Refact.ai Agent, powered by Claude 3.7 Sonnet, has achieved top performance on the Aider Polyglot Benchmark:
- 92.9% without Thinking
- 93.3% with Thinking.
This 20-point lead over the highest listed score (72.9% by Aider with Gemini 2.5 Pro) showcases Refact.ai’s superior autonomous coding capabilities. It handles programming tasks end-to-end in IDE — planning, execution, testing, refinement — and delivers a highly accurate result with zero human intervention.
📖 Explore the full article on our blog
Aider’s Polyglot benchmark evaluates how well AI models handle 225 of the hardest coding exercises from Exercism across C++, Go, Java, JavaScript, Python, and Rust. Unlike SWE-Bench, which focuses solely on Python and single-file edits within 12 repos, Polyglot tests AI ability to write and integrate new code across diverse, multi-language projects, making it much closer to real-world developer workflows.
Our approach: How Refact.ai achieved #1 in the polyglot leaderboard
Refact.ai Agent takes a fully autonomous, iterative approach. It plans, executes, tests, self-corrects, and repeats steps as needed to fully complete tasks with high accuracy — without human input.
Other approaches may follow a more manual, structured workflow, where some steps are controlled by human input + pre-defined scripts. Aider’s benchmark setup looks similar to this, following the trajectory:
Prompt → User provides task description → User manually collects and adds files to the context → Model attempts to solve the task → Then retries, controlled by the number of —tries parameter → User runs tests manually and, if they fail, provides feedback to the model → Model does corrections → Result.
This workflow requires ongoing user involvement — manually providing context, running tests, and guiding the AI. The model itself doesn’t form a strategy, search for files, or decide when to test. Of course, this approach saves tokens, but it also lacks autonomy.
Refact.ai has a different, autonomy-first AI workflow:
Prompt + tool-specific prompts → User provides task description → AI Agent autonomously solves it within 30 steps (i.e. searches for the relevant data, calls tools, decides when corrections are needed, runs tests, etc.) → Result.
So, Refact.ai interacts with the development environment, verifies its own work, and optimizes resources to fully solve the task end-to-end, delivering efficient and practical programming flow with full-scope autonomy.
This is much closer to real-world software development and vibe coding: developers can delegate entire tasks to AI Agent while doing other work, then simply receive the final result. It enables teams to get 2x more done in parallel, get the best out of AI models, and focus on big things instead of basic coding.
Key aspects of Refact.ai Agent approach:
1️⃣ 100% autonomy at each step
We at Refact.ai focus on making our AI Agent as autonomous, reliable, and trustworthy as possible. To complete tasks, it follows a structured prompt — since Refact.ai is open-source, you can explore our AI Agent prompt on GitHub. Below is an excerpt:
PROMPT_AGENTIC_TOOLS: |
You are Refact Agent, an autonomous bot for coding tasks.
STRATEGY
Step 1: Gather Existing Knowledge
Goal: Get information about the project and previous similar tasks.
Always call the knowledge() tool to get initial information about the project and the task.
This tool gives you access to memories, and external data, example trajectories (🗃️) to help understand and solve the task.
Step 2: Gather Context
Goal: Fully understand the task by gathering all important details.
Do the following:
Use tree() to check the project structure.
Use locate() with the task description to find all necessary files automatically.
Use additional tools like search(), regex_search(), cat(), definition(), and references() and any other to collect relevant information.
Check any files that might indirectly relate to the task.
Running available validation tools preliminary - is a good idea.
Step 3: Make a Clear Plan
Goal: Create a clear, validated plan before making changes.
After gathering context (Step 2), create your plan independently.
Only call deep_think() if:
The task is very complex,
You face complicated issues or loops,
The user specifically asks for it.
When using deep_think(), clearly state the task, what the outcome should look like, and carefully check the plan.
After planning, use create_knowledge() to save important ideas, decisions, and strategies.
Step 4: Make Changes Step-by-Step
Goal: Follow the validated plan carefully.
Make changes step-by-step using *_textdoc() tools.
Clearly comment each step and its results.
After making changes, go to the assessment step.
Step 5: Check and Improve Your Work
Goal: Make sure your changes are correct, complete, and really working.
After changes:
Run available build validation tools (cmdline_cargo_check(), cmdline_pytest*(), cmdline_npm_test(), etc…).
