
This is a Plain English Papers summary of a research paper called MultiMed-ST: New Dataset Breaks Barriers in Medical Speech Translation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Breaking Language Barriers in Healthcare: The Need for Medical Speech Translation
Effective communication between healthcare providers and patients serves as the foundation of quality medical care. However, linguistic barriers frequently hinder this communication, especially in multicultural and multilingual settings. These barriers can lead to misdiagnoses, improper treatment, and diminished patient satisfaction, ultimately compromising the overall quality of care.
Medical speech translation (ST) aims to bridge these linguistic divides by enabling real-time communication between speakers of different languages. The demand for medical ST has grown significantly with increasing globalization of healthcare. Whether addressing the needs of immigrant populations, international patients seeking specialized treatments, or global health crises requiring cross-border collaboration, these technologies have the potential to transform how medical professionals deliver care.
Despite the emergence of large-scale pre-trained models adaptable to domain-specific tasks, medical ST research has been hindered by the scarcity of publicly available datasets and models, largely due to privacy concerns. Existing publicly available medical machine translation (MT) datasets are text-only, relatively small, and crawled from the internet, lacking the necessary quality and diversity for developing robust medical ST systems. The VietMed Dataset represents one of the few high-quality resources for medical speech recognition, but lacks the translation component essential for multilingual communication.
The MultiMed-ST dataset addresses this gap by providing the first large-scale, high-quality, and diverse dataset for many-to-many multilingual medical ST, supporting five languages: Vietnamese, English, German, French, and Mandarin Chinese (both traditional and simplified).
The MultiMed-ST Dataset: Building a Foundation for Medical Speech Translation
From Speech to Translation: Data Collection and Processing
The speech data for MultiMed-ST was sourced from the medical ASR dataset provided by Le-Duc et al. (2024), used under scientific research license. This dataset comprises manually transcribed recordings of real-world multi-speaker medical conversations across five languages, representing the largest and most diverse medical ASR resource based on total duration (150 hours), recording conditions (10), accents (16), speaking roles (6), unique medical terms, and inclusion of all ICD-10 codes.

MFCC visualization. The computation of MFCCs begins by dividing the original waveform into overlapping 20ms frames.
Rigorous Annotation: Ensuring Translation Quality
The data underwent a meticulous annotation process. Initially, the source language content was translated into target languages using the Gemini Large Language Model (LLM). Following this automated phase, five human annotators manually corrected and cross-verified all translations based on the context of the whole conversation. Only transcripts that received consensus approval from multiple annotators were retained, resulting in 100% inter-annotator agreement.
Notably, approximately 90% of LLM-generated translations required human correction, highlighting the critical importance of expert human oversight in medical translation. All human annotators possessed professional language proficiency (C1 or higher, or HSK5 for Chinese), had completed basic medical training, and demonstrated substantial knowledge of medical terminology in their respective languages. Additionally, they were either pursuing or had completed undergraduate or graduate studies in countries where their chosen language is predominantly spoken.
A Record-Breaking Medical Translation Resource
The MultiMed-ST dataset contains a total of 290,000 samples covering all translation directions between the five supported languages. This makes it the largest medical MT dataset compared to existing medical MT datasets, despite the fact that speech data is much more difficult to collect and annotate than text.
| Language | vi→X | en→X | de→X | fr→X | zh→X |
|---|---|---|---|---|---|
| #Samples | |||||
| Train | 4k5 | 25k5 | 1k4 | 1k4 | 1k2 |
| Dev | 1k1 | 2k8 | 300 | 40 | 90 |
| Test | 3k4 | 4k8 | 1k1 | 300 | 200 |
| All | 9k1 | 33k1 | 2k8 | 1k8 | 1k6 |
| Med. length | |||||
| →vi | 70 | 140 | 180 | 160 | 250 |
| →en | 90 | 150 | 160 | 150 | 250 |
| →de | 110 | 170 | 180 | 180 | 300 |
| →fr | 100 | 160 | 200 | 140 | 290 |
| →zh | 30 | 50 | 50 | 40 | 80 |
Table 1: Statistics of MultiMed-ST dataset. In total, the dataset has 290k samples (utterances) for all directions of 5 languages: Vietnamese (vi), English (en), German (de), French (fr), and both traditional and simplified Chinese (zh). Median text length is calculated based on the number of characters.
