This is a Plain English Papers summary of a research paper called RL Boosts Scene Graph Generation: Accurate Visual Understanding with Language Models. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Enhancing Scene Graph Generation with Reinforcement Learning
Scene graphs provide a structured visual representation that captures objects and their relationships in images. They've become essential for applications like robot manipulation, navigation, and medical image analysis. Traditional approaches to scene graph generation (SGG) typically separate the task into object detection and relationship recognition, optimizing each by maximizing the likelihood of ground-truth labels given an image.
This approach has significant limitations. Models tend to overfit the distribution of annotated datasets, struggling with long-tail distributions and often generating biased scene graphs where all relationships default to head classes like "on" or "of."
Multimodal Large Language Models (M-LLMs) show promise for generating scene graphs in an end-to-end manner by processing visual information alongside natural language prompts. However, these models face challenges with instruction following, repeated responses, and inaccurate spatial localization.
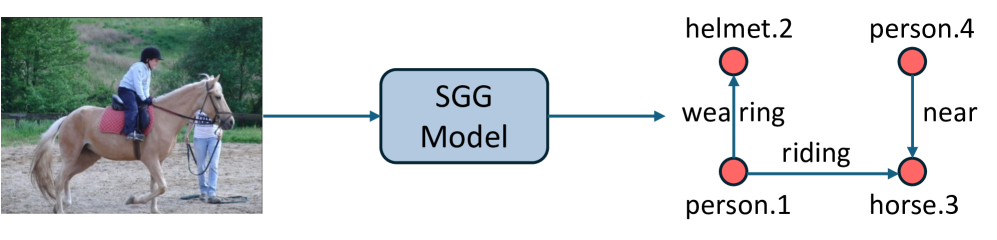
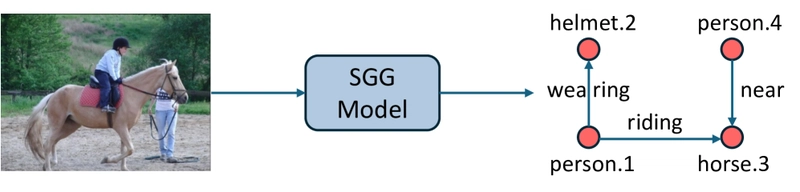
Comparison of traditional Scene Graph Generation (SGG), multimodal LLMs (M-LLMs) with supervised fine-tuning (SFT), and M-LLMs with reinforcement learning (RL) for SGG.
To address these challenges, researchers introduce R1-SGG, a novel framework that leverages visual instruction tuning enhanced by reinforcement learning. The approach first applies supervised fine-tuning (SFT) on scene graph datasets, then refines the model using reinforcement learning with specially designed reward functions that evaluate node-level correspondence, edge-level relationships, and format consistency.
This combination dramatically improves the model's ability to generate accurate and well-structured scene graphs compared to both traditional methods and standard supervised fine-tuning.
Prior Approaches to Scene Graph Generation
Traditional SGG models like those proposed by Xu et al. (2017), Zellers et al. (2018), and Chen et al. (2019) decouple the task into object detection and relationship classification stages. While effective, these approaches are limited by their reliance on annotated data and exhibit strong bias toward head predicates such as "on" or "of," struggling with long-tail classes.
To overcome closed-set limitations, recent work has explored open-vocabulary SGG. For example, OvSGTR (Chen et al., 2024) extends scene graph prediction to a fully open-vocabulary setting by leveraging visual-concept alignment. In parallel, weakly supervised methods have been developed to reduce the annotation burden, using image-caption pairs as supervision to distill relational knowledge.
With the rise of LLMs, several studies have attempted to synthesize scene graphs from natural language. LLM4SGG extracts relational triplets from both original and paraphrased captions using text-only LLMs. GPT4SGG goes further by using GPT-4 to generate scene graphs from dense region captions, improving contextual consistency and coverage. From Pixels to Graphs leverages vision-language models to produce scene graphs through image-to-text generation pipelines.
However, these caption-based or LLM-driven methods often exhibit limited accuracy, including incomplete object sets and inconsistent relationship descriptions. These issues arise from the lack of structure in the generated outputs and the absence of mechanisms to refine the results according to scene-level constraints.
Reinforcement learning (RL) has been increasingly adopted to enhance the reasoning capabilities of large models but remains underutilized for generating structured outputs in multimodal learning.