If you find any issues, go back to Step 4 and fix them.
If you cannot solve an issue even after multiple attempts, go back to Step 3 and use deep_think().
Do not pay attention to skipped tests, they don’t indicate any problems
In short: The AI analyzes files → creates a task plan → executes it → tests results → refines the solution — all without human intervention. It independently decides what to check, fix, and retry. You don’t need to force this manually or copy-paste anything.
2️⃣ Deep environment interaction
The model fully integrates with the development environment. It can autonomously read files, call tools, modify code, run tests, and more as needed, whenever needed.
3️⃣ Capped at 30 steps
AI Agent has 30 messages to complete a task. Here, a “message” doesn’t mean human input — AI only needs one: the task description. A message refers to each AI action, such as modifying a file, listing directories, or running tests.
This cap ensures efficiency while avoiding unlimited retries or token inflation. AI Agent decides when and how to use these messages, leading to clear, controlled solutions.
4️⃣ Self-testing with a possibility to check previous steps
Tests are essential for autonomous AI to validate correctness and ensure the final output is reliable.
Refact.ai Agent can run tests multiple times. It doesn’t just test the final output — it can go back to earlier steps, correct mistakes, and retry. If test failures reveal deeper issues, the model may decide to revise previous actions and then create and test a new solution. Plus, the model sometimes runs tests even before trying to write a solution to gather a better preliminary context.
Our approach may slightly differ from what Aider used for solving this benchmark, as our AI agent strategy and vision focus on:
- Full autonomy of AI agent at every step, with no need for human input
- Deep integration with tools and dev environment, enabling Agent to act independently
