This is a Plain English Papers summary of a research paper called SAVA: Making Italian LLMs Faster & Cheaper via Vocabulary Adaptation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Challenge of Using English-First LLMs in Other Languages
Most large language models (LLMs) are designed primarily for English, making them inefficient for other languages. When these English-centric models process languages like Italian, they suffer from high "token fertility" – the average number of tokens used to encode each word. This leads to slower inference and wasted computational resources.
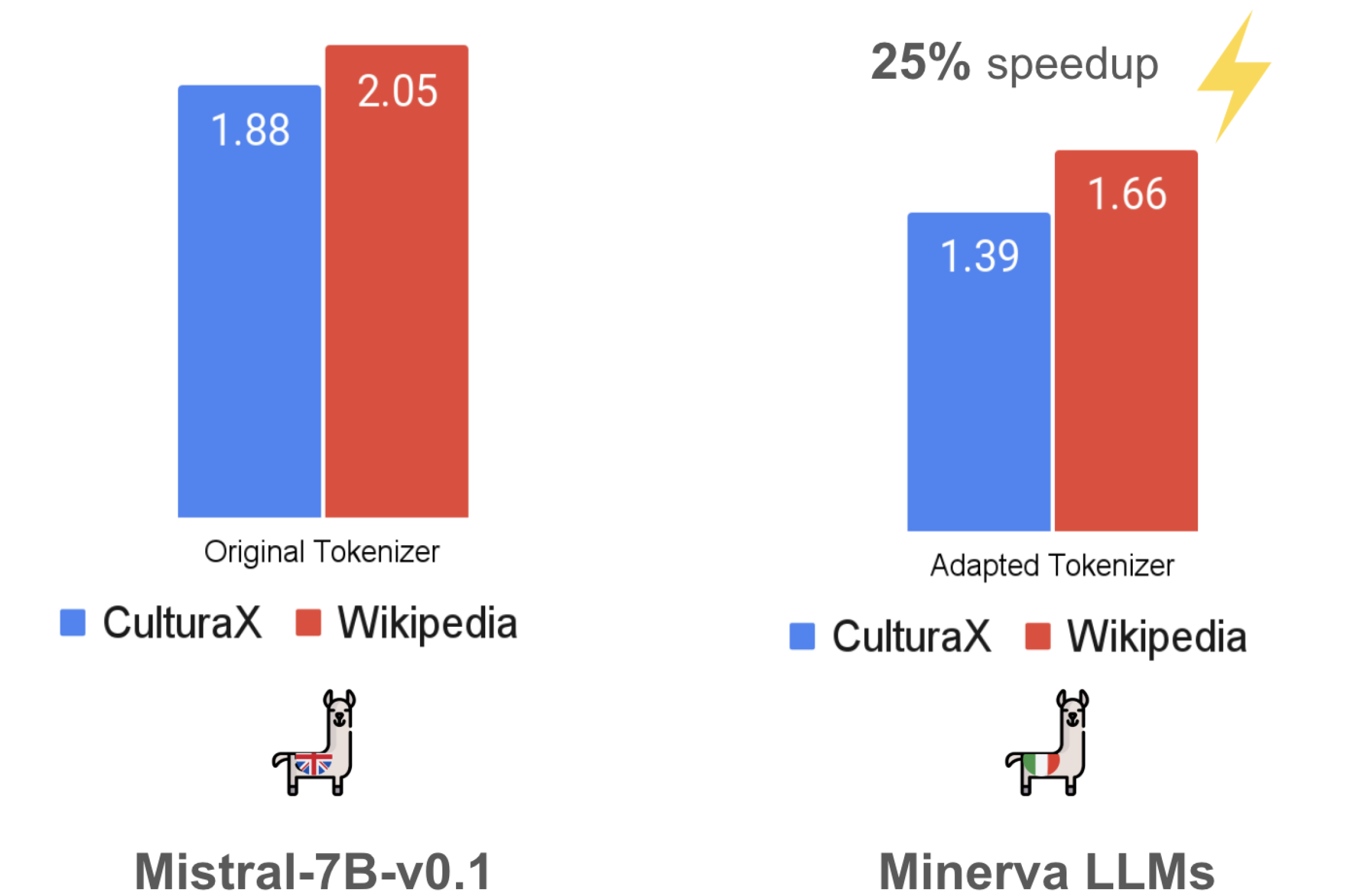
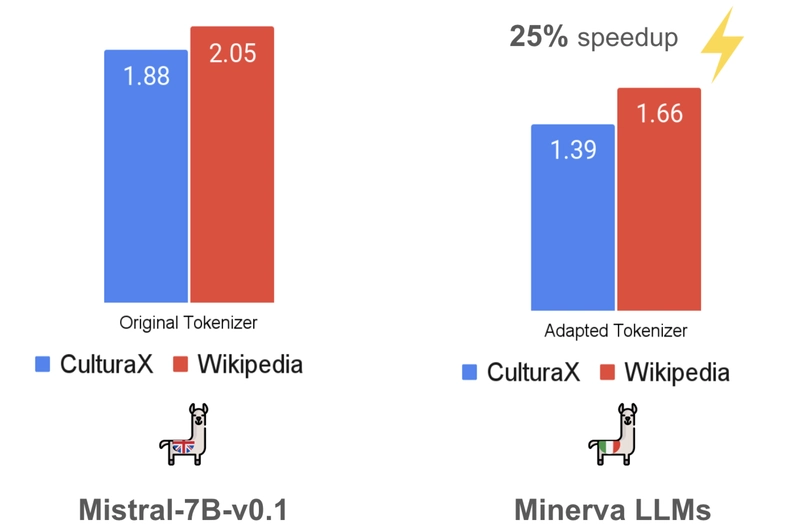
Fertility comparison between Mistral and Minerva tokenizers on Italian texts, showing how purpose-built tokenizers produce fewer tokens per word.
Training new models from scratch for each language requires massive datasets and computational resources. This challenge is particularly acute for languages with limited resources. As demonstrated in Exploring Design Choices for Building Language-Specific LLMs, building language-specific models from the ground up remains impractical for most languages.
Adapting existing English LLMs offers a promising alternative. By modifying an English model's vocabulary and conducting limited additional training, researchers can create more efficient language-specific models without starting from scratch.
Current Approaches to Language Adaptation in LLMs
Two main approaches have emerged for adapting English LLMs to other languages:
Language-Adaptive Pre-Training (LAPT): Continuing to train an existing model on target language data without changing its structure. This method, explored in SambaLingo: Teaching Large Language Models New Languages, improves performance but doesn't address the inefficient tokenization.
