
Introduction
In the world of AI research and development, computational resources are pushed to their limits. This fact was humorously highlighted by OpenAI CEO Sam Altman's memorable tweet: "our GPUs are melting" - a testament to the intense workloads these specialized processors endure during advanced AI training.
While Altman's tweet was likely hyperbolic, the concern about GPU health is very real. Modern data centers and AI research facilities invest millions in GPU infrastructure, making temperature monitoring a critical operational concern. Overheating can lead to hardware damage, reduced lifespan, and even catastrophic failures that interrupt crucial workloads.
This article explores a practical implementation of a GPU temperature monitoring system built with Go (Golang). We'll demonstrate how to create a complete pipeline for:
Generating simulated GPU temperature data
Publishing these events to Redpanda (a Kafka API-compatible streaming platform)
Consuming these events in real-time
Triggering alerts when temperatures exceed critical thresholds
Go's combination of performance, concurrency model, and straightforward syntax makes it an excellent choice for building such systems.
The solution we'll explore is lightweight yet robust, capable of handling thousands of events per second while maintaining low latency - perfect for mission-critical monitoring applications.
Whether you're managing a small GPU cluster for research or a massive data center for production AI workloads, the patterns demonstrated here can be adapted to build a reliable early warning system that might just prevent your own GPUs from metaphorically (or literally) melting down.
Architecture Overview

The GPU Temperature Monitoring System employs an event-driven microservices architecture to track GPU temperatures in real-time and alert on potentially dangerous conditions. Built with Go, it leverages Redpanda (Kafka API-compatible) as the central event streaming platform.
Core Components
Temperature Publisher Service
Purpose: Simulates/collects GPU temperature readings and publishes to Redpanda
Key Features:
- Configurable simulation of multiple GPU devices
- Randomized temperature patterns with occasional anomalies
- Efficient event serialization using JSON
- Batched publishing for throughput optimization
Alert Consumer Service
Purpose: Monitors temperature stream and triggers alerts when thresholds are exceeded
Key Features:
- Real-time consumption of temperature events
- Threshold-based alerting logic with configurable thresholds
- Cooldown mechanism to prevent alert storms
- Integration with Slack for immediate notifications
Redpanda (Event Streaming Platform)
Purpose: Provides reliable, high-throughput messaging between services
Configuration:
- Two-node cluster for redundancy
- Topic-based event segregation
- Persistent storage of temperature data
Data Flow
- GPU temperature readings are generated/collected by the Publisher
- Events are serialized to JSON and published to the gpu-temperature topic
- Alert Consumer subscribes to the topic and processes each reading
- When temperatures exceed thresholds, the Consumer formats and sends Slack alerts
- All temperature data remains available in Redpanda for historical analysis
Technical Considerations
Scalability: Both services can be horizontally scaled to handle more GPUs
Resilience: Components reconnect automatically after network disruptions
Observability: Structured logging throughout the pipeline
Configuration: Environment-based configuration for deployment flexibility
Containerization: Docker-based deployment for consistent environments
This architecture demonstrates how Go's concurrency model and Redpanda's streaming capabilities can be combined to create an efficient, real-time monitoring system that helps prevent hardware damage from GPU overheating conditions.
Temperature Publisher Service :: Producer
Repository: https://github.com/snepar/gpu-temp-publisher
The Temperature Publisher Service forms the foundation of our GPU monitoring system. Written in Go, this service simulates multiple GPU devices and publishes temperature readings to Redpanda. Let's explore the core components with key code snippets.
Data Model
At the heart of our system is the temperature reading model:
type TemperatureReading struct {
DeviceID string `json:"device_id"`
Temperature float64 `json:"temperature"`
Timestamp time.Time `json:"timestamp"`
GPUModel string `json:"gpu_model"`
HostName string `json:"host_name"`
PowerConsume float64 `json:"power_consume"`
GPUUtil float64 `json:"gpu_util"`
}This structure encapsulates all the essential data points for monitoring GPU health.
