Introduction
On April 28, 2025, Snowflake added Boosts / Decays to Cortex Search, their managed solution for building Retrieval-Augmented Generation (RAG) applications. This feature enables you to flexibly adjust search scores based on numeric metadata (e.g., likes, view count) and timestamps, significantly enhancing the relevance of search results in RAG applications.
For this article, I've built a simple RAG chatbot that demonstrates the power of Boosts & Decays. I've kept the code straightforward and implemented everything in Streamlit in Snowflake (SiS) for easy testing and customization.
Note: This article represents my personal views and not those of Snowflake.
Boosts & Decays Overview
| Feature | Purpose | Key Parameters |
|---|---|---|
| Numeric Boosts | Increase search score based on numeric column values |
column, weight
|
| Time Decays | Adjust search score based on timestamp/date column (favoring recent data) |
column, weight, limit_hours
|
Official documentation: https://docs.snowflake.com/en/user-guide/snowflake-cortex/cortex-search/boosts-decays
Configuration is passed as a JSON scoring_config parameter:
scoring_config = {
"functions": {
"numeric_boosts": [
{"column": "likes", "weight": 1} # Boost by likes value
],
"time_decays": [
{"column": "created_at", "weight": 1, "limit_hours": 240} # Favor documents <10 days old
]
}
}You can set multiple boosts/decays simultaneously and adjust their weight to create different search experiences like "popularity-focused" or "freshness-focused."
Business Impact of Boosts & Decays
| Issue | Traditional RAG | With Boosts & Decays |
|---|---|---|
| Search quality | Documents with high vector similarity but low value to users may rank high | Popular content rises to the top based on user feedback (likes, views) |
| Information freshness | Outdated documents may appear alongside current ones | Recent documents prioritized with time decay, reducing reliance on old information |
| User experience | User feedback doesn't influence search ranking |
Continuous improvement loop - 👍 button updates likes column, immediately improving future results |
Potential Applications
- Internal knowledge bases – Automatically surface frequently referenced docs, demote outdated procedures
- Customer support FAQs – Let agents mark helpful answers to improve future suggestions
- Content recommendations – Rank marketing materials based on engagement metrics
- Document management – Balance recency and popularity in search results
From an ROI perspective, implementing the feedback loop entirely within Snowflake reduces the complexity and cost of integrating external services while accelerating the continuous improvement cycle.
Application Architecture
I've built a Streamlit in Snowflake (SiS) RAG chatbot application that demonstrates Boosts & Decays. The app handles the entire workflow:
- File upload – Upload text files or PDFs from your local machine to a Snowflake stage
-
Chunking – Split documents into smaller chunks using
