, we report the test-phase relative improvement to human, defined as the agent's solution margin over the baseline normalized by the top human solution's margin over the baseline, taking the best of 8 trials. Top human participants in each competition will score 100.0 due to the normalization. Additionally, we evaluate two other gpt-4o-based pipelines: MLAB augmented with ideas from either CoI-Agent (Li et al., 2024a) or humans. Best performing agent in each task is highlighted in bold. Our results indicate that providing additional ideas, whether sourced from AI or humans, does not consistently yield performance improvements. The best-performing configuration—gemini-exp-1206 under MLAB—achieves only 9.3% of the human-level improvement over baseline on average, underscoring the inherent difficulty of these research tasks.
The results revealed that even the best-performing agent (gemini-exp-1206) closed only 9.3% of the gap between baseline and top human performance. Surprisingly, providing additional ideas from either AI or humans didn't consistently improve performance, highlighting the challenge of effectively implementing even good ideas.
Scaling with Inference-Time Compute
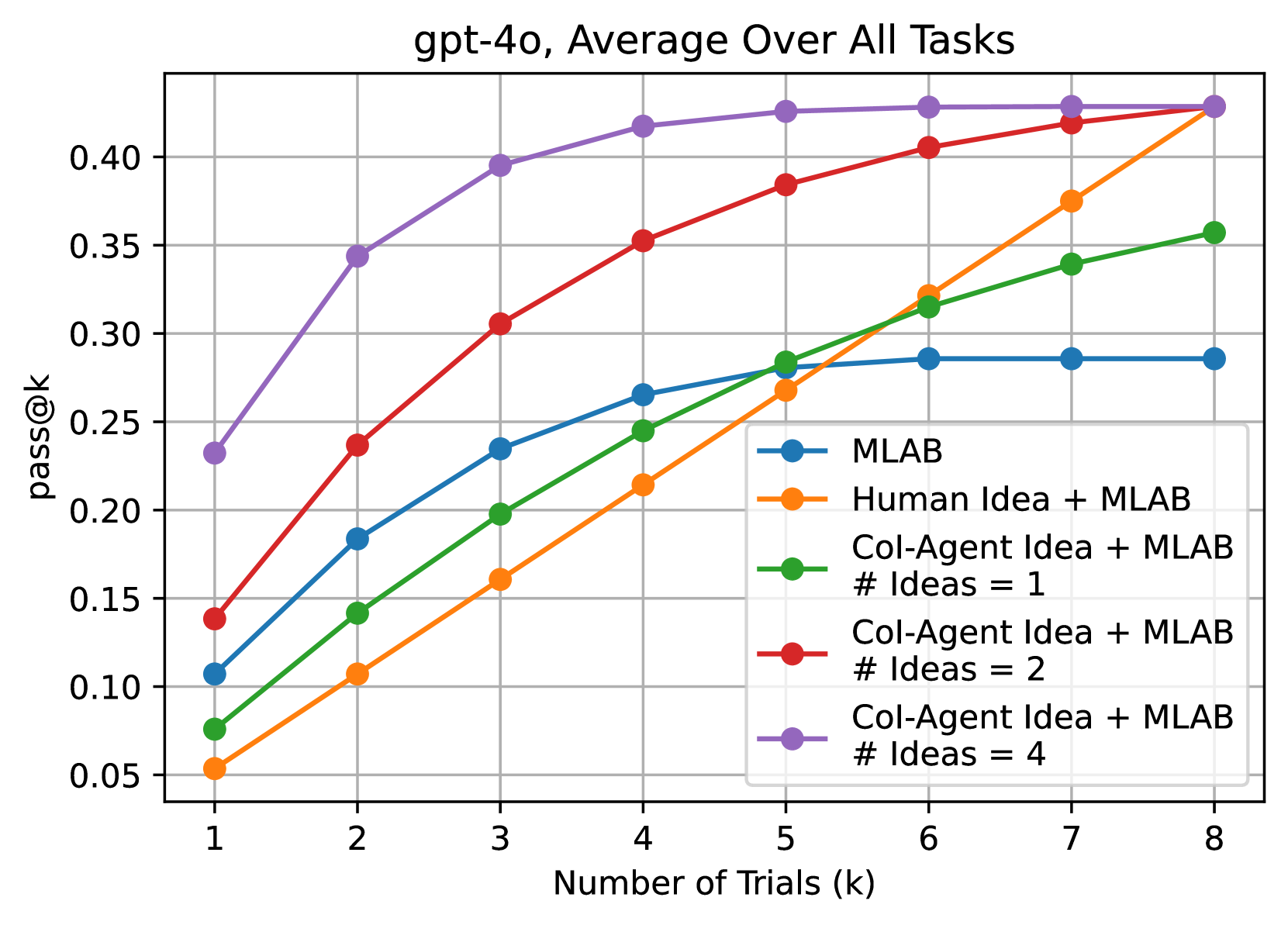
We measure Pass@k as we scale the number of trials and ideas, running MLAB for eight trials per idea. Results indicate that 1) providing high-quality ideas—especially human-generated ones—significantly boosts an agent's success rate across multiple attempts, 2) while varying the balance between idea exploration and exploitation under a fixed budget yields similar outcomes due to diminishing returns from repeated trials.