When compared with existing medical MT datasets, MultiMed-ST stands out not only for its size but also for its comprehensive coverage of multiple languages and translation directions:
| Dataset | #Samples | Lang. | Direction |
|---|---|---|---|
| Neves (2017) | 46k | 2 | one-to-one |
| ParaMed Liu and Huang (2021) | 200k | 2 | one-to-one |
| Khresmoi Pecina et al. (2017) | 12k | 8 | many-to-many |
| WMT Biomed. Bawden et al. (2020) | 160k | 9 | one-to-one |
| YuQ Yu et al. (2020) | 130k | 2 | one-to-one |
| Bérard et al. (2020) | 1k5 | 2 | one-to-one |
| MedEV Vo et al. (2024) | 36k | 2 | one-to-one |
| MultiMed-ST (ours) | 290k | 5 | many-to-many |
Table 2: Dataset comparison with literature. All publicly available datasets listed here are text-only medical MT. MultiMed-ST is the first medical ST dataset, and is the largest medical MT dataset.
The Mathematical Framework: How Speech Translation Works
Speech translation can be approached through two main methods: cascaded and end-to-end translation. Each has distinct mathematical formulations and practical implications.
In a cascaded approach, speech is first converted to text in the source language through automatic speech recognition (ASR), then translated to the target language using a separate machine translation (MT) model. In contrast, end-to-end ST directly converts speech in one language to text in another without intermediate transcription.
Formally, given an audio signal x₁ᵀ of T audio frames, a source language sequence f₁ᴶ of J words, and a target language sequence e₁ᴵ of I words, the goal is to maximize the posterior probability of the target language sequence given the speech input.
For end-to-end ST, this is expressed as:
x₁ᵀ → ê₁ᴵ(x₁ᵀ) = arg max p(e₁ᴵ|x₁ᵀ)
For cascaded ST, this involves two steps:
x₁ᵀ → f̂₁ᴶ(x₁ᵀ) = arg max p(f₁ᴶ|x₁ᵀ)
f̂₁ᴶ → ê₁ᴵ(f̂₁ᴶ) = arg max p(e₁ᴵ|f̂₁ᴶ)
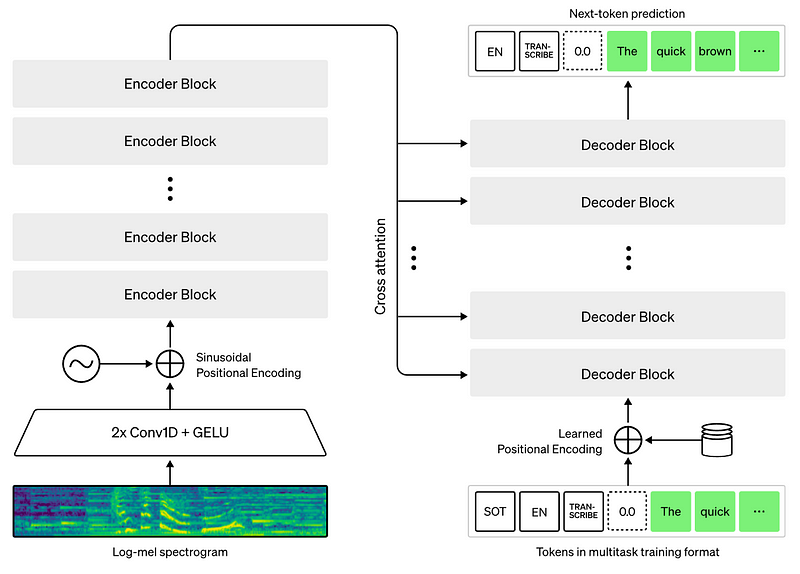
OpenAI's Whisper architecture. Whisper is a Transformer-based AED architecture, using MFCC features as input.
