
This is a Plain English Papers summary of a research paper called New Dataset: Boost Chinese Speech Recognition with Lip-Reading & Slides!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Enhancing Speech Recognition With Multiple Visual Cues
Automatic Speech Recognition (ASR) systems face numerous challenges in real-world scenarios, from background noise to specialized terminology. While incorporating visual modalities has proven beneficial, most existing approaches use either lip-reading information or contextual visuals, but rarely both. The new Chinese-LiPS dataset addresses this gap by integrating both lip-reading and presentation slides to create a comprehensive multimodal approach to speech recognition.
The research introduces both a high-quality dataset and a simple yet effective pipeline called LiPS-AVSR. This combination leverages lip movements and slides to achieve remarkable improvements in ASR performance. By combining these complementary visual sources, the system achieves a 35% improvement in recognition accuracy compared to audio-only approaches.
| Dataset | Speakers | Duration(h) | Language | Lip-reading Video | Contextual-cues(Slides/Video) | Year | Available |
|---|---|---|---|---|---|---|---|
| LRW [12] | $1000+$ | - | English | $\checkmark$ | - | 2018 | Y |
| LRS [13] | - | - | English | $\checkmark$ | - | 2017 | N |
| LRS2-BBC [3] | - | 200 | English | $\checkmark$ | - | 2018 | Y |
| LRS3-TED [14] | - | 400 | English | $\checkmark$ | - | 2018 | Y |
| LRW-1000 [15] | $2000+$ | 57 | Chinese | $\checkmark$ | - | 2018 | Y |
| CMLR [16] | - | - | Chinese | $\checkmark$ | - | 2019 | Y |
| CN-Celeb-AV [17] | 1,136 | 669 | Chinese | $\checkmark$ | - | 2023 | Y |
| CN-CVS [18] | 2,557 | $300+$ | Chinese | $\checkmark$ | - | 2023 | Y |
| How2 [19] | - | 2000 | Eng&Por | - | $\checkmark$ (instructional videos) | 2018 | Y |
| VisSpeech [7] | - | 0.6 | English | - | $\checkmark$ (Youtube videos) | 2022 | Y |
| SlideSpeech [9] | - | $1000+$ | English | - | $\checkmark$ (presentation slides) | 2023 | Y |
| SlideAVSR [8] | 220 | 36 | English | - | $\checkmark$ (Youtube videos) | 2024 | Y |
| AVNS [20] | - | $30+$ | English | - | $\checkmark$ (background scenes) | 2024 | Y |
| 3-Equations [21] | - | 25.2 | English | $\checkmark$ | $\checkmark$ (3-lines math formula) | 2024 | Y |
| Chinese-LiPS(ours) | 207 | 100 | Chinese | $\checkmark$ | $\checkmark$ (presentation slides) | 2024 | Y |
Comparison of Existing AVSR Datasets, Highlighting Lip-Reading and Contextual Information Availability
Unlike previous datasets like XLAVs-R, which focuses on cross-lingual challenges, Chinese-LiPS is specifically designed to combine multiple visual sources for Chinese speech recognition.
The Power of Lip-Reading in AVSR
Lip-reading provides one of the most accessible visual modalities for Audio-Visual Speech Recognition (AVSR). It captures articulation details like mouth movements and naturally synchronizes with audio timing. This makes it particularly valuable for understanding speech in challenging conditions.
Several English datasets have pioneered this approach, including LRW from television shows and the LRS series from BBC broadcasts and TED talks. For Chinese, datasets like CMLR and CN-CVS have been gathered from news broadcasts and diverse real-world settings.
Researchers have developed multiple approaches to leverage these datasets. Auto-AVSR and Whisper-Flamingo use feature fusion and cross-attention to integrate lip-reading with speech data. AV-HuBERT employs self-supervised learning to unify audio and visual information, significantly enhancing recognition performance. Advanced techniques like those in Target Speaker Lipreading by Audio-Visual Self-Attention further demonstrate how visual attention mechanisms can improve recognition of specific speakers.
Beyond Lips: Semantic Visual Context for Speech Understanding
While lip-reading focuses on articulation, semantic visual contextual cues provide complementary information that can further enhance ASR. These cues include presentation slides, background scenes, and other visual context that help disambiguate spoken content.
Several datasets have explored this approach. SlideSpeech uses textual and graphical content from slides to provide semantic context. How2 and AVNS leverage background scenes from the environment. VisSpeech and SlideAVSR, collected from video-sharing platforms, have also proven effective for improving ASR performance.
Current methods primarily use OCR to detect text within contextual elements, treating this as keywords to enhance recognition. Some approaches, like VisPer, employ pre-trained multimodal models like CLIP and DALL-E to extract semantic information from visual cues. However, most existing work has limited integration of multiple visual modalities. For example, one dataset combines speech, lip-reading, and visual context, but restricts the visual components to simple 3-line math formulas.