The study analyzed how agents scale with more inference-time compute by sampling multiple ideas and running multiple implementation trials per idea. The findings show that high-quality ideas (especially human ones) boost success rates, but under a fixed compute budget, there was no significant difference between exploring more ideas versus running more trials per idea.
Subjective vs. Objective Evaluation
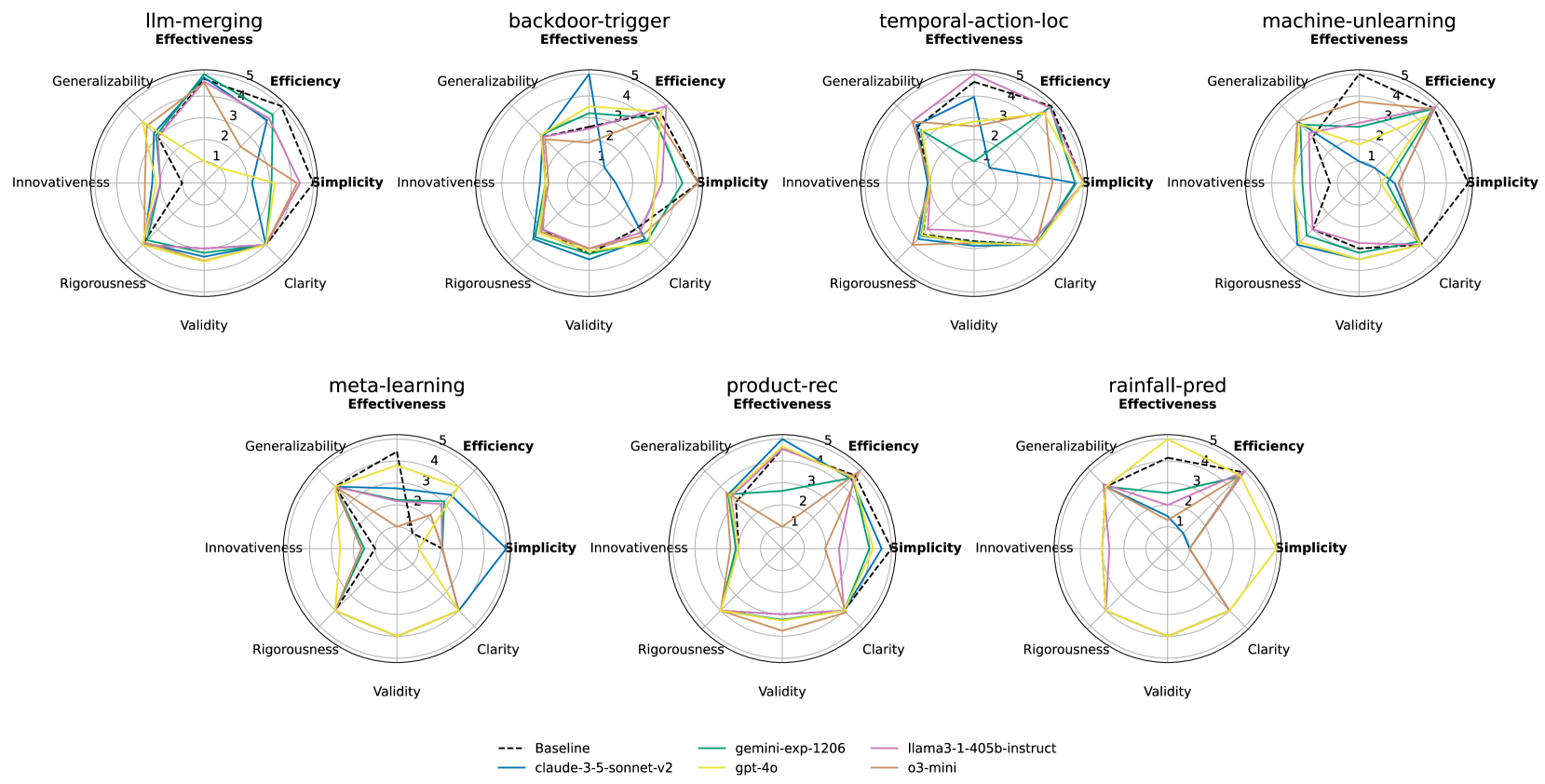
Radar plots of objective and subjective evaluations for agent-generated solutions across seven research tasks. Each dimension is normalized on a 1–5 scale, where higher values indicate better performance. Objective metrics include effectiveness, efficiency, and simplicity, which are highlighted in bold. The rest are subjective metrics, assessed by prompting an LLM as a judge. Notably, more effective solutions identified by agents tend to be more complex and time-consuming (e.g., in backdoor trigger recovery task). Additionally, overlapping scores in subjective dimensions suggest that LLM-based evaluation struggles to distinguish the research capabilities of different models.