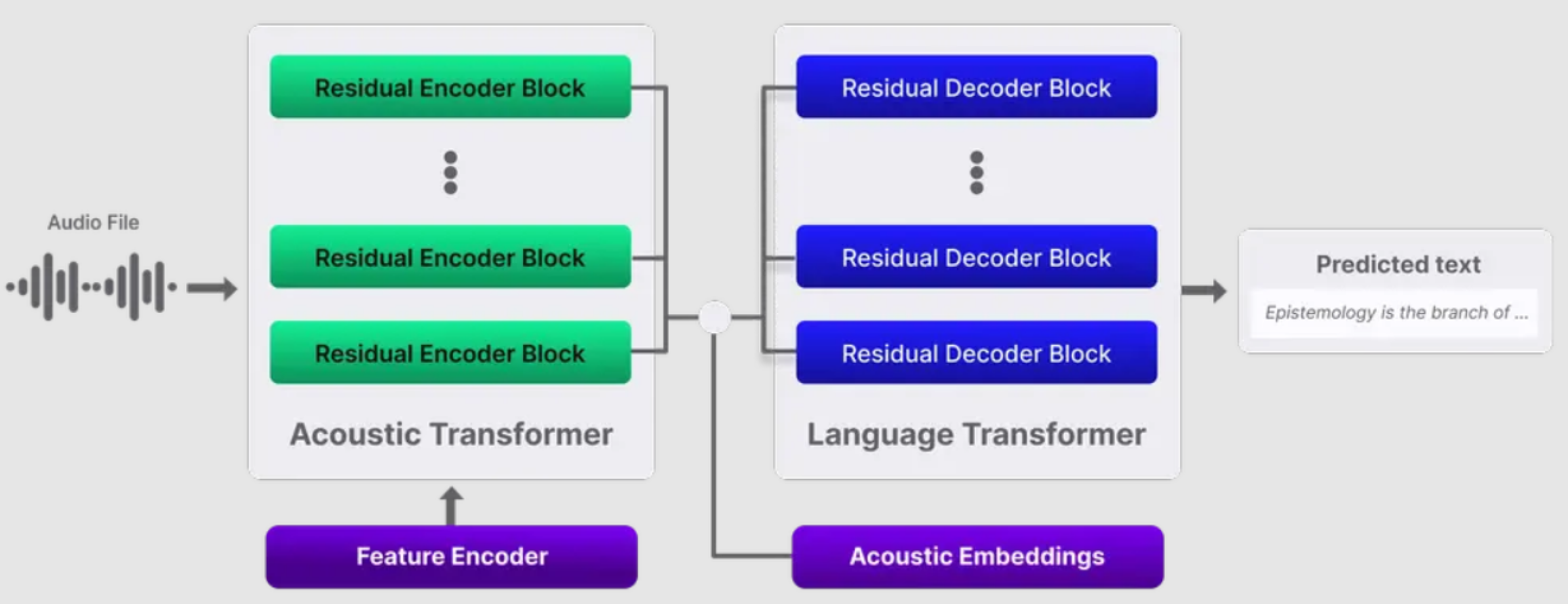
Deepgram's Nova-2 architecture. To our best understanding of Deepgram's documentation, Deepgram's Nova-2 is a Transformer-based AED architecture, using raw waveform as input instead of MFCC like Whisper. Feature extraction from raw waveform is probably conducted by a learnable feature encoder, e.g. a block of CNNs like wav2vec 2.0. Between encoder-decoder space, (unknown) acoustic embeddings are probably added as cross-attention.
Experimental Design: Models, Training, and Evaluation
Building a Translation Arsenal: Models and Training
The experimental setup employed a comprehensive range of models for both cascaded and end-to-end speech translation approaches.