Vocabulary Adaptation: Replacing the model's tokenizer and embedding layer with ones better suited for the target language. Research from Empirical Study of Cross-Lingual Vocabulary Adaptation shows this can significantly improve efficiency.
The key difference between various vocabulary adaptation techniques lies in how they initialize the embeddings for new tokens that aren't in the original vocabulary. Some methods use simple averaging, while others leverage helper models or bilingual dictionaries.
The SAVA Method: A New Approach to Vocabulary Adaptation
This research introduces Semantic Alignment Vocabulary Adaptation (SAVA), a novel technique for adapting English LLMs to Italian. SAVA leverages neural mapping to better initialize embeddings for tokens unique to the target language.
In vocabulary adaptation, researchers replace both the tokenizer and embedding matrix of the source model with ones more suitable for the target language. When adapting a model, they keep the original embeddings for tokens shared between source and target vocabularies, but need to initialize new embeddings for tokens unique to the target language.
The mathematical formulation shows how different adaptation techniques apply different functions to initialize these new token embeddings. SAVA specifically uses a helper model (trained on the target language) and learns a linear mapping function between embedding spaces, providing better initialization than previous methods.
After vocabulary adaptation, continued training on target language text helps the model regain capabilities. AdaptiVocab: Enhancing LLM Efficiency in Focused Domains explores similar concepts for domain-specific adaptation, but SAVA focuses specifically on cross-language transfer.