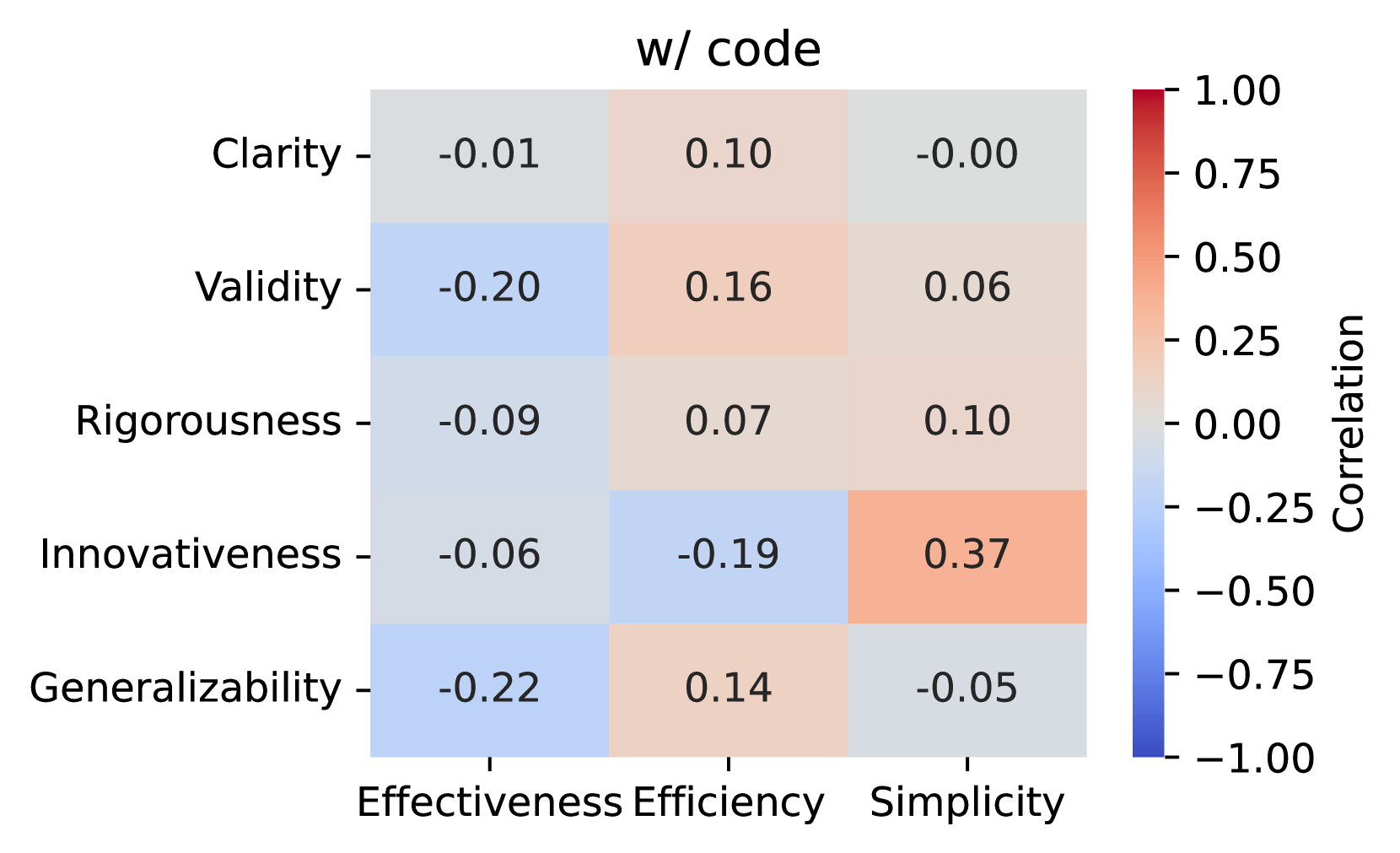
Correlation heatmap between objective (x-axis) and subjective (y-axis) metrics for agent-generated solutions across all tasks. In this setting, code is included when prompting the LLM to evaluate subjective dimensions. No strong correlation is observed, suggesting that LLM-judged subjective metrics may not reliably indicate real-world impact.
