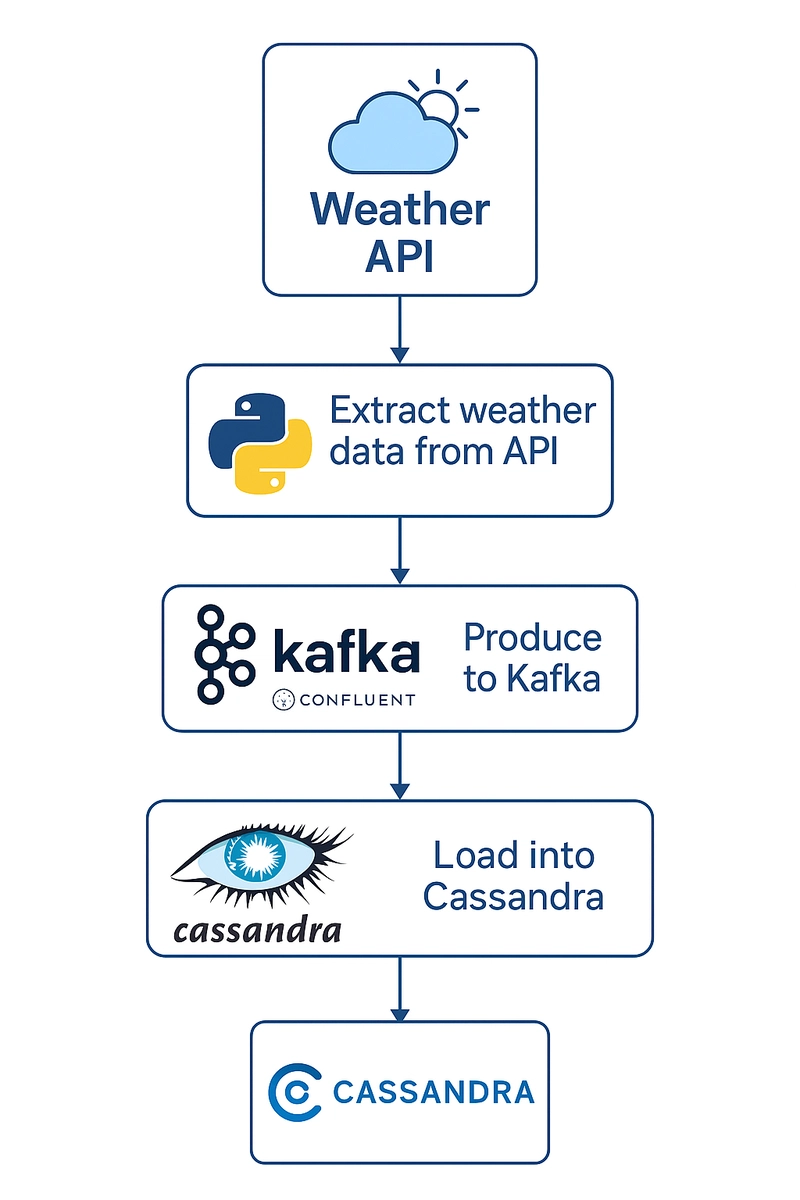
Overview
This project demonstrates a real-time data pipeline that extracts weather data from the OpenWeatherMap API for select cities and streams it into an Apache Cassandra database using Apache Kafka and Confluent Cloud.
Tech Stack
1.Language: Python
2.Streaming Platform: Apache Kafka (via Confluent Cloud)
3.Data Source: OpenWeatherMap API
4.Database: Apache Cassandra
5.Environment Management: dotenv
Step by step
Producer script
I started by setting up the producer, which fetches and produces the data to Kafka.
Step 1: Import Dependencies & Setup Logging
The script begins by importing necessary libraries for HTTP requests, environment management, Kafka production, and logging. Logging is configured to help monitor the process in real-time.
import json
import time
import os
import requests
from confluent_kafka import Producer
from dotenv import load_dotenv
import loggingConfigure logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)Step 2: Load Environment Variables
Environment variables are loaded from a .env file to manage credentials like Kafka API keys and bootstrap servers securely.
load_dotenv()Step 3: City List Initialization
A predefined list of cities is created. These cities will be used to request weather data from the OpenWeatherMap API.
cities = ["Nairobi", "Johannesburg", "Casablanca", "Lagos", "Mombasa"]Step 4: OpenWeatherMap API Call
The fetch_weather_data() function sends a GET request to the OpenWeatherMap API using the city name. It appends the city to the returned data and handles errors gracefully using try-except.
owm_base_url = "https://api.openweathermap.org/data/2.5/weather"
def fetch_weather_data(city):
url = f"{owm_base_url}?q={city}&appid=6b2b158ff5facbe68dd7b2960b68738a&units=metric"
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
data["extracted_city"] = city
return data
except requests.exceptions.RequestException as e:
logger.error(f"Error fetching data for {city}: {e}")
return NoneStep 5: Kafka Producer Configuration
Kafka is configured to connect to Confluent Cloud using SASL_SSL authentication. The configuration parameters are loaded from environment variables to avoid hardcoding sensitive data.
