ในปัจจุบัน AI และ Machine Learning ได้รับความนิยมอย่างมากในหลายๆ ด้าน ในบทความนี้เราจะพูดถึงเรื่อง Recommendation Systems ซึ่งเป็นระบบแนะนำสิ่งต่างๆ ให้กับผู้ใช้ โดยเราจะใช้ Collaborative Filtering ในการเขียนโค้ดเพื่อแนะนำ และใช้ Cosine Similarity ช่วยในการหาความคล้ายคลึงระหว่างผู้ใช้แต่ละคน
Collaborative Filtering?
Collaborative Filtering คือเทคนิคหนึ่งที่ใช้ในระบบแนะนำต่างๆ เพื่อแนะนำสิ่งที่ผู้ใช้น่าจะชอบ เช่น เพลง หนัง หรือสินค้า โดยอ้างอิงจากพฤติกรรมหรือความชอบของผู้ใช้คนอื่นที่มีความคล้ายกันหลักการของ Collaborative Filtering
ถ้าให้พูดง่ายๆ ก็คือ Collaborative Filtering จะดูว่าผู้ใช้เคยให้คะแนนหรือกดถูกใจอะไรไว้ จากนั้นหาว่าผู้ใช้คนไหนมีความชอบคล้ายกันและจะแนะนำให้ผู้ใช้ ยกตัวอย่างเช่น ผู้ใช้ A กับ B ให้คะแนนหนังคล้ายกัน แสดงว่าความชอบน่าจะคล้ายกันจากนั้นระบบจะแนะนำสิ่งที่ A ยังไม่เคยดู แต่ B ชอบให้กับ A ในทางกลับกันระบบก็จะแนะนำหนังที่ B ไม่เคยดู แต่ A ชอบCollaborative Filtering มีกี่แบบ?
- User-based คือการแนะนำรายการจากผู้ใช้ที่มีความชอบคล้ายกัน ระบบจะดูว่าผู้ใช้คนอื่นที่มีความชอบคล้ายกันกับเรา เช่น ชอบดูหรือฟังอะไรบ้าง แล้วนำมาสร้างเป็นคำแนะนำ
- Item-based คือการแนะนำรายการจากความคล้ายกันของรายการ ระบบจะดูว่ารายการที่เราชอบมีอะไรคล้ายกันบ้าง แล้วแนะนำรายการใหม่ที่คล้ายกันกับสิ่งที่เราเคยชอบ
Cosine Similarity?
Cosine Similarity คือวิธีการวัดความคล้ายกันระหว่างสองสิ่ง เช่น ผู้ใช้สองคนหรือหนังสองเรื่อง โดยดูจากมุมระหว่างเวกเตอร์มากกว่าค่าตัวเลขตรงๆค่าที่ได้อยู่ในช่วงไหน?
โดยค่าที่ได้จะอยู่ในช่วง -1 ถึง 1
- ค่าที่ได้เข้าใกล้ 1 หมายความว่ามีความคล้ายกันมาก
- ค่าที่ได้เข้าใกล้ 0 หมายความว่าไม่ค่อยมีความคล้ายกัน
- ค่าที่ได้เข้าใกล้ -1 หมายความว่าไม่มีความคล้ายกัน แต่ในกรณีการให้คะแนนหนังหรือเพลงมักจะไม่ได้ค่าติดลบ เพราะเราไม่ให้คะแนนเป็นลบ
เมื่อเรารู้แล้วว่าแต่ละอย่างมีความหมายอย่างไรและมีหลักการแบบไหน เราลองมาดูกันว่าจะใช้งานยังไงใน Recommendation system
ขั้นตอนที่ 1 ติดตั้งไลบรารี
เราจะติดตั้งไลบรารี Python เพื่อนำมาใช้ในงานเรา
pip install pandas scikit-learnขั้นตอนที่ 2 import ไลบรารีที่จำเป็น
ในขั้นตอนนี้เราจะ import ไลบรารีต่างๆที่จะใช้
- pandas เอามาจัดการข้อมูล
- cosine_similarity เอามาใช้คำนวณความคล้ายกันระหว่างเวกเตอร์
- CountVectorizer เอาไว้ใช้ใน Content-Based
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizerขั้นตอนที่ 3 สร้างข้อมูลตัวอย่าง