SNOWFLAKE.CORTEX.SPLIT_TEXT_RECURSIVE_CHARACTER - Bulk insert – Store chunks in a table with metadata (filename, timestamp, likes counter)
- Cortex Search Service – Create service targeting the document table
-
Boosted search – Apply
likesandcreated_atscoring when searching -
Answer generation – Generate responses from search results using
COMPLETEfunction - Reference documents – Display chunks used with metadata and interactive elements
- Feedback mechanism – 👍 button to increase like count on helpful chunks
- Download functionality – Retrieve original files from stage
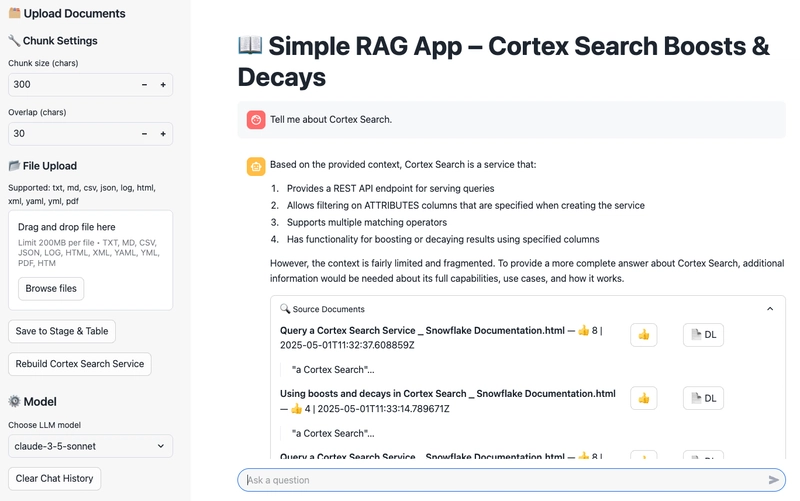
Demo Screenshots
Application overview with upload panel and chat interface
Support for multiple file types including HTML and PDF
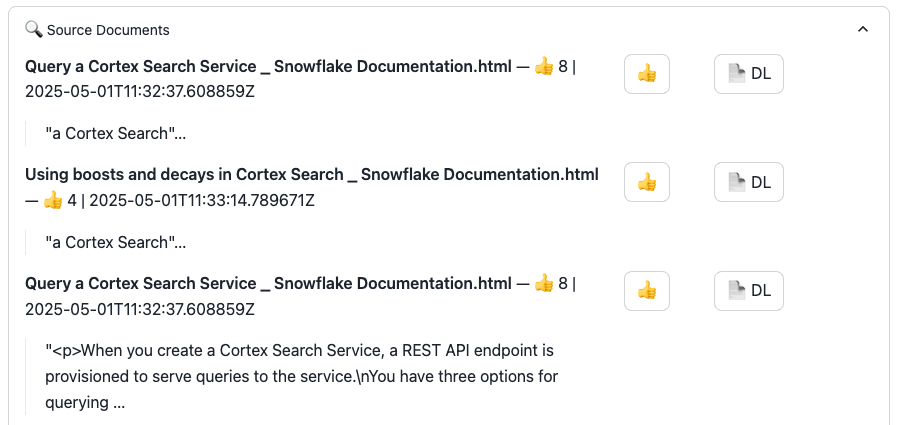
Search results with likes counter and download button
Requirements
- Snowflake account with Cortex Search and Cortex LLM access (cross-region inference removes most cloud/region limitations)
-
Python packages:
- Python 3.11+
- snowflake-ml-python ≥ 1.8.1
- snowflake.core ≥ 1.2.1
- pdfplumber ≥ 0.11.4 (for PDF support)
For Cortex Search regional availability, see the official documentation.
Setup Instructions
Create a new Streamlit in Snowflake app
From Snowsight's left panel, click "Streamlit" then "+ Streamlit" to create a new app.Install required packages
Installsnowflake-ml-python,snowflake.core, andpdfplumberin your Streamlit editor.Copy the source code
Paste the this code.
import streamlit as st
import uuid
from datetime import datetime
from snowflake.snowpark.context import get_active_session
from snowflake.cortex import Complete as CompleteText
from snowflake.core import Root
import io
# ------------------------------------------------------------
# Configuration (adjust as needed for your environment)
# ------------------------------------------------------------
STAGE_NAME = ""
TABLE_NAME = ""
SEARCH_SERVICE = ""
WAREHOUSE = ""
MAX_RESULTS = 5 # Number of results to return per search
# ------------------------------------------------------------
# Snowflake session initialization
# ------------------------------------------------------------
st.set_page_config(layout="wide")
session = get_active_session()
root = Root(session)
current_db = session.sql("SELECT CURRENT_DATABASE()").collect()[0][0]
current_schema = session.sql("SELECT CURRENT_SCHEMA()").collect()[0][0]
# ------------------------------------------------------------
# Object initialization helpers
# ------------------------------------------------------------
def init_objects() -> None:
"""Create stage, table and search service if they don't exist."""
session.sql(f"CREATE STAGE IF NOT EXISTS {STAGE_NAME}").collect()
session.sql(
f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
doc_id STRING PRIMARY KEY,
file_name STRING,
content STRING,
likes INT,
created_at TIMESTAMP
)
"""
).collect()
svc_exists = session.sql(
f"SHOW CORTEX SEARCH SERVICES LIKE '{SEARCH_SERVICE}'"
).collect()
if not svc_exists:
create_search_service()
def create_search_service() -> None:
"""(Re)create Cortex Search Service targeting the document table."""