For the ASR component in cascaded systems, two state-of-the-art architectures were used:
-
Attention Encoder Decoder (AED) models:
- Whisper models (small and large-v2)
- Deepgram
-
Recurrent Neural Network Transducer (RNN-T):
- AssemblyAI
For the MT component in cascaded systems, various architectures were tested:
-
Multilingual pre-trained models:
- Encoder-decoder: mBART-large-50, M2M100-418M, Marian
- Decoder-only: Llama-3.1-8B, Qwen-2.5-7B, Mistral-v0.3-7B
- Commercial tool: Google Translate
-
Bilingual pre-trained models:
- VinAI Translate
- EnViT5
For end-to-end speech translation, three models were evaluated:
- Whisper
- SeamlessM4T-large-v2
- Qwen2-Audio-7B-Instruct
Data augmentation techniques like SpecAugment were also tested during training to improve model robustness.
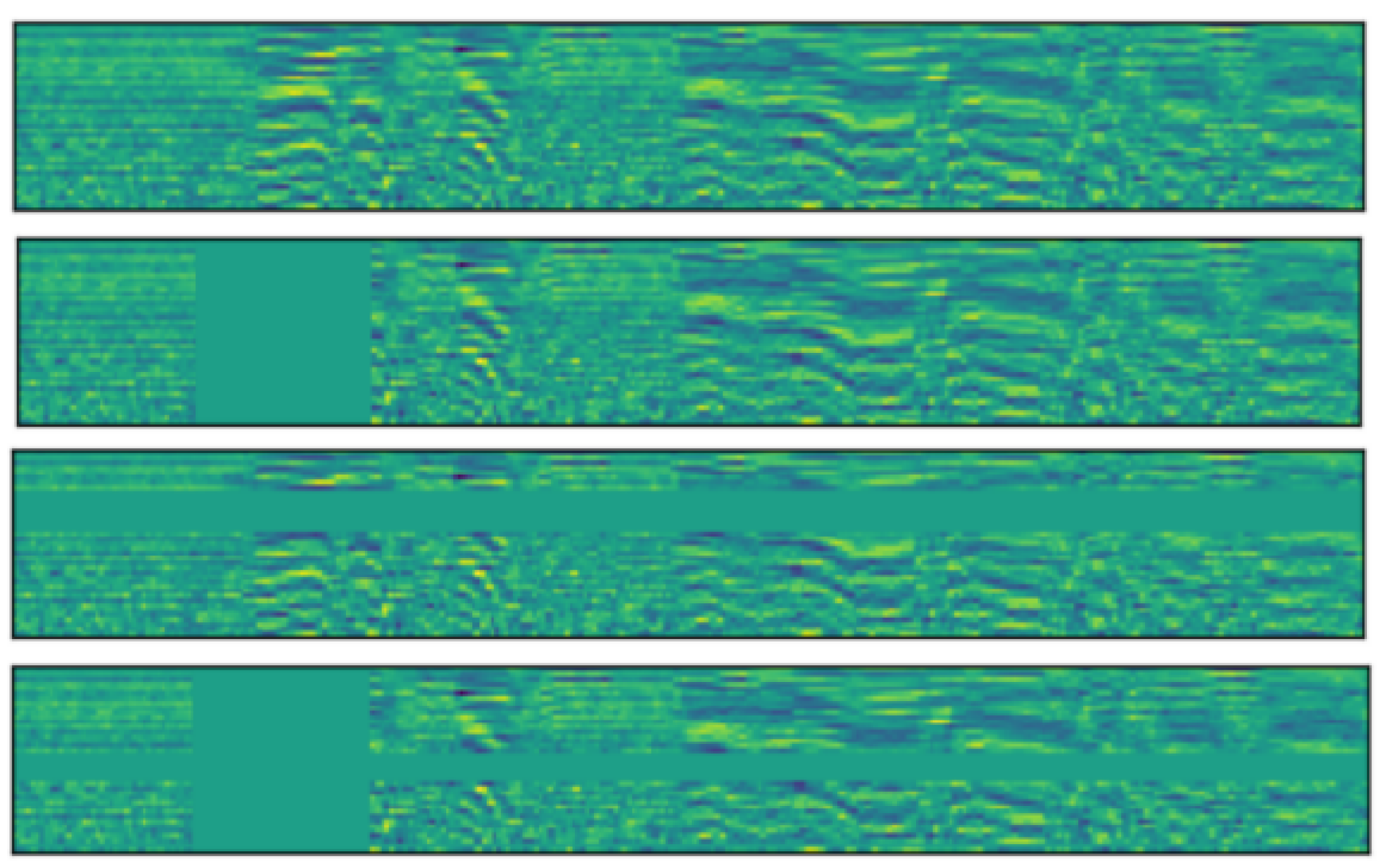
SpecAugment visualization. From top to bottom, the figures show the spectrogram of the input audio with no data augmentation, time masking, frequency masking and both masking applied.