Temperature Simulation
The service generates realistic temperature patterns using a combination of baseline values, utilization-based adjustments, and random fluctuations:
func (s *TemperatureSimulator) generateDeviceReading(deviceIndex int, device GPUDevice) TemperatureReading {
// Decide if this reading should be abnormal
isAbnormal := s.rng.Float64() < s.abnormalProbability
// Update GPU utilization with realistic movements
targetUtil := s.utilization[deviceIndex]
if s.rng.Float64() < 0.1 {
// 10% chance of changing target utilization significantly
targetUtil = s.rng.Float64() * 100
}
// Calculate temperature based on utilization and trend
baseTemp := device.BaseTemp
utilizationFactor := s.utilization[deviceIndex] / 100 * 40
temperature := baseTemp + utilizationFactor + s.tempTrend[deviceIndex]
// Apply abnormal spike if needed
if isAbnormal {
temperature += s.rng.Float64() * 100
}
return TemperatureReading{
DeviceID: device.ID,
Temperature: temperature,
Timestamp: time.Now(),
GPUModel: device.Model,
HostName: device.Host,
PowerConsume: s.utilization[deviceIndex] * 3.5 + temperature/4,
GPUUtil: s.utilization[deviceIndex],
}
}This simulation logic creates realistic temperature patterns that mimic actual GPU behavior, including occasional temperature spikes.
Publishing to Redpanda
// NewRedpandaPublisher creates a new Redpanda publisher
func NewRedpandaPublisher(ctx context.Context, brokers, topic string) (*RedpandaPublisher, error) {
// Create client options
opts := []kgo.Opt{
kgo.SeedBrokers(strings.Split(brokers, ",")...),
kgo.DefaultProduceTopic(topic),
kgo.AllowAutoTopicCreation(),
kgo.ProducerBatchMaxBytes(1024 * 1024), // 1MB
kgo.ProducerLinger(5 * time.Millisecond),
kgo.RecordRetries(5),
}
// Create client with retry logic
client, err := kgo.NewClient(opts...)
if err != nil {
return nil, fmt.Errorf("failed to create Redpanda client: %w", err)
}
return &RedpandaPublisher{
client: client,
topic: topic,
}, nil
}The actual publishing of readings happens through a simple but effective method:
// PublishReading publishes a temperature reading to Redpanda
func (p *RedpandaPublisher) PublishReading(ctx context.Context, reading TemperatureReading) error {
// Marshal reading to JSON
data, err := json.Marshal(reading)
if err != nil {
return fmt.Errorf("failed to marshal reading: %w", err)
}
// Create record with metadata
record := &kgo.Record{
Key: []byte(reading.DeviceID),
Value: data,
Topic: p.topic,
Headers: []kgo.RecordHeader{
{Key: "content-type", Value: []byte("application/json")},
},
}
// Produce record with error handling
result := p.client.ProduceSync(ctx, record)
if err := result.FirstErr(); err != nil {
return fmt.Errorf("failed to produce record: %w", err)
}
return nil
}Main Service Loop
The service's main loop ties everything together:
func main() {
// Load configuration
cfg, err := config.Load()
if err != nil {
log.Fatalf("Failed to load configuration: %v", err)
}
// Create temperature simulator
sim := simulator.NewTemperatureSimulator(cfg.NumDevices, cfg.AbnormalProbability)
// Create publisher
pub, err := publisher.NewRedpandaPublisher(ctx, cfg.RedpandaBrokers, cfg.Topic)
if err != nil {
log.Fatalf("Failed to create Redpanda publisher: %v", err)
}
defer pub.Close()
// Set up ticker for regular publishing
ticker := time.NewTicker(time.Duration(cfg.IntervalMs) * time.Millisecond)
defer ticker.Stop()
// Main loop
for {
select {
case <-ticker.C:
// Generate and publish temperature readings
readings := sim.GenerateReadings()
for _, reading := range readings {
if err := pub.PublishReading(ctx, reading); err != nil {
log.Printf("Error publishing reading: %v", err)
} else if reading.Temperature > 80.0 {
log.Printf("Published HIGH TEMP: Device %s - %.2f°C",
reading.DeviceID, reading.Temperature)
}
}
case <-sigChan:
return // Graceful shutdown
}
}
}Configuration via Environment Variables
The service is easily configurable through environment variables:
func Load() (*Config, error) {
config := &Config{
RedpandaBrokers: getEnv("REDPANDA_BROKERS", "localhost:9092"),
Topic: getEnv("REDPANDA_TOPIC", "gpu-temperature"),
NumDevices: getEnvAsInt("NUM_DEVICES", 5),
IntervalMs: getEnvAsInt("INTERVAL_MS", 1000),
AbnormalProbability: getEnvAsFloat("ABNORMAL_PROBABILITY", 0.05),
}
return config, nil
}This approach makes the service highly configurable while maintaining sensible defaults.