kafka_config = {
'bootstrap.servers': os.getenv('BOOTSTRAP_SERVER'),
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
"sasl.username": os.getenv('KAFKA_API_KEY'),
"sasl.password": os.getenv('KAFKA_API_SECRET'),
"broker.address.family": "v4",
"message.send.max.retries": 5,
"retry.backoff.ms": 500,
}
producer = Producer(kafka_config)
topic = "weather"Step 6: Delivery Report Callback
The delivery_report() function is a callback that confirms whether a Kafka message was successfully delivered or if there was an error. This helps in tracking the delivery status of each message.
def delivery_report(err, msg):
if err is not None:
logger.error(f"Message delivery failed: {err}")
else:
logger.info(f"Message delivered to {msg.topic()} [{msg.partition()}] at offset {msg.offset()}")Step 7: Produce Weather Data Function
The produce_weather_data() function loops through each city, fetches weather data, and produces a message to the Kafka topic named weather. It uses the city as the key and the weather data as the JSON-encoded value.
def produce_weather_data():
for city in cities:
data = fetch_weather_data(city)
if data:
producer.produce(topic, key=city, value=json.dumps(data), callback=delivery_report)
producer.poll(0)
else:
logger.error(f"Failed to fetch data for {city}")
producer.flush()Step 8: Main Execution Block
This is the script’s entry point. It calls the producer function and logs a final message once data has been successfully extracted and sent to Kafka.
if __name__ == "__main__":
produce_weather_data()
logger.info("Data extraction and production complete")Consumer script
This section explains the functionality of the consumer script used to retrieve weather data from a Kafka topic and store it in an Apache Cassandra database.
Step 1: Import Dependencies and Load Environment Variables
Essential modules are imported for Kafka consumption, JSON parsing, UUID generation, and Cassandra integration. Environment variables are loaded to manage sensitive configurations securely.
import os
from dotenv import load_dotenv
from confluent_kafka import Consumer, KafkaException
from cassandra.cluster import Cluster
from json import loads
from datetime import datetime
import uuid
load_dotenv()Step 2: Kafka Consumer Configuration
A Kafka consumer is created using configuration variables from .env. The script connects securely to Confluent Cloud using SASL_SSL.
conf = {
'bootstrap.servers': os.getenv('BOOTSTRAP_SERVER'),
'security.protocol': 'SASL_SSL',
'sasl.mechanisms': 'PLAIN',
'sasl.username': os.getenv('KAFKA_API_KEY'),
'sasl.password': os.getenv('KAFKA_API_SECRET'),
'group.id': 'weather-group-id',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(conf)
topic = 'weather'
consumer.subscribe([topic])
print(f"✅ Subscribed to topic: {topic}")Step 3: Cassandra Setup
The script connects to a local Cassandra cluster and prepares a keyspace and table. If they don’t exist, they are created.
cluster = Cluster(['127.0.0.1'])
session = cluster.connect()
session.execute("""
CREATE KEYSPACE IF NOT EXISTS weather
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
""")
session.set_keyspace("weather_data")
session.execute("""
CREATE TABLE IF NOT EXISTS weather_stream (
id UUID PRIMARY KEY,
city_name TEXT,
weather_main TEXT,
weather_description TEXT,
temperature FLOAT,
timestamp TIMESTAMP
)
""")
print("✅ Cassandra table ready")Step 4: Consuming Messages from Kafka
The script enters an infinite loop to poll messages from Kafka. Each message is decoded and parsed into a JSON object. Relevant fields are extracted for storage.
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
raise KafkaException(msg.error())
# Deserialize JSON
data = loads(msg.value().decode('utf-8'))Step 5: Insert Data into Cassandra
Each JSON record is transformed into a dictionary with the necessary fields. A unique UUID and timestamp are used as part of the row data.
record = {
"id": uuid.uuid4(),
"city_name": data.get("extracted_city", "Unknown"),
"weather_main": data["weather"][0]["main"],
"weather_description": data["weather"][0]["description"],
"temperature": data["main"]["temp"],
"timestamp": datetime.fromtimestamp(data["dt"])
}
session.execute("""
INSERT INTO weather_stream (id, city_name, weather_main, weather_description, temperature, timestamp)
VALUES (%(id)s, %(city_name)s, %(weather_main)s, %(weather_description)s, %(temperature)s, %(timestamp)s)
""", record)
print(f"✅ Inserted weather for {record['city_name']} at {record['timestamp']}")Step 6: Graceful Shutdown
The consumer listens for a keyboard interrupt (Ctrl+C) and shuts down gracefully.
except KeyboardInterrupt:
print("🛑 Consumer stopped manually")
finally:
consumer.close()
print("🔒 Kafka consumer closed")Conclusion
This project illustrates the seamless integration of real-time data streaming and storage using Python, Apache Kafka, and Apache Cassandra. By leveraging Confluent Cloud, weather data from multiple cities is efficiently streamed through Kafka and ingested into a resilient NoSQL database. The modular codebase ensures flexibility and scalability, making it easy to adapt or expand for future use cases such as real-time dashboards, analytics, or extended geographic coverage.