Setting Up the Italian LLM Adaptation Experiment
The researchers adapted two popular English LLMs to Italian: Mistral-7B-v0.1 and Llama-3.1-8B. They used the Minerva-LLMs tokenizer, which was specifically designed for Italian.
| Model | Num. Tokens | Num. Parameters |
|---|---|---|
| Mistral-7B-v0.1 | 32000 | 7.24 B |
| Mistral-7B-v0.1 a.w. Minerva | 32768 | 7.25 B |
| LLaMa-3-8B | 128256 | 8.03 B |
| LLaMa-3-8B a.w. Minerva | 32768 | 7.25 B |
Comparisons of model parameter counts and vocabulary size with and without adaptation (a.w. stands for adapted with).
The Minerva tokenizer shares 16,438 tokens with Mistral and 20,358 tokens with Llama-3.1-8B. Most notably, adapting Llama-3.1-8B with the Minerva tokenizer reduced its vocabulary size by 75% and its parameter count by 10%.
The adapted tokenizers significantly reduced token fertility when processing Italian text:
- Mistral's fertility decreased by 25%
- Llama's fertility decreased by 16%
For continued training, the researchers used the CulturaX dataset with a 75% Italian and 25% English mix. They trained the models on approximately 12 billion tokens, using the Leonardo Supercomputer with A100 GPUs.
Evaluating Italian Adaptation Performance Across Multiple Benchmarks
The researchers evaluated their adapted models on both multiple-choice and generative benchmarks translated to Italian. They compared different vocabulary adaptation methods (Random, FVT, CLP, SAVA) against traditional continued training (LAPT).
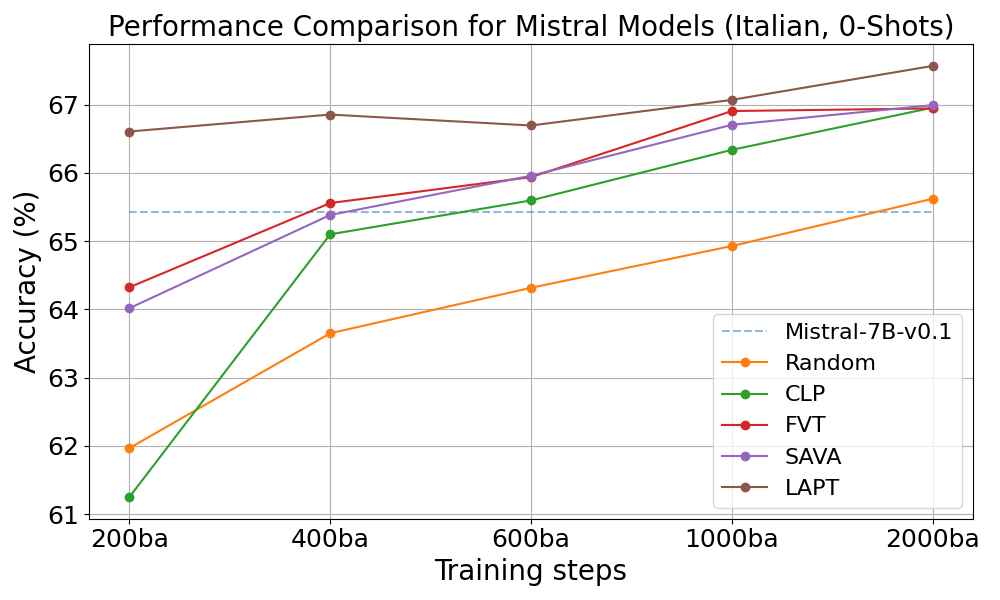
Performance of Mistral-7B-v0.1 models during training on Italian benchmarks, showing how SAVA and FVT converge faster than other methods.
