Introduction to Searching Techniques: Binary Search vs. Hashing
In computer science, searching is one of the most crucial operations that helps us locate data quickly and efficiently. Whether we are looking up a contact in our phone, searching for a word in a dictionary, or retrieving records from a massive database, search algorithms are indispensable. As the volume of data grows from millions to billions of records, the performance of search algorithms becomes a significant factor in determining how fast applications run.
In this article, we will dive into two fundamental search techniques: Binary Search and Hashing. We will compare these methods in terms of their efficiency, implementation, and use cases, making them easier to understand, even for beginners.
What is Binary Search?
Binary Search is an algorithm that works by repeatedly dividing the search space in half. It is particularly useful for finding an element in a sorted array. Unlike Linear Search, which examines each element sequentially, Binary Search narrows down the search area quickly by halving it at each step.
To illustrate how Binary Search works, let’s take a sorted list of numbers:
[10, 22, 29, 37, 45, 51, 67, 72, 89]Imagine we need to search for the number 37 in this list:
- The first step is to find the middle element, which in this case is 45 (element at index 4).
- Since 37 < 45, we discard the right half and focus on the left half:
[10, 22, 29, 37]- The new middle element is 29. Since 37 > 29, we discard the left half:
[37]- We found the target element 37!
This technique works by halving the search space after each comparison, leading to a time complexity of O(log n), making it much more efficient than Linear Search (O(n)).
What is Hashing?
Hashing is a different method of searching that works by converting a piece of data (such as a string or a number) into a fixed-size hash value through a hash function. This hash value is then used as an index in a hash table to store and retrieve data quickly. Hashing provides constant-time access (O(1)) in most cases.
For example, consider a hash function:
hash(ID) = ID % 10If we want to store a student ID 105, we compute:
105 % 10 = 5Thus, the value would be stored at index 5 in the hash table. To retrieve it, we apply the same hash function and look up index 5.
However, if two different keys hash to the same index (a collision), we might have to handle it using techniques like chaining or open addressing. In the worst case, searching in a hash table could take O(n) time, but in the average case, it remains O(1).
Common Use Cases of Hashing:
- Password Storage (securely hashing passwords before storing them)
- Caching (e.g., web browsers cache frequently visited sites)
- Database Indexing (quickly retrieving records based on keys)
Comparing Binary Search and Hashing
Both Binary Search and Hashing are extremely efficient search techniques, but each is suited to different types of data and use cases.
| Feature | Binary Search | Hashing |
|---|---|---|
| Data Requirement | Requires sorted data | Works with unsorted data |
| Time Complexity | O(log n) | O(1) (best case), O(n) (worst case) |
| Best Use Case | Searching in sorted datasets, range queries | Fast lookups, inserts, and deletes |
| Example Use Case | Searching in dictionaries, sorted databases | Caching, database indexing |
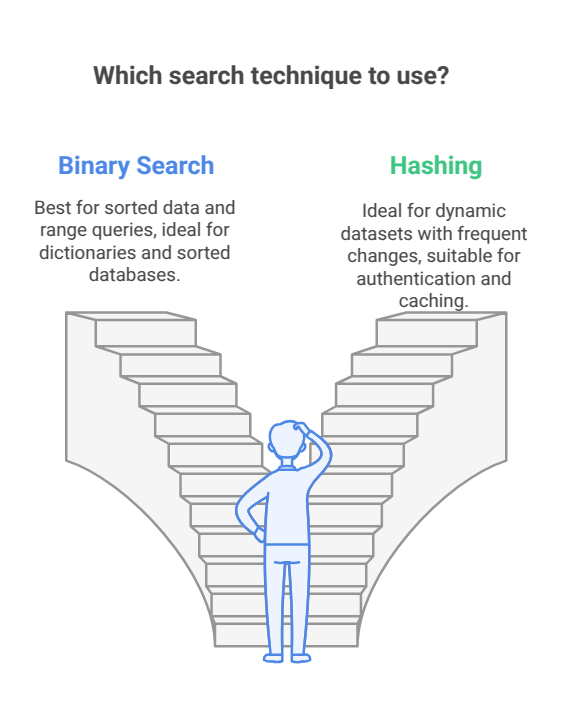
When to Use Binary Search vs. Hashing
-
Use Binary Search when:
- The dataset is sorted.
- You need to perform range queries (e.g., finding values between 10 and 30).
- Memory efficiency is important (since Binary Search does not require extra space like a hash table).
-
Use Hashing when:
- The dataset is dynamic (frequent inserts, updates, or deletions).
- Constant-time lookups are required.
- Extra memory is available to store the hash table.
Conclusion
Both Binary Search and Hashing are powerful search techniques with their own strengths and trade-offs. Binary Search excels when working with sorted data, making it ideal for static datasets requiring efficient searching. Hashing, on the other hand, is best for applications that require fast lookups and dynamic data handling.
By understanding the strengths of each technique, you can make informed decisions on which one to use based on your specific needs. Choosing the right algorithm can greatly optimize your application’s performance, making it faster, more efficient, and more user-friendly.