Trunk-based development has been gaining traction as one of the most effective strategies for continuous integration and rapid delivery, especially in big teams. For our team, I don't want to make changes only in the Git branching model — I want to reshape our development culture to support fast feedback, economy resources, and resilience. This is the story of how I researched adding a monorepo tool and cache for my team and what I learned along the way.
Step 1: Understanding the Why
Before proposing to my team to move to trunk-based development, I spent time understanding its core benefits: reduced merge conflicts, efficient CI/CD flows, faster feedback loops, and less overhead around long-lived branches.
Step 2: Audit Our Current Workflow
I reviewed our existing practices, which include multiple long-lived branches, complex merge processes, and weekly releases with release trains. Such practices often result in spending a lot of resources manually merging tasks in waterfall style, manually deploying services, and regressions on the release candidate stage and production environment. Also, such approaches have frequent conflicts and context-switching headaches. Considering that we are moving towards trunk-based development, it is clear that we need a leaner, more collaborative workflow.
Step 3: Introducing the Concept to the Team
Change is hard, and selling a new approach requires empathy. We discussed potential profit, and I researched how much we can optimize in our npm scripts on CI. I considered the most popular solutions, NX and Turborepo.
Step 4: Tooling Up with Nx
We already have a small Lerna setup (now it belongs to NX, and some commands from Lerna just run NX 😀), so I started looking for pros and cons in NX.
Pros
- Powerful caching mechanisms
- Has a smooth migration from Lerna to NX
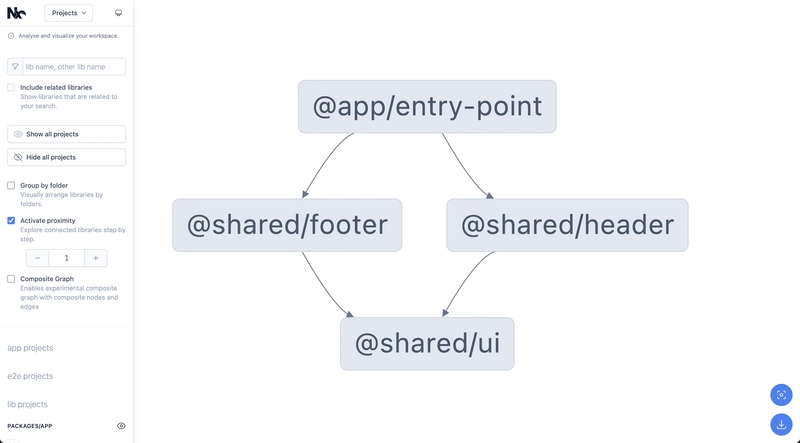
- Has an interactive dep-graph
- Supports a Single version policy
- Has an incremental functionality for the scripts via affected
- They are in progress in moving to Rust
Cons
- Internal vendor libraries for bundling the app: e.g. webpack. You may encounter some locks or their restrictions, also, I don't think it is a good time for us to couple a monorepo tool and a building system.
- Can't cache the result of the scripts in watch mode
- Precedent of an attempt to make a remote cache paid by disabling custom task runners. It ended up with a rollback, but precedent is precedent.
Step 5: Tooling Up with Turborepo
Pros
- Powerful caching mechanisms
- Has an incremental functionality for the scripts via affected
- Remote cache is free, and custom task runners are available
- It is already on Rust
- Time-saved feature and telemetry
- Pretty easy to add to your repo without special internal libs for bundling your code
Cons
- Non-interactive deps graph, it will be adopted to PlantUML, and you can use its built-in features to visualize the graph, but without interactivity
- Supports a "Single version policy" but you need to declare a dependency with asterisks, like:
"dependencies": {
"react": "*"
}My result of pet project
Firstly, I tried using NX, and everything was pretty fine until I tried using Turborepo for the same project.
Adding the Turborepo was much easier. Also, when I decided to switch my pet project from webpack to rspack, it took 15-30 minutes. In the end, when I heard about NX's plans to block custom task runners, I decided to use Turborepo for all my stuff and use NX with the simplest configuration only for parsing deps and running an interactive deps graph. The config is really simple for it:
{
"$schema": "node_modules/nx/schemas/nx-schema.json",
"pluginsConfig": {
"@nrwl/js": {
"analyzeSourceFiles": true
}
},
"defaultProject": "@app/entry-point"
}Run in your console:
nx graph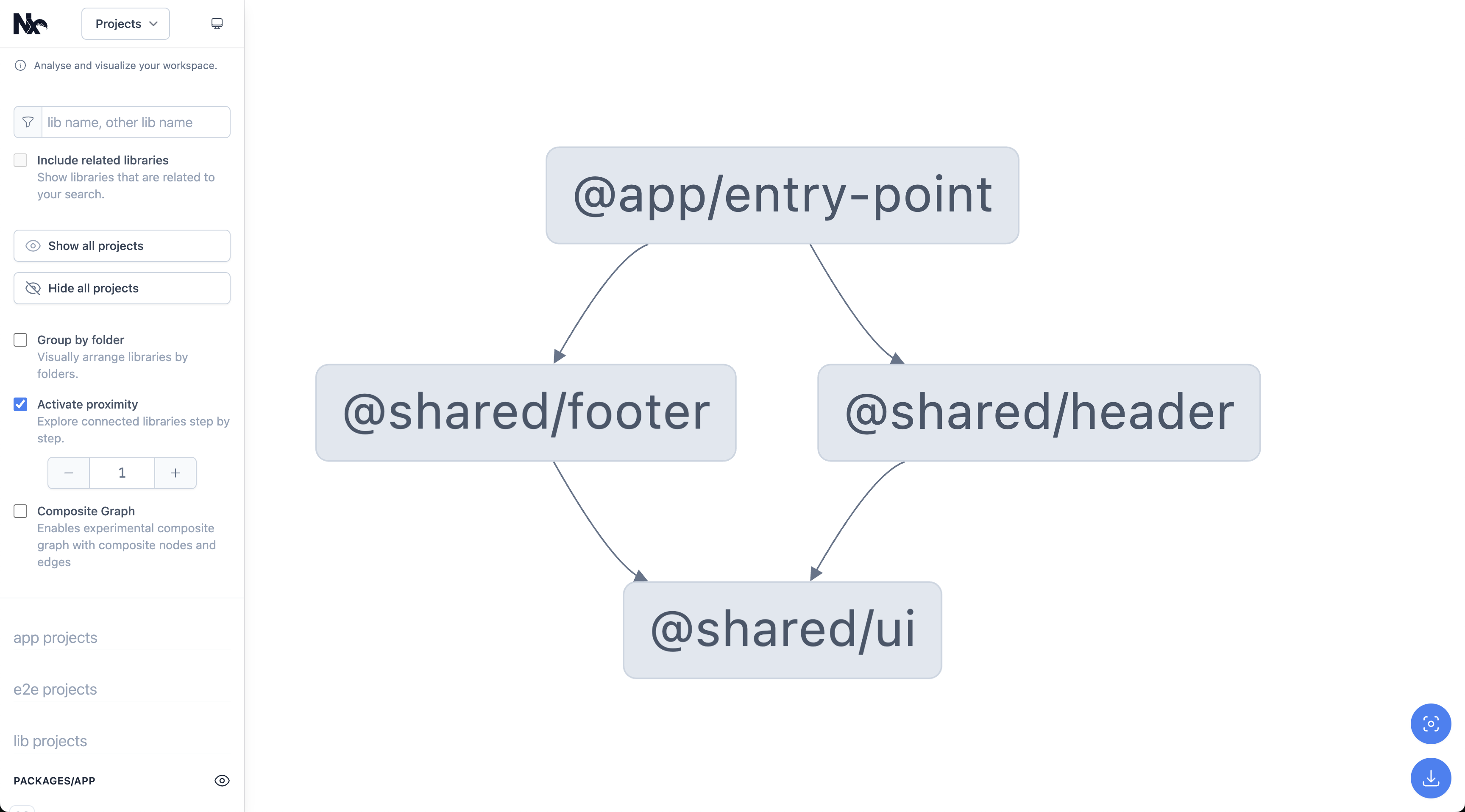
Ultimately, I got Turborepo without cons for my setup. Pretty simple config at the beginning:
{
"tasks": {
"build": {
"dependsOn": ["^build"],
"inputs": ["$TURBO_DEFAULT$", ".env*"],
"outputs": ["./dist/**"]
},
"test": {
"cache": true,
"inputs": ["$TURBO_DEFAULT$"]
},
"lint": {
"dependsOn": ["^lint"]
},
"check-types": {
"dependsOn": ["^check-types"]
},
}
}And I like that, the tool for my monorepo is not responsible for my tech stack, and it would be worse if it was responsible for bundling my frameworks or libraries that I use. On the opposite side, NX does it.
Eventually, I set up scripts: lint, check-types, and test
lint
Root level:
...
"lint": "turbo run lint",
...Package level:
"lint": "eslint ."With a flat ESLint config, it will find and use the root file eslint.config.mjs.
check-types
Root level:
...
"check-types": "turbo run check-types",
...Package level:
"check-types": "yarn tsc --noEmit",Here is a simple strategy for tsc to check types.
test
Root level:
...
"test": "export WORKSPACE_ROOT=$(git rev-parse --show-toplevel) && turbo run test -- --config $WORKSPACE_ROOT/jest.config.ts",
...Package level:
"test": "jest --rootDir .",Setup is a bit tricky, I run a test script in each package (and use the package as a root dir) and pass down a root config via --config option of jest. Everything works fine except changes in the root jest.config.ts don't trigger turborepo's reset cache. I tried to add the jest.config.ts in inputs, but paths in "inputs" work at the package level. This means Turborepo is looking for jest.config.ts in each package's directory, not at the root. And each package has its nesting. If you know how to add the jest root file in "inputs" to trigger re-run test script in each package after changes in the jest config, pls leave a comment.
Reflections and What’s Next
Switching to trunk-based development won't be without friction, but the payoff will be worth it, I guess. And to simplify the migration process, I want to split it into a few steps.
This is just the beginning, and I’m excited to keep evolving how we build software together.
Literature and Further Reading
- Trunk-based development
- Nx Documentation: Monorepos Made Easy
- Turborepo Documentation
- Martin Fowler on Branching Strategies
- Feature Toggles (Fowler)
Bonus:
Split incremental builds into packages
It might be suitable for you. Split bundling by each package:
- Realize the bundling flow for each package (I experimented with tsc and added
"start-build": "yarn tsc") - In
turbo.json:
"start-build": {
"dependsOn": ["^start-build"]
},- Before
yarn startI ranyarn turbo watch start-build --affected
And I got cacheable results in watch mode for any desirable package 🎉. It's not so suitable for my case, for me it was easier to move to rspack with good compatibility with webpack. I used rspack's internal optimization, incremental builds - here.
Alternative ways without monorepo tools:
- For incremental CI, you can use tj-actions/changed-files, find only changed files, and run some scripts with arguments of these files
- For lint - use eslint ./files
- For jest - use the flag --findRelatedTests
- For tsc - a bit more difficult