The R1-SGG Framework: Combining Supervised Learning with Reinforcement Learning
Scene graph generation (SGG) transforms an image I into a structured representation that captures both objects and their interactions. Specifically, SGG produces a directed graph G = (V, E), where each node represents an object annotated with a category and bounding box. Each relationship triplet captures the relationship between two nodes, such as spatial relations (e.g., "on") or interactive relations (e.g., "riding").
The R1-SGG framework introduces a novel approach that combines supervised fine-tuning with reinforcement learning to enhance M-LLMs for effective scene graph generation.
For reinforcement learning, R1-SGG adopts Group Relative Policy Optimization (GRPO), an online reinforcement learning algorithm. Unlike traditional methods such as PPO, which require an explicit critic network, GRPO compares groups of candidates to update the policy. This approach is particularly suitable for scene graph generation, where evaluating the quality of a generated graph requires comparing it against structured ground truth.
To establish correspondence between predicted and ground-truth nodes, R1-SGG employs bipartite matching, similar to the approach used in DETR. The cost objective for this matching incorporates object category similarity and spatial overlap:
cost(vi, vj) = λ1·(1.0-⟨Embedding(ci), Embedding(cj)⟩)
+ λ2·(1.0-IoU(bi, bj)) + λ3·‖bi-bj‖1where ⟨·,·⟩ denotes cosine similarity, λ1, λ2 are weight factors, and Embedding is obtained via the NLP tool SpaCy. By solving this bipartite matching problem, R1-SGG establishes a one-to-one node matching between the predicted graph and the ground-truth graph, enabling the computation of appropriate rewards.
The reward functions in R1-SGG operate at multiple levels:
Format Reward: Ensures the model's response adheres to the expected structure, with special attention to the presence of both "objects" and "relationships" keywords.
Node-level Reward: For each predicted node, calculates a reward based on object category similarity and bounding box IoU with its matched ground-truth node.
Edge-level Reward: Evaluates relationship triplets based on the similarity of subject, object, and predicate embeddings.
This multi-level reward system provides comprehensive guidance to the model, addressing both the structural and semantic aspects of scene graph generation. The approach is particularly effective for structured scene understanding, where relationships between objects are as important as the objects themselves.
Experimental Evaluation of R1-SGG
Dataset, Evaluation Metrics, and Implementation Details
The experiments utilize the widely-used VG150 dataset, which consists of 150 object categories and 50 relationship categories. The training set contains 56,224 image-graph pairs, while the validation set includes 5,000 pairs. Following standard evaluation practice in SGG, the SGDET protocol measures the model's ability to generate scene graphs.
For implementation, the code is based on the trl library and utilizes vLLM to speed up sampling during reinforcement learning. For supervised fine-tuning (SFT), the model is trained for 3 epochs using 4x NVIDIA A100 GPUs. For reinforcement learning, the 2B model is trained for 1 epoch using 16x NVIDIA A100 GPUs, and the 7B model is trained for 1 epoch using 16x NVIDIA GH200 GPUs.
Analyzing Current M-LLMs' Visual Relationship Reasoning Capabilities
Before evaluating scene graph generation, the researchers assess how well current multimodal LLMs reason about visual relationships using a four-to-one Visual Question Answering (VQA) task on the VG150 validation set.