The researchers investigated whether LLM-based evaluations can reliably assess research quality by comparing subjective judgments (validity, clarity, rigor, generalizability, and innovativeness) with objective metrics. They found almost no correlation between LLM-judged innovativeness and actual effectiveness, suggesting that LLM evaluations alone aren't reliable proxies for real-world research impact.
Implementation Process Analysis
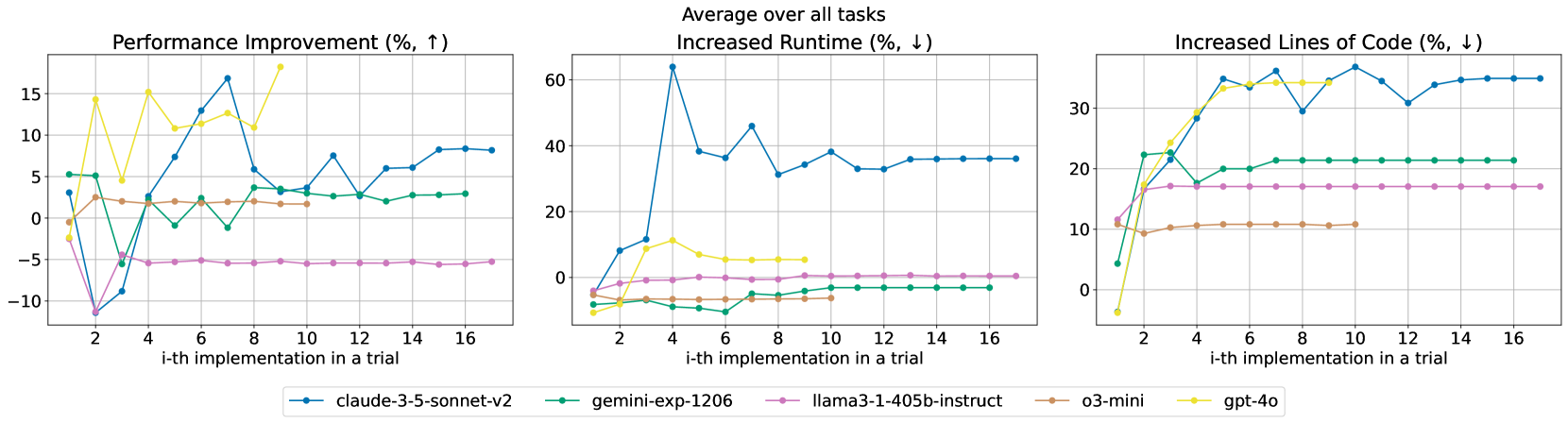
We track the percentages of changes of performance, runtime, and lines of code compared to baseline across iterative refinement of implementations within a trial of LLM-based MLAB agent on the development set. Performance improvement is the higher the better, while increased runtime and lines of code are the lower the better.