session.sql(
f"""
CREATE OR REPLACE CORTEX SEARCH SERVICE {SEARCH_SERVICE}
ON content
ATTRIBUTES file_name, likes, created_at
WAREHOUSE = {WAREHOUSE}
TARGET_LAG = '1 day'
AS (
SELECT file_name, content, likes, created_at
FROM {TABLE_NAME}
)
"""
).collect()
# ------------------------------------------------------------
# Upload & chunk helper
# ------------------------------------------------------------
def upload_document(uploaded_file, chunk_size: int, overlap: int) -> None:
"""Save the file to stage, split into chunks, and bulk insert into the table."""
stage_path = f"@{STAGE_NAME}/{uploaded_file.name}"
session.file.put_stream(uploaded_file, stage_path, auto_compress=False)
file_ext = uploaded_file.name.split(".")[-1].lower()
uploaded_file.seek(0)
# Extract text depending on file type
if file_ext == "pdf":
try:
import pdfplumber
pdf_bytes = uploaded_file.read()
with pdfplumber.open(io.BytesIO(pdf_bytes)) as pdf:
pages = [p.extract_text() or "" for p in pdf.pages]
content = "\n".join(pages)
except Exception as e:
content = f"[PDF extraction failed]: {e}"
else:
raw = uploaded_file.read()
try:
content = raw.decode("utf-8")
except UnicodeDecodeError:
try:
content = raw.decode("shift_jis")
except Exception:
content = str(raw)
# Chunk with Snowflake SPLIT_TEXT_RECURSIVE_CHARACTER
chunks_rows = session.sql(
"""
SELECT value
FROM LATERAL FLATTEN(
input => SNOWFLAKE.CORTEX.SPLIT_TEXT_RECURSIVE_CHARACTER(?, 'none', ?, ?)
)
""",
params=[content, chunk_size, overlap]
).collect()
ts = datetime.utcnow()
rows_to_insert = [
(str(uuid.uuid4()), uploaded_file.name, r["VALUE"], 0, ts)
for r in chunks_rows
]
if rows_to_insert:
df = session.create_dataframe(
rows_to_insert,
schema=["doc_id", "file_name", "content", "likes", "created_at"],
)
df.write.mode("append").save_as_table(TABLE_NAME)
# ------------------------------------------------------------
# Search & answer helpers
# ------------------------------------------------------------
def search_documents(question: str):
"""Run Cortex Search with boosts & decays and return top documents."""
rag_svc = (
root.databases[current_db]
.schemas[current_schema]
.cortex_search_services[SEARCH_SERVICE]
)
scoring = {
"functions": {
"numeric_boosts": [
{"column": "likes", "weight": 1}
],
"time_decays": [
{"column": "created_at", "weight": 1, "limit_hours": 240}
]
}
}
resp = rag_svc.search(
query=question,
columns=["file_name", "content", "likes", "created_at"],
limit=MAX_RESULTS,
scoring_config=scoring,
)
return resp.results
def generate_answer(question: str, context_blocks, model: str) -> str:
"""Generate answer with COMPLETE function using retrieved context."""
context = "\n---\n".join(
[f"[likes: {d['likes']}, date: {d['created_at']}]\n{d['content']}" for d in context_blocks]
)
prompt = f"""
You are an assistant that answers user questions based on uploaded documents.
Use the context below to provide a concise answer in English.
If the context is insufficient, say so.
### Context
{context}
### Question
{question}
### Answer
"""
return CompleteText(model, prompt)
# ------------------------------------------------------------
# Streamlit UI
# ------------------------------------------------------------
def main():
st.title("📖 Simple RAG App – Cortex Search Boosts & Decays")
# Sidebar – upload & settings
st.sidebar.header("🗂️ Upload Documents")
st.sidebar.markdown("### 🔧 Chunk Settings")
chunk_size = st.sidebar.number_input("Chunk size (chars)", 100, 2000, 300, 50)
overlap_size = st.sidebar.number_input("Overlap (chars)", 0, 500, 30, 10)
st.sidebar.markdown("### 📂 File Upload")
uploaded_file = st.sidebar.file_uploader(
"Supported: txt, md, csv, json, log, html, xml, yaml, yml, pdf",
type=[
"txt", "md", "csv", "json", "log", "html", "xml", "yaml", "yml", "pdf",
],
)
if st.sidebar.button("Save to Stage & Table") and uploaded_file is not None:
upload_document(uploaded_file, chunk_size, overlap_size)
st.sidebar.success("Upload completed! Document saved to stage & table.")