| InstructBLIP 7B | LLaVA v1.5 7B | LLaVA v1.6 7B | Qwen2VL 7B | |||||
|---|---|---|---|---|---|---|---|---|
| Acc | mAcc | Acc | mAcc | Acc | mAcc | Acc | mAcc | |
| org. img. | 2.26 | 1.94 | 45.75 | 45.61 | 28.69 | 29.17 | 53.74 | 53.35 |
| mask img. | 1.00 (1.26) | 1.04 (0.96) | 21.80 (23.95) | 21.61 (24.00) | 3.85 (24.44) | 3.95 (25.22) | 0.03 (33.71) | 0.02 (53.33) |
| mask obj. | 1.89 (0.37) | 1.86 (0.08) | 37.15 (8.60) | 37.16 (6.45) | 12.79 (15.90) | 13.22 (15.95) | 16.23 (37.51) | 16.82 (36.53) |
| wo cats. | 2.50 (0.24) | 2.38 (0.44) | 32.83 (12.92) | 32.68 (12.93) | 9.46 (19.23) | 10.11 (19.06) | 16.78 (36.96) | 18.00 (35.29) |
| + mask img. | 0.97 (1.29) | 1.00 (0.94) | 15.41 (10.34) | 15.25 (10.36) | 0.01 (28.48) | 0.01 (29.16) | 0.18 (53.56) | 0.22 (53.13) |
| + mask obj. | 1.75 (0.51) | 1.65 (0.29) | 27.91 (17.84) | 28.37 (17.24) | 3.26 (23.41) | 3.77 (23.40) | 4.67 (49.07) | 5.52 (47.83) |
| wo box. | 26.01 (123.73) | 25.93 (23.99) | 61.93 (116.18) | 61.32 (115.71) | 53.46 (124.77) | 52.10 (122.93) | 78.13 (124.39) | 77.10 (123.75) |
| + mask img. | 10.14 (17.00) | 10.19 (18.25) | 36.26 (9.49) | 35.23 (10.38) | 11.47 (17.22) | 11.44 (17.75) | 0.01 (33.73) | 0.00 (53.35) |
| + mask obj. | 19.26 (17.00) | 19.08 (17.14) | 54.23 (18.48) | 53.84 (18.23) | 33.46 (14.77) | 33.23 (14.06) | 40.26 (15.48) | 39.26 (14.09) |
Table 2: Comparison of VQA on the VG150 validation set across various models and settings. Gains compared to the Original Image (1st row) are indicated in red. "mask img." refers to masking the entire image with random noise, "mask obj." refers to masking object regions with black pixels, "wo cats." refers to not providing object categories in the prompt, and "wo box." refers to not providing bounding boxes in the prompt.
The results reveal that many multimodal LLMs struggle with visual relationship reasoning. The task exhibits a noticeable text bias, and the presence of bounding boxes can sometimes mislead the model's attention. As this is a simpler task compared to SGG, the poor performance suggests that directly applying multimodal LLMs to SGG may yield suboptimal results.
Results: RL Dramatically Improves Scene Graph Generation
The performance of various models on the VG150 validation set demonstrates the significant impact of reinforcement learning:
| Method | Params | Failure Rate (\%) | AP50 | R@20 | R@50 |
|---|---|---|---|---|---|
| w.o. predefined classes or predicates | |||||
| baseline | 7B | 47.26 | 6.75 | 0.84 | 0.84 |
| zero-RL | 7B | $0.08(-47.18)$ | $13.97(+7.22)$ | $13.11(+12.27)$ | $13.11(+12.27)$ |
| SFT | 7B | 40.16 | 13.66 | 9.15 | 9.15 |
| SFT+RL | 7B | $0.04(-40.12)$ | $17.52(+3.86)$ | $20.16(+11.01)$ | $20.18(+11.03)$ |
| baseline | 2B | 69.68 | 1.75 | 0.09 | 0.09 |
| zero-RL | 2B | $0.06(-69.62)$ | $6.19(+4.46)$ | $4.34(+4.25)$ | $4.34(+4.25)$ |
| SFT | 2B | 75.56 | 7.23 | 4.80 | 4.80 |
| SFT+RL | 2B | $0.12(-75.44)$ | $16.58(+9.35)$ | $18.70(13.90)$ | $18.70(13.90)$ |
| w. predefined classes & predicates | |||||
| baseline | 7B | 55.32 | 6.03 | 0.76 | 0.76 |
| zero-RL | 7B | $0.08(-55.24)$ | $11.63(+5.60)$ | $10.67(+9.91)$ | $10.67(+9.91)$ |
| SFT | 7B | 38.50 | 14.58 | 9.92 | 9.96 |
| SFT+RL | 7B | $0.10(-38.40)$ | $18.72(+4.14)$ | $20.40(+10.48)$ | $20.47(+10.51)$ |
| baseline | 2B | 56.56 | 2.31 | 0.17 | 0.17 |
| zero-RL | 2B | $0.08(-56.48)$ | $8.03(+5.72)$ | $6.13(+5.96)$ | $6.13(+5.96)$ |
| SFT | 2B | 73.80 | 7.81 | 5.13 | 5.13 |
| SFT+RL | 2B | $0.28(-73.52)$ | $17.20(+9.39)$ | $18.82(+13.69)$ | $18.87(+13.74)$ |
Table 3: SGDET Performance of Qwen2VL-7B/2B-Instruct models on the VG150 validation set.
The results demonstrate that reinforcement learning dramatically reduces the failure rate and enhances both object detection and relationship recognition. In contrast, supervised fine-tuning alone results in a relatively high failure rate and limited performance improvements.