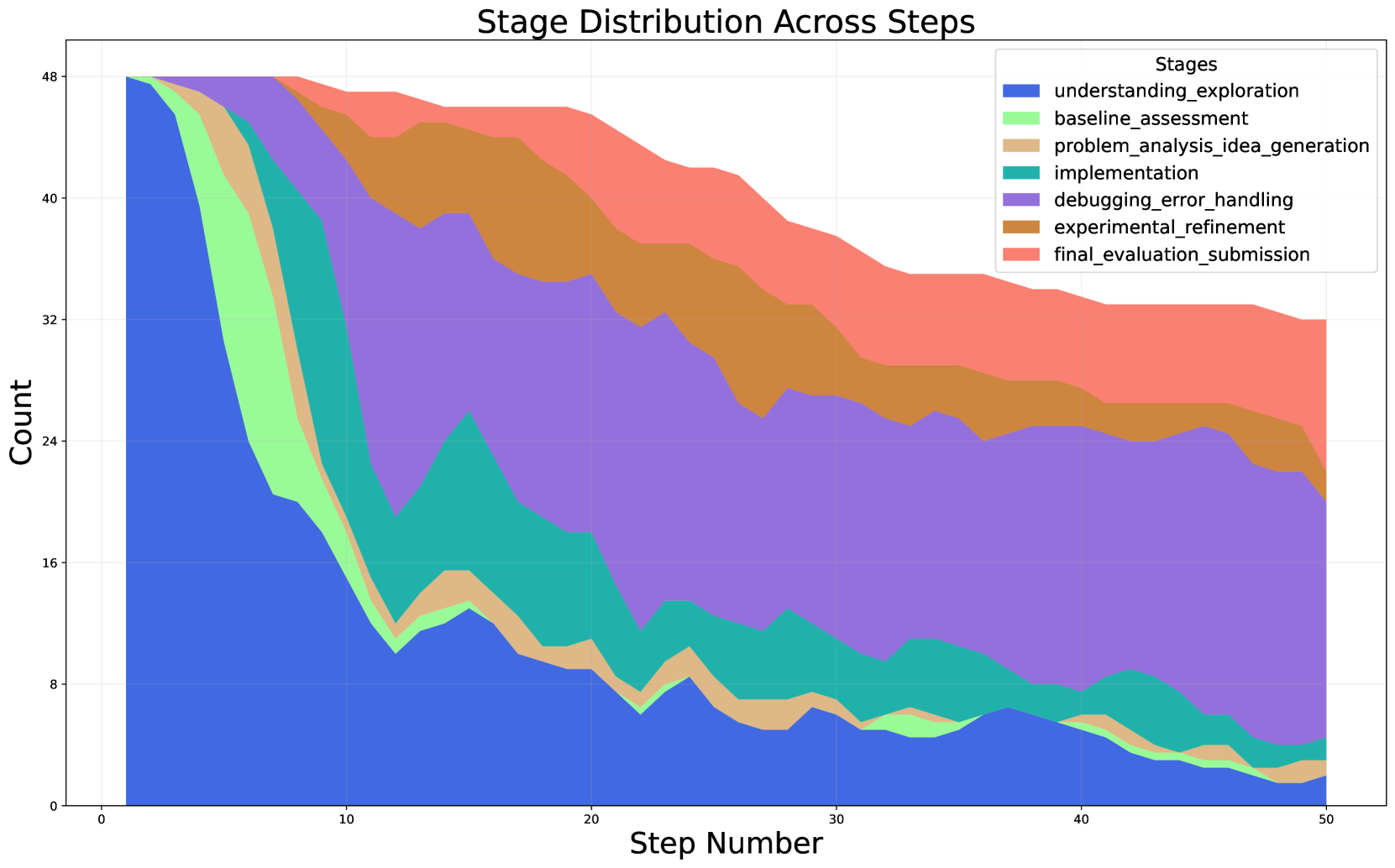
Stage distribution across each step, annotated using GPT-4o and grouped into seven distinct stages to illustrate shifts in task focus and activity over the course of all tasks.
Analysis of the implementation process revealed that agents spend most of their time understanding the problem environment and writing code, with limited effort on brainstorming new ideas. As they refine implementations, runtime and code complexity increase steadily, often without proportional performance gains, suggesting that agents tend to over-refine their solutions.