เราจะสร้างข้อมูล โดยมีชื่อของ User ชื่อรายการ Item และคะแนนที่ผู้ใช้แต่คนให้กับ Item
data = {
'User': ['Alice', 'Bob', 'Charlie', 'David'],
'Item1': [5, 4, 1, 0],
'Item2': [4, 5, 2, 0],
'Item3': [1, 0, 5, 4],
'Item4': [0, 0, 4, 5],
}ขั้นตอนที่ 4 แปลงข้อมูลเป็น DataFrame
- pd.DataFrame แปลงข้อมูลที่เป็น Dictionary ให้กลายเป็น DataFrame ซึ่งเป็นตารางข้อมูลแบบที่ Pandas ใช้
- df.set_index ใช้ตั้งคอลัมน์ 'User' ให้เป็นชื่อแถวแทนเลข 0, 1, 2, 3
- แสดงผลตารางออกมา
df = pd.DataFrame(data)
df.set_index('User', inplace=True)
print("User-Item Matrix:\n", df)ขั้นตอนที่ 5 คำนวณค่า Cosine Similarity
- cosine_similarity() คือฟังก์ชันที่ใช้คำนวณค่าความคล้ายกันระหว่างเวกเตอร์ และการเติมค่า 0 แทนช่องว่างจากโค้ด df.fillna(0)
- นำผลลัพธ์ที่ได้จากการคำนวณมาสร้าง DataFrame เหมือนขั้นตอนที่ 3
- แสดงตารางที่คำนวณแล้วออกมา
similarity_matrix = cosine_similarity(df.fillna(0))
similarity_df = pd.DataFrame(similarity_matrix, index=df.index, columns=df.index)
print("\nUser Similarity Matrix:\n", similarity_df)จะได้ผลลัพธ์
จากโค้ดทั้งหมดจะได้ผลลัพธ์ตามข้างล่าง โดยตารางแรกจะเป็นตารางที่แสดงข้อมูลต่างๆทั้ง ชื่อ ไอเทม และคะแนนเพื่อเอาไปคำนวณค่าความคล้ายต่อไป ตารางที่ 2 จะเป็นตารางที่แสดงค่าที่คำนวณออกมาแล้วโดยเราจะนำตารางที่ 2 ไปใช้ในการแนะนำของระบบ
User-Item Matrix:
Item1 Item2 Item3 Item4
User
Alice 5 4 1 0
Bob 4 5 0 0
Charlie 1 2 5 4
David 0 0 4 5
User Similarity Matrix:
User Alice Bob Charlie David
User
Alice 1.000000 0.963925 0.409514 0.096393
Bob 0.963925 1.000000 0.322372 0.000000
Charlie 0.409514 0.322372 1.000000 0.921063
David 0.096393 0.000000 0.921063 1.000000ตัวอย่างเพิ่มเติม
เราลองมาทำแนะนำเพลง
ขั้นตอนที่ 1
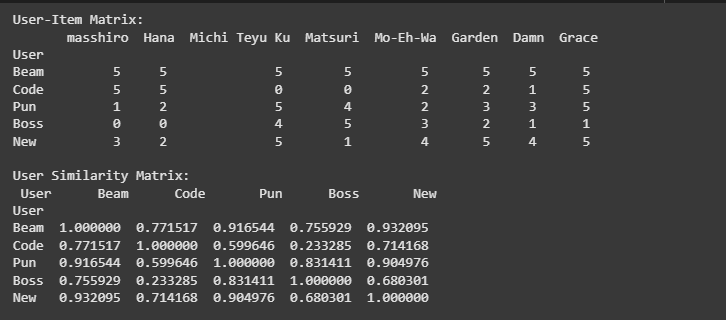
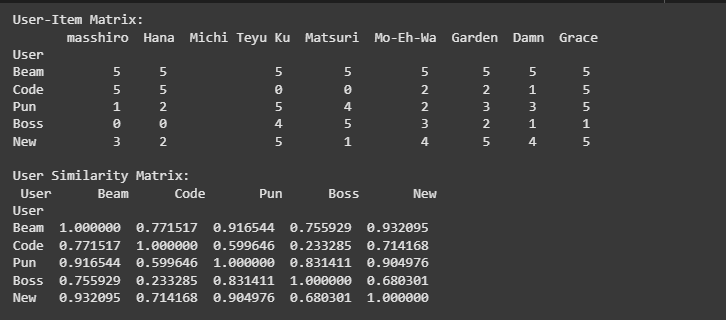
เราจะสร้างข้อมูล โดยมีชื่อของ User ชื่อรายการเพลง และคะแนนที่ผู้ใช้แต่คนให้กดให้กับแต่ละเพลง เช่น Beam ให้ 5 กับเพลง masshiro
data = {
'User': ['Beam', 'Code', 'Pun', 'Boss', 'New'],
'masshiro': [5, 5, 1, 0, 3],
'Hana': [5, 5, 2, 0, 2],
'Michi Teyu Ku': [5, 0, 5, 4, 5],
'Matsuri': [5, 0, 4, 5, 1],
'Mo-Eh-Wa': [5, 2, 2, 3, 4],
'Garden': [5, 2, 3, 2, 5],
'Damn': [5, 1, 3, 1, 4],
'Grace': [5, 5, 5, 1, 5],
}ขั้นตอนที่ 2
เราจะแปลงข้อมูลเป็น DataFrame และนำไปคำนวณค่าความคล้ายกันเหมือนกับตัวอย่างแรก
df = pd.DataFrame(data)
df.set_index('User', inplace=True)