For Mistral-7B-v0.1, the SAVA and FVT methods achieved higher performance early in training. After just 400 batches, these methods matched the performance that the Random approach reached after full training, reducing training time by approximately 80%.
| Model | Hellaswag | MMLU | Arc Easy | PIQA | SCIQ | BOOLQ | AVG |
|---|---|---|---|---|---|---|---|
| Mistral-7B-v0.1 | $56.50_{\pm 0.49}$ | $47.42_{\pm 0.42}$ | $61.67_{\pm 1.01}$ | $67.24_{\pm 1.14}$ | $84.75_{\pm 1.16}$ | $75.01_{\pm 0.75}$ | 65.43 |
| 200 Training Steps | |||||||
| Random | $55.60_{\pm 0.49}$ | $42.48_{\pm 0.42}$ | $57.92_{\pm 1.02}$ | $68.05_{\pm 1.16}$ | $75.46_{\pm 1.39}$ | $72.29_{\pm 0.78}$ | 61.96 |
| FVT | $56.34_{\pm 0.49}$ | $44.28_{\pm 0.42}$ | $60.42_{\pm 1.01}$ | $69.90_{\pm 1.14}$ | $80.48_{\pm 1.28}$ | $74.52_{\pm 0.76}$ | 64.32 |
| CLP | $54.74_{\pm 0.49}$ | $42.50_{\pm 0.42}$ | $57.62_{\pm 1.02}$ | $67.74_{\pm 1.16}$ | $76.82_{\pm 1.36}$ | $68.07_{\pm 0.81}$ | 61.24 |
| SAVA | $56.73_{\pm 0.49}$ | $44.23_{+0.42}$ | $60.90_{+1.01}$ | $69.72_{+1.14}$ | $79.22_{+1.31}$ | $73.30_{+0.77}$ | 64.01 |
| LAPT | $58.29_{\pm 0.49}$ | $49.31_{\pm 0.42}$ | $63.00_{+1.00}$ | $69.84_{\pm 1.14}$ | $84.13_{+1.18}$ | $75.07_{+0.75}$ | 66.60 |
| 2000 Training Steps | |||||||
| Random | $58.43_{\pm 0.49}$ | $46.95_{\pm 0.42}$ | $62.87_{\pm 1.00}$ | $71.39_{+1.12}$ | $81.62_{+1.25}$ | $72.47_{+0.78}$ | 65.62 |
| FVT | $59.00_{\pm 0.49}$ | $47.35_{+0.42}$ | $63.52_{+0.99}$ | $71.51_{+1.12}$ | $84.55_{+1.16}$ | $75.74_{+0.74}$ | 66.94 |
| CLP | $59.21_{+0.49}$ | $47.10_{+0.42}$ | $63.47_{+0.99}$ | $70.77_{+1.13}$ | $84.44_{+1.17}$ | $76.75_{+0.73}$ | 66.95 |
| SAVA | $59.41_{+0.49}$ | $47.57_{+0.42}$ | $63.39_{+0.99}$ | $71.02_{+1.12}$ | $84.55_{+1.16}$ | $76.02_{+0.74}$ | 66.99 |
| LAPT | $60.51_{+0.48}$ | $46.63_{+0.42}$ | $64.99_{+0.99}$ | $71.21_{+1.12}$ | $85.90_{+1.12}$ | $76.17_{+0.74}$ | 67.56 |
Results for Mistral-7B-v0.1 on Italian translated multiple-choice benchmarks.
For Llama-3.1-8B, similar patterns emerged. Both SAVA and FVT performed well, with SAVA showing particular strength on the BOOLQ benchmark, even outperforming the LAPT approach by 4%.
