Hoje em dia todo mundo utiliza modelos de LLM gigantes gratuitamente via chat, o que é ótimo. Mas caso você queira desenvolver alguma aplicação específica, irá usar algum modelo pré-treinado menor, provavelmente algum gratuito do hugging face.
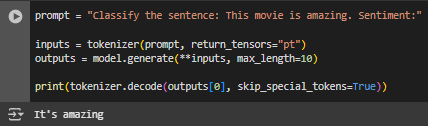
Caso você esteja utilizando um modelo menor (como o T5, por exemplo, que foi o que utilizei aqui para fazer os testes), existem alguma estratégias de criação de prompt que irão afetar o desempenho. Vamos supor que você quer envie esse prompt "Classifique esse review: Esse filme é muito bom! Sentimento:" esperando que ele diga se o sentimento será positivo ou negativo. Ele terá um desempenho ruim.
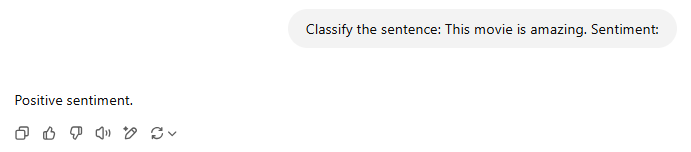
Já o GPT-4o faz essa análise perfeitamente. Essa ténica de prompt de não dar nenhum exemplo se chama zero-shot inference.
Porém, se você adicionar um exemplo, o modelo menor irá funcionar melhor. Essa técnica é chamada de one-shot inference. Caso não funcione, você pode utilizar a few-shot inference, que imagino que já deu pra entender o que é (dar mais de um exemplo).

Caso dar vários exemplos ainda não funcione, as técnicas de prompt não irão te salvar, você irá precisar de um fine-tuning, que é o processo de ajustar o modelo ao seu conjunto de dados para melhorar o desempenho dele em alguma tarefa específica.