if st.sidebar.button("Rebuild Cortex Search Service"):
create_search_service()
st.sidebar.success("Cortex Search Service rebuilt.")
st.sidebar.header("⚙️ Model")
model_name = st.sidebar.selectbox(
"Choose LLM model",
(
"claude-3-5-sonnet",
"mistral-large2",
"llama3.3-70b",
"reka-flash",
),
)
# Initialize chat history
if "messages" not in st.session_state:
st.session_state["messages"] = []
# Fragment for rendering documents
@st.fragment
def render_docs(docs):
with st.expander("🔍 Source Documents", expanded=True):
for idx, d in enumerate(docs):
title = d.get("file_name", "(no title)")
meta = f"👍 {d['likes']} | {d['created_at']}"
preview = d["content"][:150].replace("\n", " ") + "…"
col1, col2, col3 = st.columns([7, 1, 2])
with col1:
st.markdown(f"**{title}** — {meta}\n\n> {preview}")
# Like button
def _like(file_name=d["file_name"]):
session.sql(
f"UPDATE {TABLE_NAME} SET likes = likes + 1 WHERE file_name = ?",
params=[file_name],
).collect()
col2.button("👍", key=f"like_{idx}_{title}", on_click=_like)
# Download original file
stage_path = f"@{STAGE_NAME}/{d['file_name']}"
try:
stream = session.file.get_stream(stage_path)
file_bytes = stream.read()
except Exception:
rows = session.sql(
f"SELECT content FROM {TABLE_NAME} WHERE file_name = ? ORDER BY created_at",
params=[d["file_name"],],
).collect()
file_bytes = "\n".join([r["CONTENT"] for r in rows]).encode("utf-8")
ext = d["file_name"].split(".")[-1].lower()
mime_map = {
"txt": "text/plain",
"md": "text/markdown",
"csv": "text/csv",
"json": "application/json",
"log": "text/plain",
"html": "text/html",
"xml": "application/xml",
"yaml": "text/yaml",
"yml": "text/yaml",
"pdf": "application/pdf",
}
mime_type = mime_map.get(ext, "application/octet-stream")
col3.download_button(
label="📄 DL",
data=file_bytes,
file_name=d["file_name"],
mime=mime_type,
key=f"dl_{idx}_{title}",
)
# Render past messages
for m in st.session_state["messages"]:
with st.chat_message(m["role"]):
st.markdown(m["content"])
if "docs" in m:
render_docs(m["docs"])
if st.sidebar.button("Clear Chat History"):
st.session_state["messages"] = []
st.rerun()
if question := st.chat_input("Ask a question"):
st.session_state["messages"].append({"role": "user", "content": question})
with st.chat_message("user"):
st.markdown(question)
docs = search_documents(question)
answer = generate_answer(question, docs, model_name)
with st.chat_message("assistant"):
st.markdown(answer)
render_docs(docs)
st.session_state["messages"].append({"role": "assistant", "content": answer, "docs": docs})
# ------------------------------------------------------------
# Entry point
# ------------------------------------------------------------
if __name__ == "__main__":
init_objects()
main()- Configure app parameters Modify lines 12-16 to match your environment:
STAGE_NAME = ""
TABLE_NAME = ""
SEARCH_SERVICE = ""
WAREHOUSE = ""
MAX_RESULTS = 5 # Number of results to return per search- Run the app Execute the app and start uploading documents.
Conclusion
Boosts & Decays is a powerful yet simple way to enhance search quality in RAG applications. By incorporating user feedback and temporal information, you can continuously improve search results with minimal effort.
While this demo uses a simple single-file app, in production you could:
- Create document workflows that update likes/status
- Set up CI/CD pipelines to rebuild the Cortex Search Service
- Add query filters to segment search by department/category
- Combine with weighted vector search for even more personalized results
I hope you'll try Boosts & Decays to enhance your organization's search experience!
Promotion
Snowflake What's New Updates on X
I'm sharing updates on Snowflake's What's New on X. I'd be happy if you could follow:
English Version
Snowflake What's New Bot (English Version)
Japanese Version
Snowflake's What's New Bot (Japanese Version)
Change Log
(20250501) Initial post