Containerization
FROM golang:1.21-alpine AS builder
WORKDIR /app
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o /gpu-temp-publisher ./cmd/publisher
FROM alpine:3.18
COPY --from=builder /gpu-temp-publisher .
ENTRYPOINT ["/gpu-temp-publisher"]Alert Generator Service :: Consumer
Repository: https://github.com/snepar/gpu-temp-alert
The Temperature Alert Service is the vigilant guardian in our GPU monitoring system. This service consumes temperature readings from Redpanda, analyzes them in real-time, and triggers alerts when temperatures reach dangerous levels. Let's explore how this service works with key code snippets.
Consumer Implementation
The core of the alert service is the Redpanda consumer that processes the stream of temperature readings:
// RedpandaConsumer consumes temperature readings from Redpanda
type RedpandaConsumer struct {
client *kgo.Client
topic string
temperatureThreshold float64
notifier *notifier.SlackNotifier
seenAlerts map[string]time.Time
seenAlertsMutex sync.Mutex
alertCooldown time.Duration
}This structure maintains the Redpanda client connection, configuration values, and a map to track recent alerts to prevent alert storms.
Connecting to Redpanda
The consumer establishes a connection to Redpanda with careful error handling and retry logic:
func NewRedpandaConsumer(ctx context.Context, brokers, topic, consumerGroup string,
temperatureThreshold float64, notifier *notifier.SlackNotifier) (*RedpandaConsumer, error) {
// Create Redpanda client options
opts := []kgo.Opt{
kgo.SeedBrokers(strings.Split(brokers, ",")...),
kgo.ConsumerGroup(consumerGroup),
kgo.ConsumeTopics(topic),
kgo.ConsumeResetOffset(kgo.NewOffset().AtEnd()), // Start from newest messages
kgo.DisableAutoCommit(), // Manual commit for better control
kgo.SessionTimeout(30 * time.Second),
}
// Create client with retry logic
client, err := kgo.NewClient(opts...)