Fine-tuning configuration of Whisper-small model
Measuring Success: Evaluation Methods
Multiple evaluation metrics were employed to assess both ASR and MT performance:
-
ASR metrics:
- Word Error Rate (WER) for alphabetic languages
- Character Error Rate (CER) for Chinese
-
Automatic MT metrics:
- N-gram overlap metrics: BLEU, TER, METEOR, ChrF, ROUGE
- Embedding-based metrics: BERTScore
-
Human evaluation:
- Adequacy: How well the meaning is conveyed
- Fluency: Grammatical and stylistic quality
- Comprehensibility: How easily understood without reference to source
-
LLM-as-a-judge:
- Assessing translations based on deeper semantic understanding
- Evaluating contextual appropriateness and syntactic correctness
This multifaceted evaluation approach allows for a comprehensive understanding of model performance beyond simple automated metrics, which is particularly important in the medical domain where translation accuracy can have significant consequences for patient care. The evaluation methods align with best practices described in the Medical MT5 research, which emphasizes the importance of domain-specific evaluation for medical translation tasks.
Results Deep Dive: What Works Best for Medical Speech Translation?
ASR Performance: The First Critical Step
The ASR performance varied significantly across models and languages, with interesting trade-offs between model size, fine-tuning strategies, and language characteristics.
| ASR | dev | test | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| vi | en | zh | de | fr | vi | en | zh | de | fr | |
| Whisper-small-mono | 21.2 | 24.4 | 25.9 | 17.5 | 35.8 | 29.6 | 33.8 | 31.3 | 26.3 | 45.7 |
| + SpecAugment | 19.8 | 23.5 | 43.3 | 17.9 | 44.1 | 31.7 | 36.9 | 46.9 | 24.1 | 45.6 |
| Whisper-small-multi | 25.7 | 46.1 | 73.9 | 22.2 | 50.6 | 33.4 | 40.9 | 89.8 | 19.6 | 55.3 |
| Whisper-large-v2-mono | 57.7 | 26.9 | 39.0 | 23.7 | 52.9 | 62.6 | 25.5 | 37.3 | 24.2 | 41.7 |
| Assembly | 51.9 | 31.7 | 49.8 | 27.9 | 49.4 | 65.5 | 30.6 | 45.2 | 28.9 | 42.1 |
| Deepgram | 35.8 | 33.9 | 40.4 | 27.8 | 50.7 | 40.0 | 32.1 | 46.7 | 28.4 | 40.3 |
Table 4: ASR baseline results. Chinese (zh) is evaluated by CER (%), while other languages are evaluated by WER(%). Whisper is fine-tuned monolingually (each language separately) or multilingually (all languages simultaneously). SpecAugment is tested on Whispe-small-mono as data augmentation. Commercial models like Assembly and Deepgram only allows direct recognition.
The fine-tuned Whisper-small model achieved superior performance to larger pre-trained models on the development set across all languages. On the test set, Whisper-small excelled for Vietnamese (29.60% WER) and Chinese (31.3% CER), while Whisper-large-v2 performed best for English (25.5% WER) and Chinese (37.3% CER), and Deepgram outperformed others in French (40.3% WER).
Monolingual fine-tuning consistently outperformed multilingual fine-tuning on both development and test sets, suggesting that language-specific optimization yields better results than trying to build a single model for all languages. Interestingly, SpecAugment data augmentation did not improve accuracy, contrary to findings in general-domain ASR.
Translation Quality on Perfect Transcripts
When evaluating MT models on ground-truth transcripts (without ASR errors), task-specific models outperformed multi-task models, particularly for encoder-decoder architectures with English as the source language.