The Chinese-LiPS Dataset: A New Resource for Multimodal Speech Recognition
Building a High-Quality Multimodal Dataset
Chinese-LiPS represents the first high-quality multimodal Chinese AVSR dataset that integrates both lip-reading information and presentation slides. It contains approximately 100 hours of data with 36,208 clips from 207 speakers, with each clip including speech, slide video, and lip-reading video.
Unlike datasets built from web-scraped content, Chinese-LiPS features presentation slides created by domain experts to ensure content accuracy. The slides are carefully designed to avoid large blocks of text, with speakers going beyond merely reading the slides to deliver comprehensive explanations. This approach aligns with SynesLM research showing that integrated multimodal inputs yield superior recognition results.

Overview of slide styles and themes across different topics in the Chinese-LiPS dataset
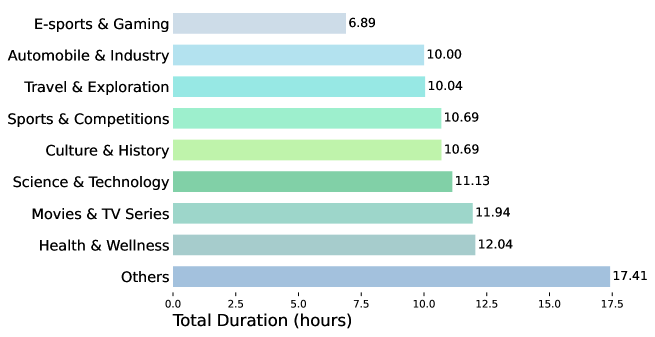
Distribution of total recording duration by topic
Breaking Down the Data: Diversity and Balance
The dataset covers nine diverse topic categories: E-sports & Gaming, Automobile & Industry, Travel & Exploration, Sport & Competitions, Culture & History, Science & Technology, Movies & TV Series, Health & Wellness, and Others. These topics were selected based on their popularity on social media platforms and their inclusion of domain-specific terminology.
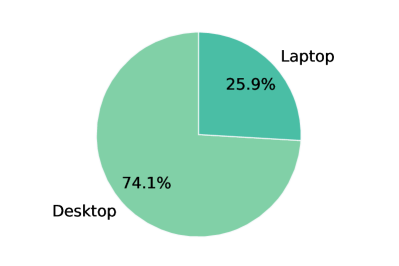
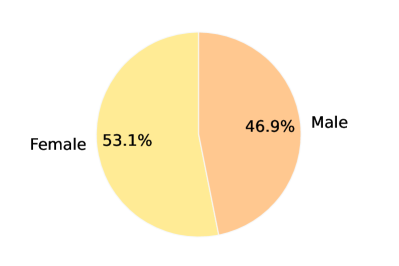
The Chinese-LiPS dataset maintains a balanced representation across several dimensions. The majority of speakers are professionals between 20-30 years old. Recording devices are primarily desktop computers (75%) and laptops (25%). Gender representation is balanced to minimize potential biases. Speech segments average 10 seconds in length, with none exceeding 30 seconds.
The dataset is split into 80% training, 15% testing, and 5% validation sets, with balanced gender and age distribution across subsets. Importantly, there is no overlap of speakers between different sets.
| Split | Duration(h) | Segments | Speakers | M:F | Topics |
|---|---|---|---|---|---|
| Train | 85.37 | 30341 | 175 | $1: 1.16$ | 9 |
| Test | 10.12 | 3908 | 21 | $1: 1.10$ | 9 |
| Validation | 5.35 | 1959 | 11 | $1: 0.83$ | 6 |
| All | 100.84 | 36208 | 207 | $1: 1.13$ | 9 |
Split details of Chinese-LiPS Dataset, M:F represents the ratio of male to female speakers
Testing the Hypothesis: Experimental Framework
LiPS-AVSR: A Pipeline for Multimodal Speech Recognition
The LiPS-AVSR pipeline leverages both Whisper and Whisper-Flamingo as its backbone. Whisper is a Transformer-based end-to-end model with strong speech recognition capabilities, while Whisper-Flamingo extends this by incorporating lip-reading information through AV-Hubert.
The pipeline extracts information from multiple modalities:
- PaddleOCR extracts textual information from slides
- InternVL2 captures semantic content from images and graphics
- AV-HuBERT extracts lip-reading features
These features are then integrated into Whisper's prompt format, creating a comprehensive input that enhances transcription accuracy.