print("User-Item Matrix:\n", df)
similarity_matrix = cosine_similarity(df.fillna(0))
similarity_df = pd.DataFrame(similarity_matrix, index=df.index, columns=df.index)
print("\nUser Similarity Matrix:\n", similarity_df)จะได้ผลลัพธ์
ขั้นตอนที่ 3
เราจะสร้างฟังก์ชัน recommend_music(user) เพื่อแนะนำเพลงให้กับผู้ใช้ โดยดูจากความคล้ายกันระหว่างผู้ใช้ต่างๆ โดยใช้ข้อมูลจาก 2 ตารางที่ได้คำนวณไว้ในขั้นตอนก่อนหน้า
def recommend_music(user):
similar_users = similarity_df[user].sort_values(ascending=False)
print(f"\nผู้ใช้ที่คล้ายกับ {user} คือ:")
for user_name in similar_users.index[1:4]:
print(user_name)
recommendations = {}
for other_user in similar_users.index[1:4]:
for music, rating in df.loc[other_user].items():
if rating > 0 and music not in df.loc[user].index[df.loc[user] > 0]:
if music not in recommendations:
recommendations[music] = rating
else:
recommendations[music] += rating
print(f"\nเพลงที่แนะนำให้ {user}:")
sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
for music, score in sorted_recommendations:
print(music)ขั้นตอนที่ 4 ทดสอบ
ขั้นตอนนี้เราจะมาลองทดสอบฟังก์ชั่นแนะนำเพลง โดยเราจะแนะนำเพลงให้กับ Boss กัน
recommend_music("Boss")จะได้ผลลัพธ์
ผลลัพธ์ที่ได้จะบอกว่า Boss มีความชอบในการฟังเพลงคล้ายใครบ้าง และระบบจะแนะนำเพลงที่ Boss ไม่เคยฟังโดยดูจากPun, Beam, New
ผู้ใช้ที่คล้ายกับ Boss คือ:
Pun
Beam
New
เพลงที่แนะนำให้ Boss:
masshiro
Hanaสรุปเนื้อหา
เราได้พูดถึงการสร้าง Recommendation System โดยใช้เทคนิค Collaborative Filtering และ Cosine Similarity ซึ่งเริ่มต้นจากการสร้างข้อมูลตัวอย่างและคำนวณความคล้ายคลึงระหว่างผู้ใช้ เพื่อแนะนำสิ่งที่ผู้ใช้น่าจะชอบ แม้ว่าในบทความนี้จะใช้ตัวอย่างเล็กๆ แต่ก็ช่วยให้เห็นภาพของกระบวนการทำงานและหลักการเบื้องต้นของระบบแนะนำ ที่สามารถนำไปประยุกต์ใช้ในระบบที่ซับซ้อนมากขึ้นได้ หากต้องการพัฒนาระบบแนะนำที่มีความซับซ้อนมากขึ้น หรืออยากปรับปรุงให้ดีขึ้น สามารถศึกษาหลักการและเครื่องมือเพิ่มเติมได้ เพื่อสร้างระบบที่มีความแม่นยำและตอบโจทย์ผู้ใช้มากยิ่งขึ้น
References
- https://medium.com/@data-overload/collaborative-filtering-4e14aa8b43a8
- https://dev.to/info_generalhazedawn_a3d/implementing-a-recommendation-system-using-collaborative-filtering-content-based-algorithms-in-4pcp
- https://dev.to/mage_ai/how-does-spotify-use-machine-learning-4pdg
- https://tupleblog.github.io/spotify/