Google Translate achieved the highest overall results across most language pairs, followed by encoder-decoder models like M2M100-418M, which recorded higher BLEU scores than the decoder-only LLMs in most language pairs (18/20). This demonstrates that models specifically trained for MT tasks generally outperform multi-task models like LLMs when working with perfect transcripts.
Real-world Performance: Cascaded Speech Translation
In cascaded ST, where ASR errors propagate to the MT component, the performance gap between task-specific and multi-task models narrowed significantly.
The combination of Whisper-large-v2 and M2M100-418M achieved the highest performance on most language pairs (16/20), except for Vietnamese as the source language, where Whisper-small-mono with M2M100-418M performed best. This highlights how ASR transcript quality impacts MT performance, with minor errors notably affecting complex languages like Vietnamese.
Interestingly, while M2M100-418M and mBart-large-50 outperformed LLMs on ground-truth transcripts, they did not show a significant advantage in the cascaded ST setting. This suggests that multi-task models (LLMs) perform competitively with task-specific models in real-world scenarios where transcripts contain errors.
End-to-End vs. Cascaded: The Translation Showdown
The comparison between end-to-end and cascaded approaches revealed a significant performance gap in favor of cascaded models.
| Model | Metrics | en-vi | en-fr | en-zh | en-de | vi-en | vi-fr | vi-zh | vi-de | fr-en | fr-vi | fr-zh | fr-de | de-en | de-vi | de-fr | de-zh | zh-en | zh-vi | zh-fr | zh-de |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cascaded | |||||||||||||||||||||
| Llama -3.1-8B | BLEU | 43.32 | 37.92 | 30.78 | 31.36 | 14.55 | 10.29 | 11.56 | 7.71 | 30.15 | 25.36 | 20.28 | 16.38 | 40.63 | 33.63 | 26.97 | 26.31 | 19.01 | 17.65 | 13.84 | 11.13 |
| BERTSc | 0.85 | 0.84 | 0.8 | 0.83 | 0.78 | 0.75 | 0.73 | 0.73 | 0.82 | 0.80 | 0.75 | 0.74 | 0.86 | 0.84 | 0.80 | 0.79 | 0.79 | 0.85 | 0.76 | 0.74 | |
| End-to-end | |||||||||||||||||||||
| SeamlessM4T -large-v2 | BLEU | 24,59 | 25,68 | 20,43 | 20,19 | 14,4 | 10,19 | 11,49 | 7,4 | 29,23 | 17,49 | 11,37 | 15,94 | 25,09 | 15,07 | 12,88 | 11,45 | 14,22 | 11,39 | 6,83 | 4,16 |
| BERTSc | 0,81 | 0,82 | 0,76 | 0,8 | 0,77 | 0,75 | 0,74 | 0,72 | 0,82 | 0,78 | 0,72 | 0,77 | 0,82 | 0,77 | 0,75 | 0,73 | 0.79 | 0,74 | 0,73 | 0,70 |
Table 6: End-to-End and Cascaded Comparison. All cascaded models use Whispersmall-mono as ASR model (Whisper ASR is fine-tuned monolingually - on each source language separately), then MT models translate into target languages. End-to-end Whisper for ST is fine-tuned bilingually - on each language pair separately. End-to-end Whisper ST only supports X to English, thus no results for other translation directions were reported.
These findings align with prior research in general-domain ST, suggesting that end-to-end models require extensive data (potentially thousands of hours) and numerous parameters to match the accuracy of cascaded models. This is particularly true for medical ST, where domain-specific terminology and precise translation are crucial. The results support the MultiMed approach of developing specialized components that can be combined effectively rather than attempting to solve all tasks with a single end-to-end model.
Language Pair Strategy: Bilingual vs. Multilingual Approaches
The comparison between bilingual and multilingual fine-tuning revealed important insights for optimizing MT models.
Fine-tuning MT models on all language pairs simultaneously resulted in performance degradation for most language pairs compared to fine-tuning on each language pair separately. This occurs because the shared parameters of the model must allocate their representational capacity across all pairs, leading to interference between language pairs, especially when their linguistic structures or vocabularies differ significantly.