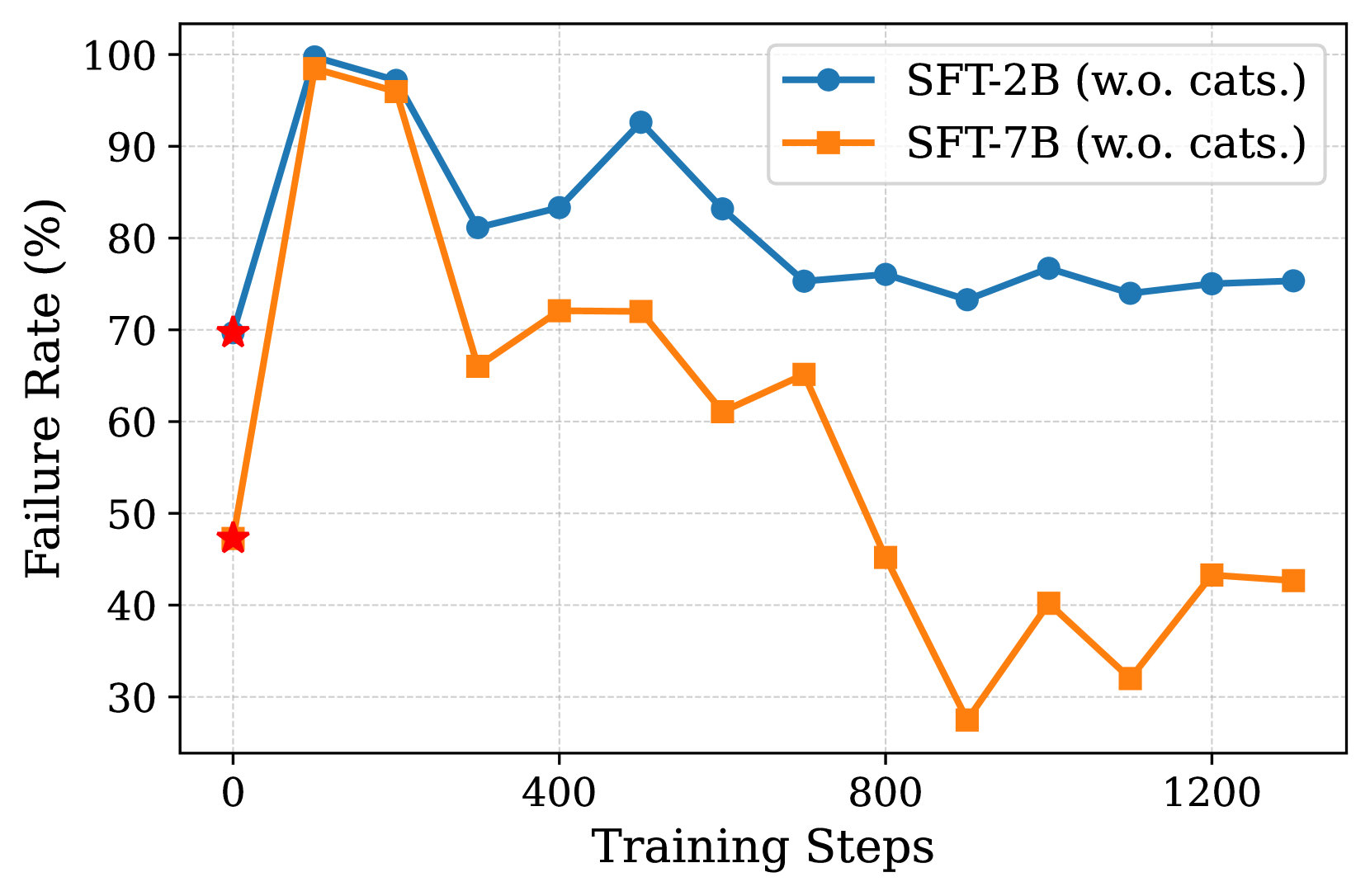
a) Failure Rate vs Training Steps
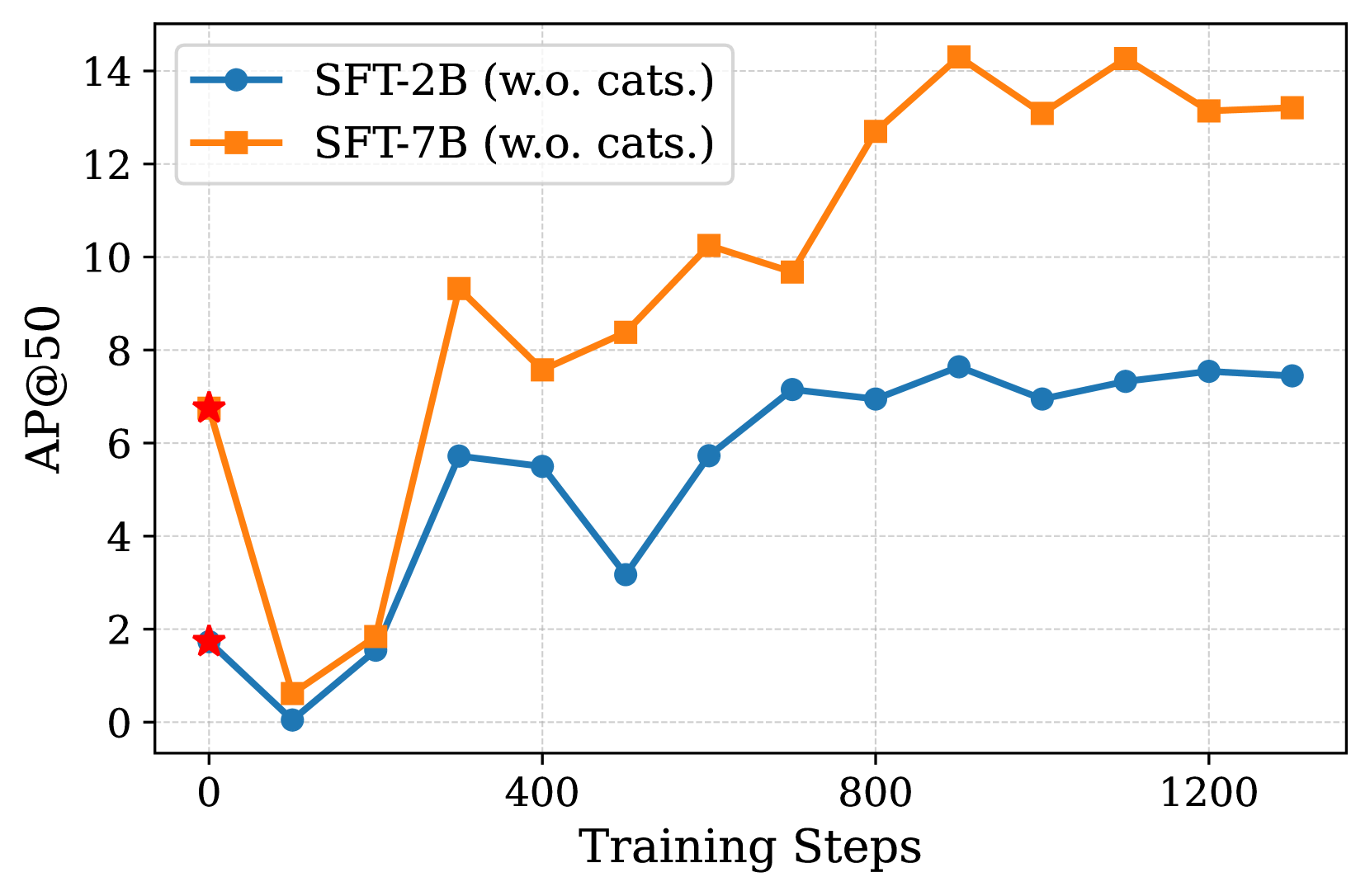
b) AP@50 vs Training Steps
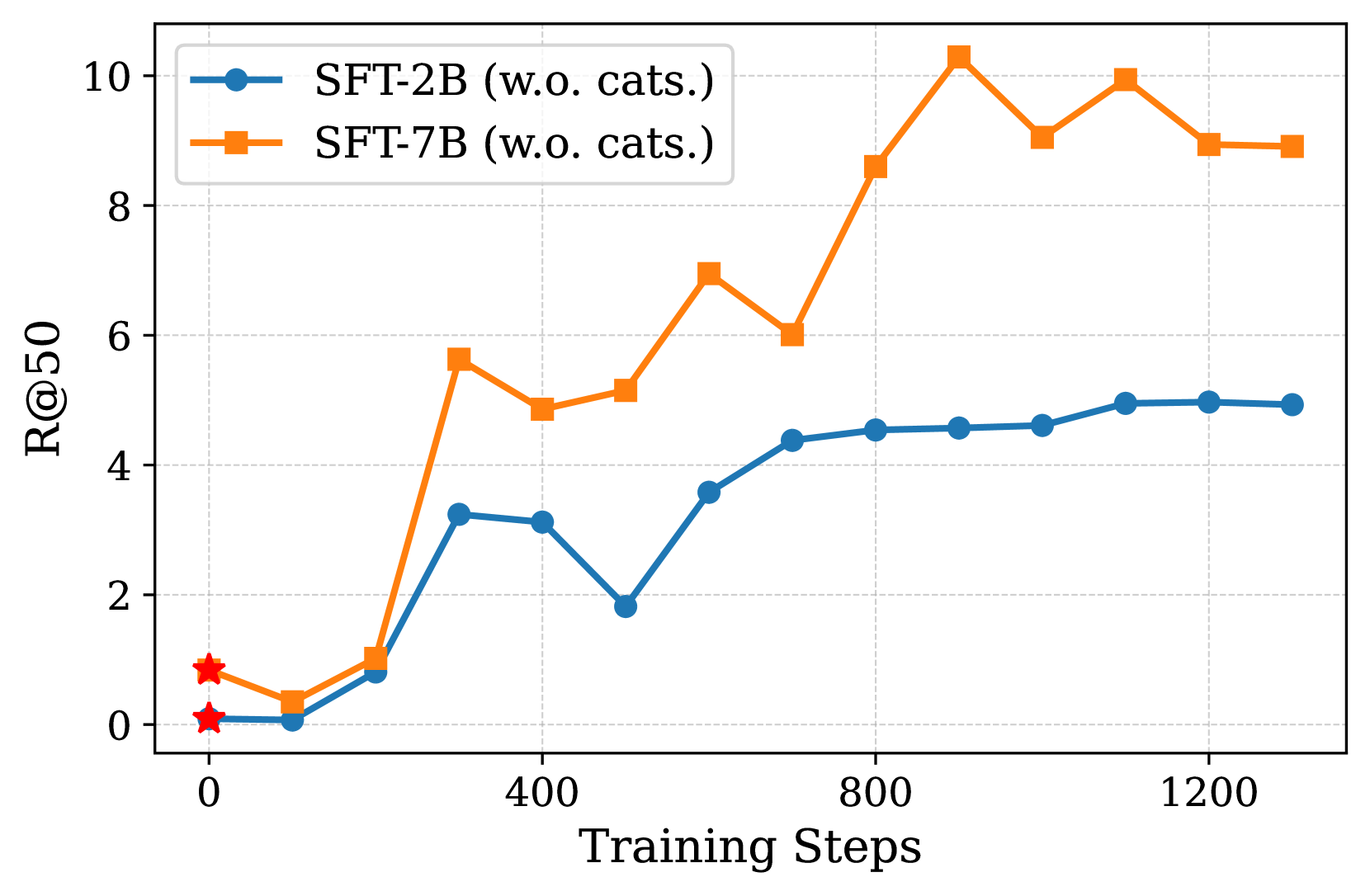
c) R@50 vs Training Steps
As shown in these figures, the failure rate rapidly declines to a very low level when using RL, whereas SFT continues to suffer from a high failure rate. Additionally, the experimental results suggest that predefined object classes or relationship categories are unnecessary, despite their potential to reduce the search space of M-LLMs.
Significance and Future Directions
The R1-SGG approach demonstrates the power of combining supervised fine-tuning with reinforcement learning for scene graph generation. By designing rule-based rewards that operate at the node level, edge level, and format level, the researchers have created a framework that dramatically improves the ability of multimodal LLMs to generate structured visual representations.
The most striking result is the near-elimination of failure cases. Models trained with reinforcement learning achieve a failure rate close to zero, compared to 40-75% for models trained with supervised fine-tuning alone. This indicates that the RL approach successfully addresses the core challenges in generating valid scene graphs.
Another significant finding is that predefined object classes and relationship categories aren't necessary for effective scene graph generation. This suggests that multimodal LLMs have sufficient knowledge to identify objects and relationships without being constrained to a predefined vocabulary.
The open-source framework provided by the researchers will foster further development in using multimodal LLMs for visual reasoning tasks. Future work could extend this approach to other structured visual understanding tasks, such as action recognition in videos or 3D scene understanding.
By demonstrating how reinforcement learning can guide multimodal LLMs to generate structured outputs, this research opens new possibilities for applying large language models to tasks that require precise and organized visual understanding.
