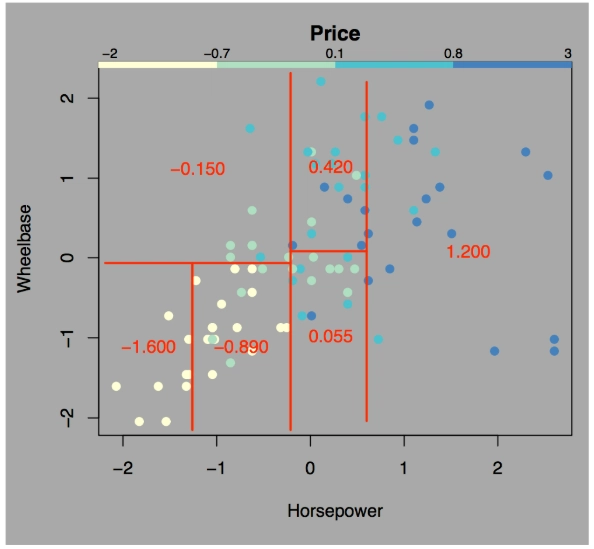
CART stands for Classification And Regression Trees. The algorithm builds binary trees, where every split results in two branches. The algorithm recursively splits the data meaning that the dataset is split along the features continuously until a certain threshold is met. The threshold could be that the max depth has been reached, no further improvement after splitting and a few samples in the leaf node.
With regression, CART algorithms split features with an aim to reduce the Mean Squared Error. After the threshold has been met, the leaf node assigns the mean value of the subset of data. The leaf node represents a cell of the partitions. The cell is the smallest unit where a sample regression can be fit to the data accurately. A simple regression model is fitted to a specific subset of data.
Unlike a regression model where values are being assigned to an equation to obtain a prediction, CART regression works differently in that it assigns the mean of that subset of data.
For instance, if we were using a CART regression to predict the BMI of an individual who is 1.65 meters tall and weighs 80kg, the model will assign the mean of the subset of individuals in that position. Say the model had split along individuals weighing >75kg and measuring >1.60m , and the mean of the subset was a BMI of 29.4, an individual with the measurements 76kg and 180cm might still have a BMI of 29.4 assigned to them.
CART regression algorithms have advantages such as being better suited with non-linear relationships as they fit to specific subsets of data. They are also not dependent on feature scaling as they split leaf nodes on their values and do not rely on scale. They are also better to use with missing data as they use the features that are present based on the majority and they handle overfitting better than regression models using techniques such as pruning.
All in all, CART algorithms simplify the prediction process and are less complex owing to the fact that they use mean values rather than running a regression on every value. They tend to predict better owing to the fact that the tree uses multiple regression models fitted on multiple recursive subsets.