However, when comparing pre-trained multilingual MT models with bilingual models (designed specifically for a language pair), the results showed that multilingual pre-trained models could match bilingual accuracy without requiring multiple language-pair variants. For example, while VinAI (a bilingual model) achieved the highest BLEU score (50.79) for English-to-Vietnamese, the multilingual M2M100-418M excelled in BERTScore (0.95 vs. 0.88 for VinAI).
This finding suggests an optimal strategy: use multilingual pre-trained MT models as the foundation, then apply bilingual fine-tuning on specific language pairs to achieve the best performance without maintaining separate models for each language direction.
Handling Medical Code-switching in Translation
Code-switching—retaining English terms or keywords in translations to other languages—is common in medical contexts. The analysis showed that multilingual pre-trained MT models handle code-switching effectively, even with large orthographic differences like English-Chinese or smaller differences like English-Vietnamese/German.
| MT | Metrics | Ground-truth | ASR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| en-vi | en-fr | en-zh | en-de | en-vi | en-fr | en-zh | en-de | ||
| Decoder | |||||||||
| Llama -3.1-8B | BLEU | 51.92 | 51.12 | 39.42 | 39.96 | 41.68 | 38.21 | 33.02 | 30.49 |
| BERTSc | 0.90 | 0.90 | 0.83 | 0.87 | 0.85 | 0.85 | 0.80 | 0.82 |
Table 9: Code-switch analysis. All ST results are from cascaded ST models with ASR transcript generated by Whisper Small fine-tuned monolingually on source language. The original dataset shows code-switching percentages of 11.2%, 7%, 7.9%, and 12.8% for Vietnamese, French, Chinese, and German, respectively.
The results from code-switching were not consistently lower or higher than ground-truth baselines or cascaded monolingual fine-tuning ST baselines, indicating that multilingual pre-trained MT models can process multiple languages simultaneously within a single context, regardless of orthographic differences.
Error Analysis: Understanding Translation Challenges
Quantitative Patterns: What the Numbers Tell Us
A strong correlation emerged between n-gram overlap metrics (like BLEU), embedding-based metrics (like BERTScore), and subjective evaluations from both LLM-as-a-judge and human assessments.
| Model | Metrics | en-vi | en-fr | en-zh | en-de | vi-en | vi-fr | vi-zh | vi-de | fr-en | fr-vi | fr-zh | fr-de | de-en | de-vi | de-fr | de-zh | zh-en | zh-vi | zh-fr | zh-de |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama -3.1-8B | BLEU | 41.79 | 36.14 | 32.71 | 28.19 | 15.41 | 10.71 | 19.55 | 8.33 | 27.47 | 21.63 | 18.05 | 17.40 | 36.47 | 27.50 | 27.06 | 25.05 | 20.48 | 21.52 | 15.37 | 10.64 |
| BERTSc | 0.85 | 0.84 | 0.82 | 0.82 | 0.78 | 0.76 | 0.78 | 0.74 | 0.81 | 0.79 | 0.77 | 0.78 | 0.85 | 0.82 | 0.83 | 0.80 | 0.80 | 0.79 | 0.77 | 0.77 | |
| LLM-judge | 5.14 | 4.64 | 4.45 | 4.63 | 3.88 | 3.49 | 3.15 | 3.41 | 4.38 | 4.01 | 3.43 | 3.44 | 5.81 | 5.39 | 4.52 | 4.06 | 3.88 | 3.61 | 3.78 | 3.69 | |
| Human | 6.85 | 6.47 | 4.31 | 8.53 | 6.54 | 5.64 | 4.12 | 7.24 | 5.19 | 5.45 | 4.04 | 6.42 | 6.15 | 8.05 | 6.64 | 4.14 | 4.08 | 3.58 | 5.64 | 6.54 |
Table 10: LLM-as-a-judge and human evaluation results. All ST results are from cascaded ST models with ASR transcript generated by Whisper Small fine-tuned monolingually on source language. A BERTScore of >0.8 is often seen as good translation quality. while >0.9 is excellent translation quality.