if err != nil {
return nil, fmt.Errorf("failed to create Redpanda client: %w", err)
}
return &RedpandaConsumer{
client: client,
topic: topic,
temperatureThreshold: temperatureThreshold,
notifier: notifier,
seenAlerts: make(map[string]time.Time),
alertCooldown: 5 * time.Minute, // Prevent alert storms
}, nil
}Processing Temperature Readings
The service continuously polls for new temperature readings and processes them:
func (c *RedpandaConsumer) Start(ctx context.Context) error {
log.Printf("Starting to consume from topic %s", c.topic)
log.Printf("Monitoring for temperatures above %.2f°C", c.temperatureThreshold)
for {
select {
case <-ctx.Done():
return nil // Graceful shutdown
default:
// Poll for messages
fetches := c.client.PollFetches(ctx)
if fetches.IsClientClosed() {
return fmt.Errorf("client closed")
}
// Process each record
fetches.EachRecord(func(record *kgo.Record) {
c.processRecord(ctx, record)
})
// Commit offsets
if err := c.client.CommitUncommittedOffsets(ctx); err != nil {
log.Printf("Error committing offsets: %v", err)
}
}
}
}Temperature Threshold Detection
The core logic for detecting high temperatures and triggering alerts:
func (c *RedpandaConsumer) processRecord(ctx context.Context, record *kgo.Record) {
// Parse the temperature reading
var reading model.TemperatureReading
if err := json.Unmarshal(record.Value, &reading); err != nil {
log.Printf("Error parsing record: %v", err)
return
}
// Check if temperature exceeds threshold
if reading.Temperature > c.temperatureThreshold {
// Check if we've already alerted for this device recently
if c.shouldSendAlert(reading.DeviceID) {
log.Printf("HIGH TEMPERATURE ALERT: Device %s - %.2f°C exceeds threshold of %.2f°C",
reading.DeviceID, reading.Temperature, c.temperatureThreshold)
// Create alert event
alert := &model.AlertEvent{
DeviceID: reading.DeviceID,
Temperature: reading.Temperature,
Timestamp: reading.Timestamp,
TemperatureThreshold: c.temperatureThreshold,
GPUModel: reading.GPUModel,
HostName: reading.HostName,
PowerConsume: reading.PowerConsume,
GPUUtil: reading.GPUUtil,
}
// Send notification to Slack
if err := c.notifier.SendTemperatureAlert(ctx, alert); err != nil {
log.Printf("Failed to send alert to Slack: %v", err)
}
}
}
}Alert Cooldown Mechanism
To prevent alert storms, the service implements a cooldown period for each device:
func (c *RedpandaConsumer) shouldSendAlert(deviceID string) bool {
c.seenAlertsMutex.Lock()
defer c.seenAlertsMutex.Unlock()
now := time.Now()
if lastAlerted, exists := c.seenAlerts[deviceID]; exists {
// If last alert was less than cooldown period ago, don't alert
if now.Sub(lastAlerted) < c.alertCooldown {
return false
}
}
// Update last alerted time
c.seenAlerts[deviceID] = now
return true
}This prevents notification fatigue by limiting alerts for the same device to a reasonable frequency.
Slack Integration
The service integrates with Slack to deliver immediate alerts when GPUs are overheating:
func (s *SlackNotifier) SendTemperatureAlert(ctx context.Context, alert *model.AlertEvent) error {
// Determine color based on severity
color := "#FF0000" // Default to red
if alert.Temperature < alert.TemperatureThreshold+20 {
color = "#FFA500" // Orange for less severe
}
// Create attachment
attachment := Attachment{
Fallback: fmt.Sprintf("GPU IS MELTING: %.2f°C on %s", alert.Temperature, alert.DeviceID),
Color: color,
Title: "🔥 GPU IS MELTING 🔥",
Text: fmt.Sprintf("Temperature of *%.2f°C* detected, exceeding threshold of *%.2f°C*",
alert.Temperature, alert.TemperatureThreshold),
Timestamp: alert.Timestamp.Unix(),
Fields: []Field{
{
Title: "Device ID",
Value: alert.DeviceID,
Short: true,
},
{
Title: "Temperature",
Value: fmt.Sprintf("%.2f°C", alert.Temperature),
Short: true,
},
// Additional fields omitted for brevity
},
}
slackMsg := SlackMessage{
Channel: s.channel,
Username: "GPU Temperature Monitor",
IconEmoji: ":fire:",
Attachments: []Attachment{attachment},
}
return s.sendMessage(ctx, slackMsg)
}This creates visually striking alerts that draw immediate attention to overheating GPUs.