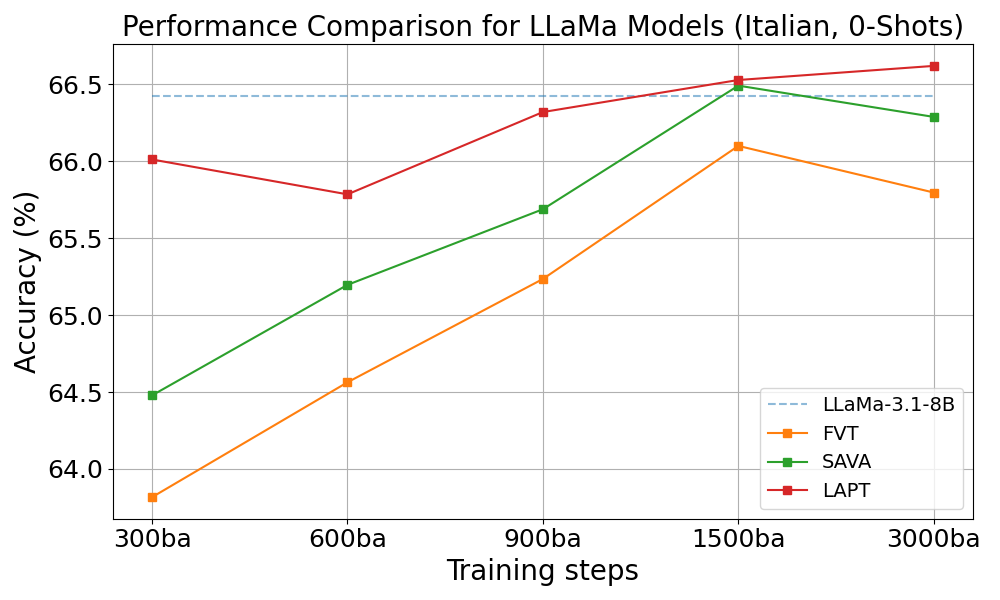
Performance of Llama-3.1-8B models during training on Italian benchmarks, showing consistent improvement through training steps.
The researchers also tested whether the adapted models maintained their English capabilities. Interestingly, SAVA led to slightly better retention of English performance compared to other vocabulary adaptation methods.
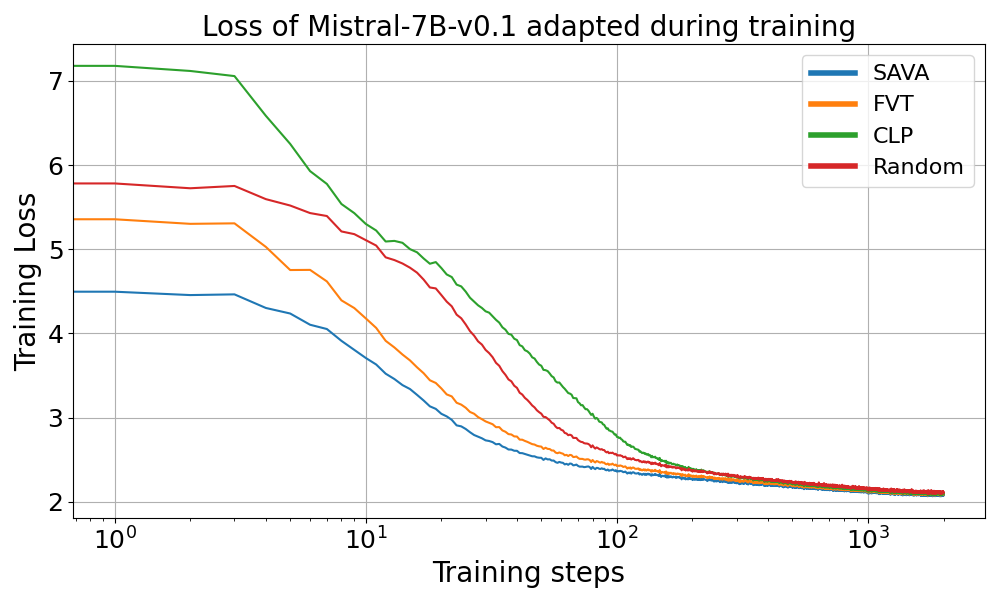
Training loss for Mistral-7B-v0.1 models, showing SAVA's lower loss from the beginning of training.