This alignment suggests that traditional automatic metrics remain reliable indicators of ST quality, even as evaluation methodologies evolve. The consistency across multiple evaluation approaches reinforces their validity in assessing adequacy, fluency, and comprehensibility of medical ST.
Common Translation Errors in Medical Content
The qualitative error analysis identified several recurring translation challenges across the five languages:
-
English source issues:
- Sentence fragmentation (notable in Chinese and Vietnamese translations)
- Literal idiom translation
- Inconsistent medical terminology
- Errors in proper noun handling
-
Vietnamese source issues:
- Grammatical errors in word order, verb tense, and articles
- Imprecise word choice and omissions
- Register inconsistencies
-
German source issues:
- Word order errors
- Literal idiom translations
- Case, gender, and verb conjugation issues (especially in French and Vietnamese)
-
Chinese source issues:
- Unnatural word-for-word translations
- Tense inaccuracies
- Missing grammatical elements
- Misused measure words
-
French source issues:
- Similar to English issues, plus
- Vietnamese grammar errors in word order and verb conjugation
These error patterns highlight the need for domain-specific and language-pair-specific improvements in medical ST systems, particularly for handling specialized terminology, idiomatic expressions, and language-specific grammatical structures.
Five Key Findings for Building Effective Medical Speech Translation
The research presents five critical insights for developing effective medical speech translation systems:
Task-specific vs. multi-task models show comparable performance in medical ST: Although task-specific models surpass multi-task models when evaluated on ground-truth transcripts, both exhibit comparable performance in the medical ST setting when handling ASR transcripts with errors.
Cascaded models significantly outperform end-to-end models: The traditional approach of separate ASR and MT components continues to provide superior results compared to direct speech-to-translated-text models, particularly in the specialized medical domain.
Multilingual pre-trained MT models with bilingual fine-tuning provide optimal results: This approach offers the best balance between performance and practical deployment concerns, allowing a single foundational model to be specialized for each language pair without requiring multiple separate variants.
Multilingual pre-trained MT models handle code-switching effectively: These models can process multiple languages simultaneously within a single context, handling both large orthographic differences (English-Chinese) and smaller differences (English-Vietnamese/German) with comparable effectiveness.
Traditional evaluation metrics correlate strongly with human judgment: N-gram overlap metrics show a strong correlation with both contextual embedding-based evaluation and subjective assessment, validating their continued use in assessing medical ST quality.
These findings provide a comprehensive framework for building and evaluating medical ST systems, balancing technical performance with practical implementation considerations. The MultiMed-ST dataset serves as a valuable foundation for further research and development in this critical area of healthcare communication.
Limitations and Ethical Considerations in Medical Speech Translation
Despite the significant contributions of the MultiMed-ST dataset and the insights gained from this research, several important limitations and ethical considerations must be acknowledged.
Medical research has direct implications for human health, making errors in ASR and ST outputs potentially serious. Given the critical nature of medical transcription, mistranslations could affect patient diagnoses and treatment decisions. Users of this research are strongly encouraged to independently verify the hypotheses and experimental results using their own medical data and to conduct pilot tests in simulated doctor-patient environments before deploying these technologies in real-world applications.
Data privacy and consent are paramount concerns in medical AI research. All data in the MultiMed-ST dataset has been thoroughly anonymized and de-identified to comply with privacy regulations such as HIPAA and GDPR. The dataset creation followed fair use principles, focusing on educational and research applications rather than commercial exploitation.
Technical limitations include challenges in long-form speech annotation, where timestamp mismatches can occur due to ASR model drift, variable speech rates, inconsistent segmentation, human annotation variability, background noise, and post-processing issues. These challenges highlight the ongoing need for improved annotation methodologies for medical speech data.
As speech translation technology continues to advance, researchers and practitioners must maintain a balanced approach that prioritizes patient safety, data privacy, and ethical deployment while pursuing technological innovation. The ultimate goal remains improving healthcare communication across language barriers, but this must be achieved with careful attention to both technical performance and ethical considerations.

Fine-tuning configuration of mBART-large-50 model