Main Service Initialization
The service's main function handles setup and graceful shutdown:
func main() {
// Load configuration
cfg, err := config.Load()
if err != nil {
log.Fatalf("Failed to load configuration: %v", err)
}
// Create context that can be cancelled
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// Create Slack notifier
slack, err := notifier.NewSlackNotifier(cfg.SlackWebhookURL, cfg.SlackChannel)
if err != nil {
log.Fatalf("Failed to create Slack notifier: %v", err)
}
// Create consumer
cons, err := consumer.NewRedpandaConsumer(
ctx,
cfg.RedpandaBrokers,
cfg.SourceTopic,
cfg.ConsumerGroup,
cfg.TemperatureThreshold,
slack,
)
if err != nil {
log.Fatalf("Failed to create Redpanda consumer: %v", err)
}
defer cons.Close()
// Start consuming in a separate goroutine
go func() {
if err := cons.Start(ctx); err != nil {
log.Printf("Consumer error: %v, shutting down", err)
cancel()
}
}()
// Wait for shutdown signal
<-sigChan
log.Println("Shutting down gracefully")
}Environment-Based Configuration
Like the publisher service, the alert service uses environment variables for configuration:
func Load() (*Config, error) {
config := &Config{
RedpandaBrokers: getEnv("REDPANDA_BROKERS", "localhost:9092"),
SourceTopic: getEnv("SOURCE_TOPIC", "gpu-temperature"),
ConsumerGroup: getEnv("CONSUMER_GROUP", "gpu-temp-alert-group"),