Cost-Effectiveness Analysis
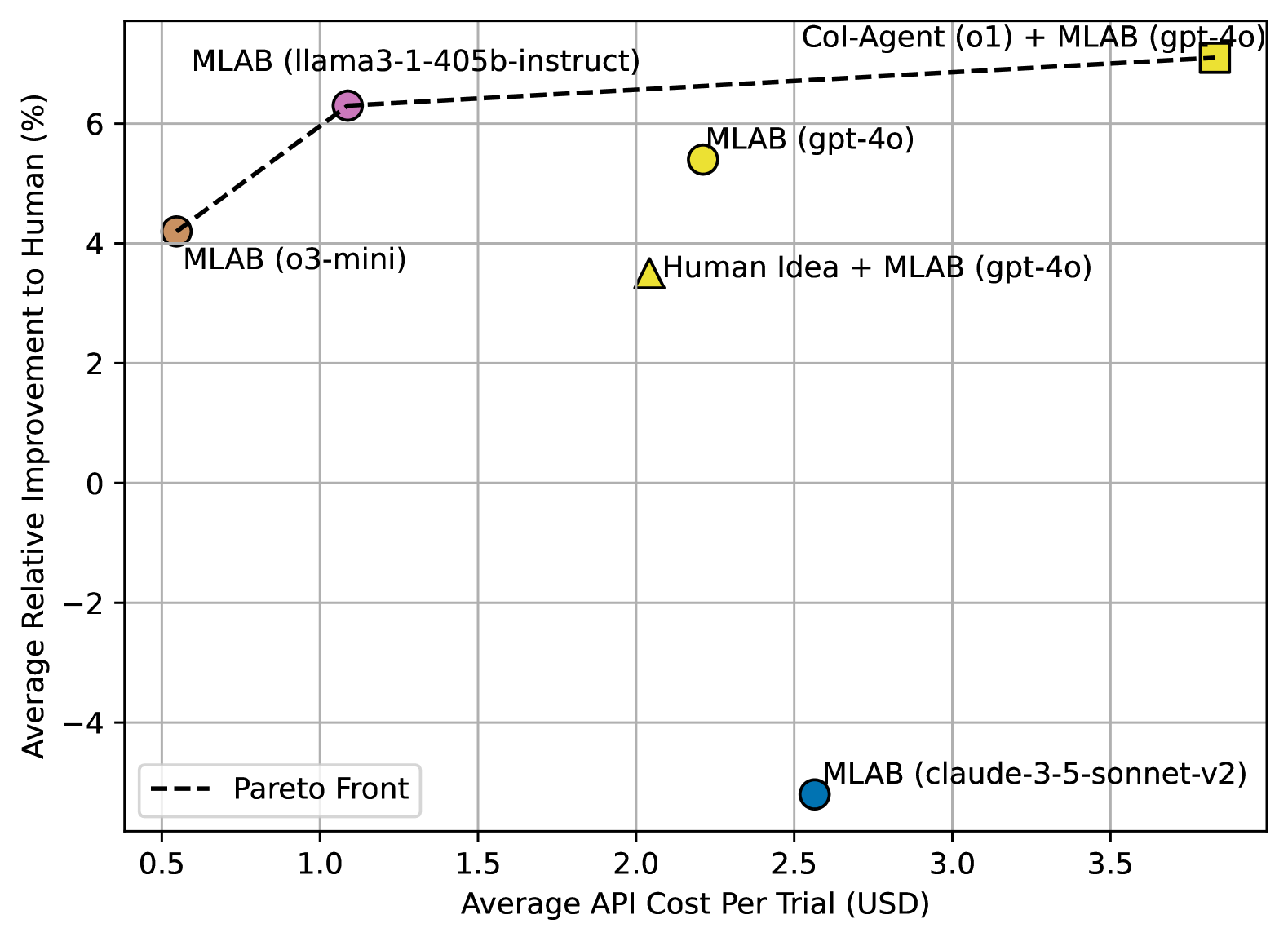
We perform a cost-effectiveness analysis of various setups. On the x-axis, we plot API cost, where lower is better, and on the y-axis, we show relative improvement to human, where higher is better. Among the settings evaluated, Llama 3.1 405B with the MLAB scaffolding emerges as a Pareto-optimal setting that balances cost and performance improvement.
When considering both performance and API costs, Llama 3.1 405B Instruct with the MLAB scaffolding offered the most favorable trade-off, achieving higher success rates than GPT-4o and Claude 3.5 Sonnet at a significantly lower cost.
Conclusion
MLRC-Bench provides a rigorous, objective framework for evaluating AI research agents that avoids the pitfalls of purely subjective assessment. The results show that current state-of-the-art LLM agents still fall significantly short of human research capabilities, with the best agent achieving only 9.3% of human-level improvement over baseline.
The benchmark reveals a concerning misalignment between LLM-judged innovation and actual performance on cutting-edge research problems. This highlights the importance of objective metrics when evaluating research agents' capabilities.
As a dynamic benchmark that can incorporate new competitions, MLRC-Bench provides a solid foundation for tracking progress in AI-assisted scientific discovery while maintaining rigorous evaluation standards. The significant gap between current agents and human researchers suggests ample room for improvement in how AI systems approach genuine research innovation.