LiPS-AVSR pipeline illustration
Experiment Setup: Rigorous Testing Framework
The data preprocessing includes several specific steps for each modality:
- Speech is processed at a 16 kHz sampling rate
- Lip regions are detected and resized to 96×96 resolution at 25 frames per second
- For slides, the first frame is extracted for OCR and semantic analysis
Experiments were conducted using the Whisper large-v2 model across two main settings:
- Speech-only: Using the original Whisper model fine-tuned with Chinese-LiPS training data
- Speech + Lip-reading: Fine-tuning the gated cross-attention layer of Whisper-Flamingo
For each setting, four prompt configurations were tested:
- No prompt
- OCR-extracted text only
- InternVL2-extracted semantic information only
- Combined OCR and InternVL2 features
The best-performing speech-only model was selected as the baseline for comparison.
Evaluation Method: Character Error Rate
The experiments used Character Error Rate (CER) as the evaluation metric, calculated as:
CER = (S + D + I) / N
Where S, D, and I represent substitution, deletion, and insertion errors, and N is the total number of characters in the reference. This metric is particularly appropriate for Chinese speech recognition, as it directly measures character-level accuracy.
Results: Confirming the Multimodal Advantage
The experimental results demonstrate the significant benefits of integrating multiple modalities. The original Whisper model with only speech achieved a CER of 3.99%. Adding visual information from slides (OCR and InternVL2) improved performance substantially, with their combination reducing CER to 2.99%—a 25% improvement.
Lip-reading features contributed an 8% performance improvement on their own. When all modalities were combined (speech, lip-reading, OCR, and InternVL2), the CER dropped to 2.58%, representing a 35% overall improvement.
| ID | Speech | Lip-reading | OCR | InternVL2 | CER(\%) $\downarrow$ |
|---|---|---|---|---|---|
| 1(baseline) | $\checkmark$ | 3.99 | |||
| 2 | $\checkmark$ | $\checkmark$ | 3.37 | ||
| 3 | $\checkmark$ | $\checkmark$ | 3.33 | ||
| 4 | $\checkmark$ | $\checkmark$ | $\checkmark$ | 2.99 | |
| 5 | $\checkmark$ | $\checkmark$ | 3.69 | ||
| 6 | $\checkmark$ | $\checkmark$ | $\checkmark$ | 2.74 | |
| 7 | $\checkmark$ | $\checkmark$ | $\checkmark$ | 3.05 | |
| 8 | $\checkmark$ | $\checkmark$ | $\checkmark$ | $\checkmark$ | 2.58 |
Performance Comparison of Whisper-Large-V2 on Chinese-LiPS
Error correction examples using slide and lip-reading information
Understanding the Benefits: Error Analysis
Detailed error analysis reveals that different modalities address specific types of errors:
Lip-reading primarily reduces deletion errors, decreasing them from 1697 to 509—a substantial improvement. This aligns with the hypothesis that lip-reading conveys articulation-related information, helping recover filler words, hesitation markers, and incomplete speech segments.
Presentation slides contribute significantly to reducing substitution errors, dropping from 3851 to 3531. They also help address some deletion errors, especially for domain-specific terms. This demonstrates how slides provide semantic and contextual information crucial for recognizing specialized vocabulary and proper nouns.
The SynesLM approach similarly found that multimodal information sources complement each other to provide more robust speech recognition across varying conditions.
| ID | Modality | Substitution $\downarrow$ | Deletion $\downarrow$ | Insertion $\downarrow$ |
|---|---|---|---|---|
| 1 | Speech only | 3851 | 1697 | 437 |
| 4 | Speech + Slides | $3531 \downarrow$ | 447 $\downarrow$ | 510 |
| 5 | Speech + Lip | 4499 | $509 \downarrow$ | 522 |
| 8 | Speech + Lip + Sli | $3047 \downarrow$ | $335 \downarrow$ | 484 |
Error Analysis Across Different Modalities in the Test Set: Total Number of Chinese Characters = 150,059
Conclusion: The Future of Multimodal Speech Recognition
The Chinese-LiPS dataset and LiPS-AVSR pipeline demonstrate that combining lip-reading and presentation slide information can significantly enhance speech recognition performance. This approach leverages the complementary strengths of different visual modalities: lip-reading captures articulation details, while slides provide semantic context and domain-specific terminology.
The research confirms that these modalities don't just provide redundant information—they address different types of errors. Lip-reading helps recover missing words and filler content, while slides improve accuracy for specialized terms that might otherwise be misinterpreted.
As speech recognition systems continue to evolve, this type of multimodal integration represents a promising direction for creating more robust and accurate solutions, particularly for challenging real-world applications like educational content, lectures, and presentations.
The Chinese-LiPS dataset will enable further research into multimodal speech recognition for Chinese language applications, filling an important gap in available resources for this widely-spoken language.