TemperatureThreshold: getEnvAsFloat("TEMPERATURE_THRESHOLD", 190.0),
SlackWebhookURL: getEnv("SLACK_WEBHOOK_URL", ""),
SlackChannel: getEnv("SLACK_CHANNEL", "#alerts"),
}
// Validation omitted for brevity
return config, nil
}The Temperature Alert Service exemplifies how Go's strong concurrency model and straightforward error handling make it ideal for building reliable monitoring systems. By consuming temperature data from Redpanda and triggering immediate alerts when thresholds are exceeded, this service provides the critical "last mile" in preventing GPU damage.
The combination of efficient stream processing, intelligent alert suppression, and actionable notifications creates a monitoring solution that can help prevent the scenario that Sam Altman humorously tweeted about - truly melting GPUs.
Implementation Guide
This guide will walk you through setting up and running both services of our GPU temperature monitoring system. Follow these steps to deploy the publisher for generating temperature readings and the alert service for monitoring critical temperatures.
Prerequisites
- Docker and Docker Compose installed
- A Slack workspace with webhook URL configured
Build and Run the Publisher
docker-compose up -dThis will start the Redpanda cluster and the publisher service.
Monitor the Redpanda Console
Open your browser and navigate to http://localhost:8080 to access the Redpanda Console.
Verify Publisher is Running
docker logs -f gpu-temp-publisherYou should see output similar to this:
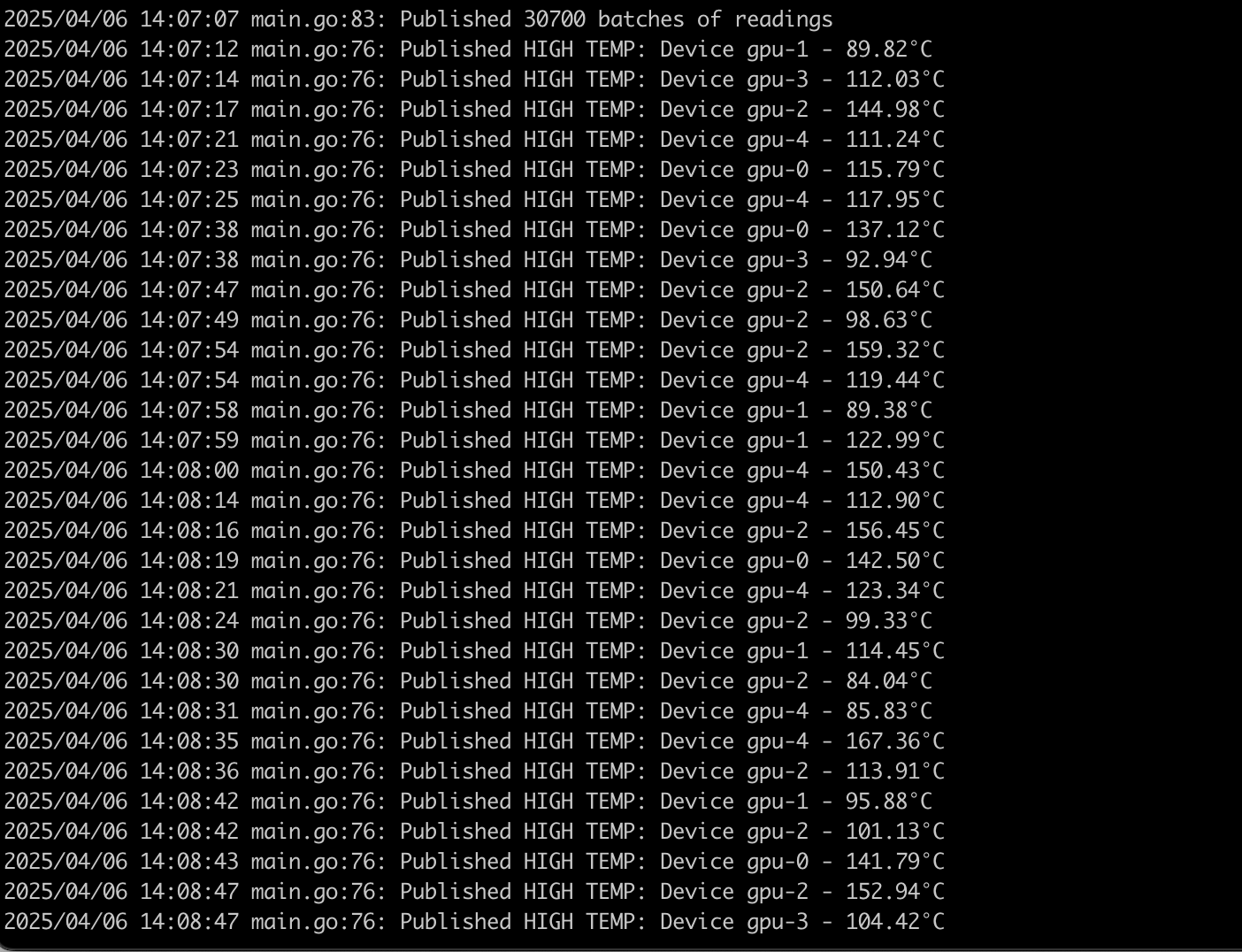
Build and Run the Alert Consumer
docker-compose up -dVerify Alert Service is Running
docker logs -f gpu-temp-alertYou should see output similar to this:
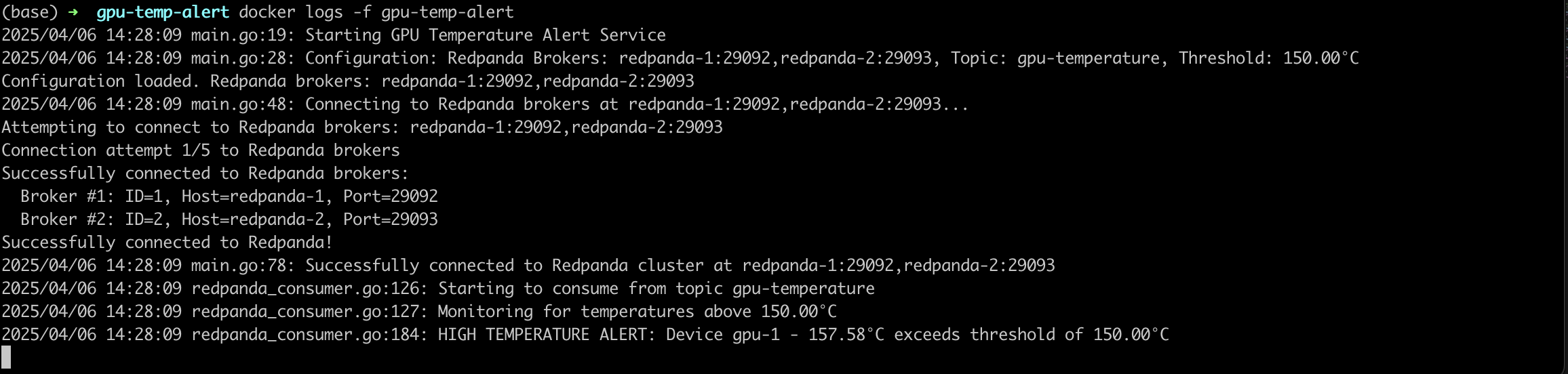
Update Slack Webhook URL
Edit docker-compose.yml and replace YOUR_WEBHOOK_URL with your actual Slack webhook URL:
- SLACK_WEBHOOK_URL=https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXXCheck Slack for Alerts
When a temperature exceeds the threshold, you should see an alert in your configured Slack channel:
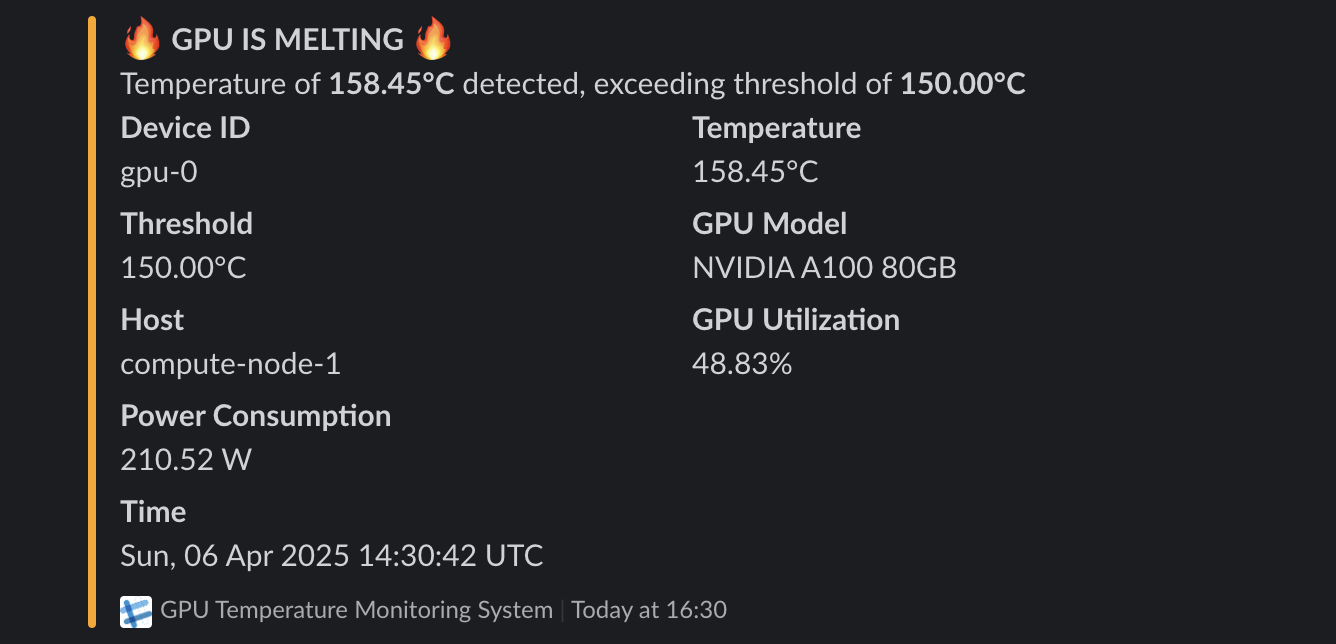
This GPU temperature monitoring system, while inspired by Sam Altman's humorous "our GPUs are melting" tweet, is primarily a hypothetical scenario designed to demonstrate how Go and Kafka-compatible messaging systems like Redpanda can be effectively combined to build real-time event processing pipelines. Through this example, we've explored fundamental patterns in event-driven architecture, stream processing, and alerting that can be applied to many real-world monitoring challenges, all while learning practical Go programming techniques.