On generative tasks (machine translation and question answering), SAVA again performed well, particularly in English-to-Italian translation and Italian question answering:
| FLoRes | SQuAD-it | ||
|---|---|---|---|
| Model | EN-IT | IT-EN | RL |
| Mistral-7B-v0.1 | 86.57 | 87.75 | 68.92 |
| 200 Training Steps | |||
| Random | 86.67 | 87.37 | 62.1 |
| FVT | 87.08 | 87.55 | 65.47 |
| CLP | 86.58 | 87.31 | 64.25 |
| SAVA | 87.30 | 87.59 | 65.66 |
| LAPT | 87.41 | 87.92 | 67.35 |
| 2000 Training Steps | |||
| Random | 88.01 | 87.92 | 64.83 |
| FVT | 88.29 | 87.90 | 66.18 |
| CLP | 88.21 | 87.79 | 65.99 |
| SAVA | 88.31 | 87.87 | 67.20 |
| LAPT | 88.13 | 88.02 | 66.92 |
5-shot results for Mistral-7B-v0.1 of FLoRes where COMET-22 is reported and 2-shot results for SQuAD-it where RougeL is reported.
How Different Adaptation Methods Shape Embedding Structures
The researchers analyzed how different vocabulary adaptation techniques affected the structure of the embedding space. They measured similarities between the adapted models and Minerva-3B (the helper model trained specifically for Italian).
| Mistral-7B-v0.1 | Llama-3.1-8B | |||
|---|---|---|---|---|
| Model | @0ba | @2000ba | @0ba | @3000ba |
| Random | 29.68 | 31.67 | - | - |
| FVT | 33.65 | 35.30 | 33.23 | 33.49 |
| CLP | $\underline{41.10}$ | $\underline{42.84}$ | - | - |
| SAVA | $\mathbf{44.81}$ | $\mathbf{45.33}$ | $\mathbf{41.84}$ | $\mathbf{42.02}$ |
Similarity scores between adapted models and Minerva-3B at the beginning and end of training.
SAVA created embeddings most similar to Minerva-3B (+3.7 points higher than CLP), which likely explains its strong performance. Even after extensive training, the different adaptation methods maintained distinct embedding structures, showing that initialization significantly impacts the final model.
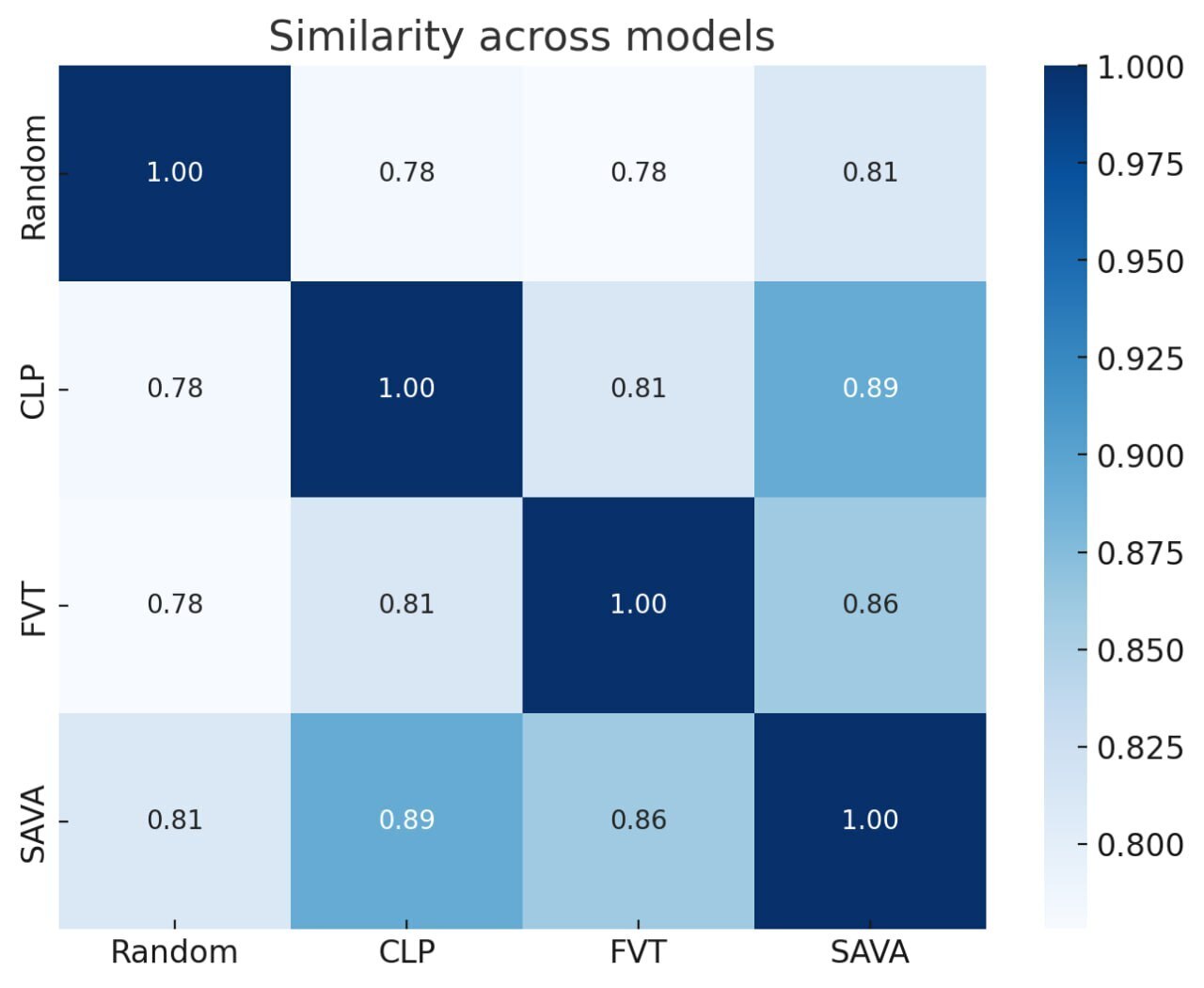
Similarity between different adapted models after training, showing they maintain distinct embedding structures.
Practical Implications for Language-Specific LLM Development
The findings from Optimizing LLMs for Italian have significant implications for adapting LLMs to languages beyond English. The SAVA method proved particularly effective, offering several key advantages:
Reduced token fertility: The adapted models processed Italian text more efficiently, with 25% fewer tokens for Mistral and 16% fewer for Llama compared to the original English tokenizers.
Smaller model size: For Llama-3.1-8B, adaptation reduced the model size by 10% (from 8B to 7.25B parameters) by shrinking the vocabulary by 75%.
Faster convergence: SAVA-initialized models reached good performance with significantly less training, potentially reducing computational resources needed.
Maintained capabilities: The adapted models performed well on both Italian and English tasks, showing that cross-lingual capabilities can be preserved.
These results demonstrate that language-specific adaptation of existing LLMs offers a practical path forward for languages with limited resources. Rather than training new models from scratch, adapting English LLMs with methods like SAVA provides an efficient way to create better language-specific models.
The research also highlights how important tokenizer choice is for language model efficiency. A tokenizer optimized for the target language significantly reduces computational requirements and improves processing speed.
Limitations and Ethical Considerations
Despite promising results, several limitations should be noted:
Limited model selection: The study focused on just two models (Mistral-7B-v0.1 and Llama-3.1-8B), which may not represent all architectures.
Translated benchmarks: The evaluation relied on automatically translated datasets, which may introduce noise or miss language-specific nuances.
Web-based training data: The CulturaX dataset comes from web sources, which may contain biases or personal information that could affect model behavior.
Language transfer: Adapting English models to Italian may carry over biases or behavioral patterns from the source language, rather than reflecting Italian cultural contexts.
Future work should expand to more languages, particularly low-resource ones, and investigate how vocabulary adaptation affects models' ability to understand cultural nuances. Creating native benchmarks in target languages would also provide more accurate evaluation.