- Self-testing autonomously when needed, revising earlier steps, testing mid-process, and running multiple checks for accuracy
- Task completion within 30 steps
Refact.ai Agent improvements & benchmark progress
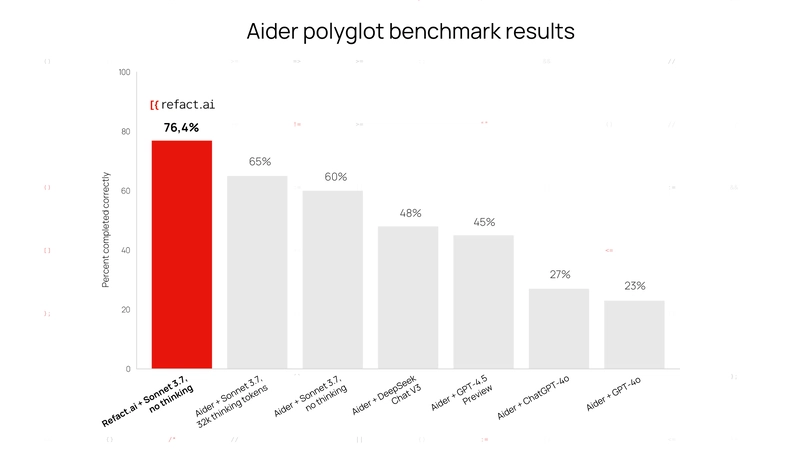
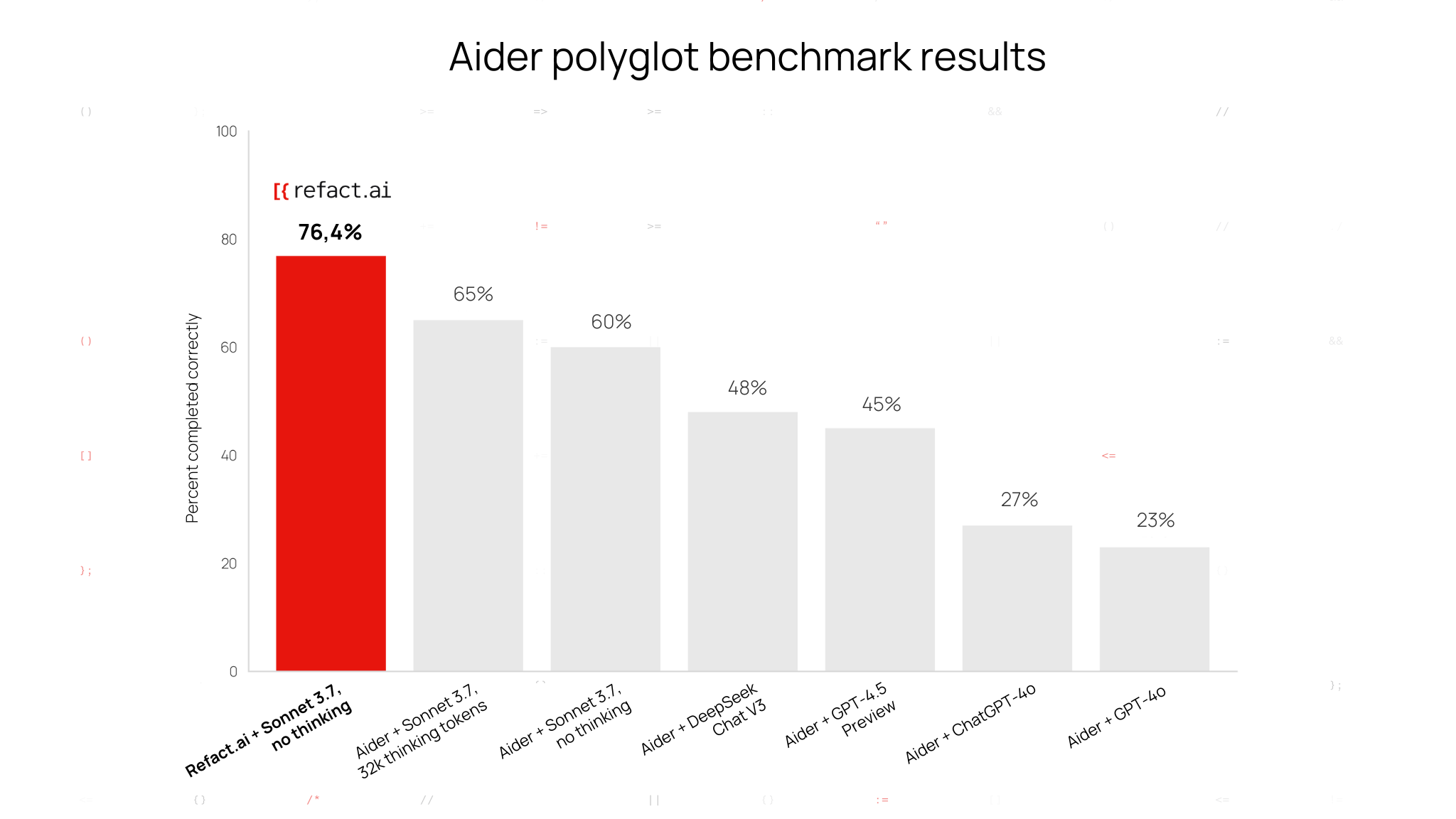
Two weeks ago, we published that Refact.ai had achieved 76.4% on Polyglot with Claude 3.7 Sonnet No-Thinking, already outperforming other listed results. However, the benchmark run revealed areas for improvement: in some cases, AI lacked enough steps to finish tasks, or skipped testing. Now, we introduced general improvements to Refact.ai Agent:
Doubled limit for AI to solve the task from 15 → 30 to allow more complex solutions to fully complete.
Enforced test execution, ensuring AI validates itself at least once per task.
These enhancements made Refact.ai Agent more effective for all users — also boosting the score from 76.4% to 92.9%, and reaching 93.3% score with Thinking.
Thinking vs. No-Thinking mode: What’s the difference?
“I think, therefore I am.” — René Descartes said. For AI, thinking isn’t philosophical, but practical. It refers to a state where models allocate additional computational resources for deeper reasoning.
Completing the Polyglot benchmark, Claude 3.7 Sonnet with Thinking received +4K extra tokens per response to use reasoning when requested. A quick recap of the results:
- 92.9% without Thinking
- 93.3% with Thinking — but it also consumed nearly twice as many tokens to complete the benchmark.
💡 For production use, we recommend enabling Thinking when working on longer, multi-step problems requiring deeper analysis, or handling high-risk code changes where additional reasoning helps avoid errors. You can try it with Refact.ai Agent.
Full breakdown, approach reveal & AI Agent insights we've shared on our blog: Refact.ai Agent scores highest on Aider's Polyglot Benchmark: 93.3% with Thinking Mode, 92.9% without.
Happy to discuss!
Get Refact.ai Agent for IDE | More links: GitHub, LinkedIn, X, Discord.
