
Hi everyone, I’m excited to share a*simple yet common scenario of MySQL-to-MySQL data synchronization and mergingthrough theSeaTunnel Demo Ark Project*.
I’m Fei Chen, currently working in the Infrastructure Department at Zhongfu Payment, focusing on real-time data cleansing and processing of transaction data. The case I’ll walk through today is inspired by a real problem we faced at work. I hope it provides inspiration, and I welcome seasoned engineers to share their thoughts and experiences too.
🧩 Version Prerequisites
- Apache SeaTunnel →
Apache-SeaTunnel-2.3.9
📌 Scenario Overview

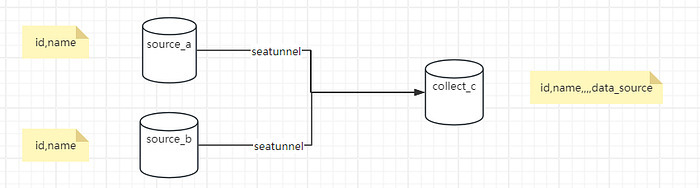
In our business system, we have two MySQL source databases:
-
source_a -
source_b
Both databases contain an identically structured table, but the data comes from different business lines. Since both sources generate data simultaneously,primary key conflictscan occur.
Our goal is to*merge and sync data from both sources into a unified MySQL target database (referred to as database C)*, enabling centralized analysis and querying.
🚧 Challenges
- Though the schemas are identical,primary key duplicationcan lead to conflicts.
- Future schema changes, such as new fields or inconsistent types, need to be handled gracefully.
- The process must be*as real-time as possible*without introducing duplicate records.
✅ Solution Overview
We implemented the following approach for merging and synchronizing the data:
🛠️ Creating the Target Table in Database C
- The target table includes all fields from both source tables (they’re identical for now, but may evolve).
- We added an extra field:
data_sourceto identify the origin (source_aorsource_b). - Non-nullable fields were assigned default values to avoid insert failures.
🔑 Defining a Composite Primary Key
- We used the combination of the*original primary key + data_source*to form a composite key, preventing conflicts between identical primary keys across different sources.
🚀 Using Two Separate SeaTunnel Jobs
- Each job uses the*MySQL CDC Connector*to capture changes from
source_aandsource_b. - Every record is tagged with a
data_sourceidentifier during transformation. - Data is written into the target database using the*JDBC Sink*.
💡 Live Demo
Let’s dive into a real example. I’ll skip SeaTunnel basics (they were already well covered in a previous session), and focus directly on implementation.
🔍 Pre-requisites for MySQL CDC
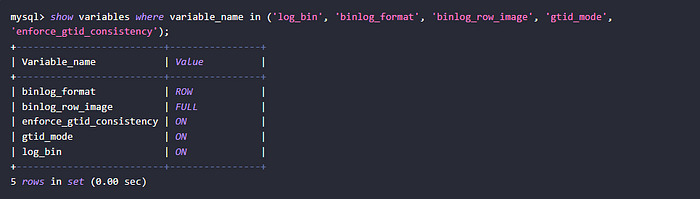
To use themysql-cdcconnector, make sure these two conditions are met:
1. Enable Binlog in Source MySQL
-- Check current settings
SHOW VARIABLES LIKE 'binlog_format';
SHOW VARIABLES LIKE 'binlog_row_image';
Ensure the following configurations inmy.cnf
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog-format = ROW
binlog-row-image = FULL
📖 For more details and permission setups, refer to theofficial SeaTunnel documentation.
2. Create a User with Replication Privileges
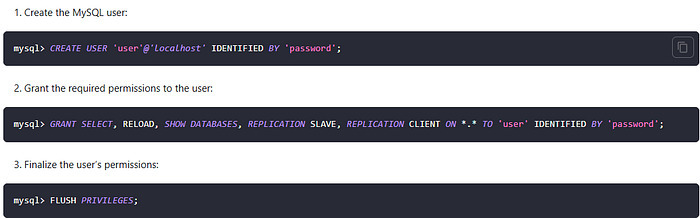
-- Create user
CREATE USER 'cdc_user'@'%' IDENTIFIED BY 'your_password';
-- Grant required permissions
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON . TO 'cdc_user'@'%';
FLUSH PRIVILEGES;
📦 Preparing SeaTunnel and Plugins
Option 1: Download the Official Binary
Ideal if your server has internet access and no custom plugin needs.
- Download:SeaTunnel Releases
- Manually install required plugins (
mysql-cdc,jdbc)
wget "https://archive.apache.org/dist/seatunnel/${version}/apache-seatunnel-${version}-bin.tar.gz"
# Keep only necessary plugins in config/plugin_config
bin/install-plugin.sh
Option 2: Build from Source
Best if you want full plugin control or offline support:
sh ./mvnw clean install -DskipTests -Dskip.spotless=true
# Output binary: seatunnel-dist/target/apache-seatunnel-2.3.9-bin.tar.gz
🔧 All plugins and dependencies are included by default in the compiled package.
🚀 Deployment Modes
Apache SeaTunnel supports several deployment modes:
- Zeta engine(standalone)
- Run as*SparkorFlink*jobs
In this example, we use*Zeta engine*, which supports three modes:run,start, andclient.
📂 Config File Breakdown
A typical SeaTunnel job configuration consists of four sections:
- Env: Engine settings
- Source: Input configuration
- Transform(optional): Data transformation
- Sink: Output configuration
⚙️ Env Configuration

env {
parallelism = 2
job.mode = "STREAMING"
checkpoint.interval = 30000
}
-
parallelism: Number of concurrent tasks -
job.mode: Formysql-cdc, must beSTREAMING -
checkpoint.interval: Interval for state checkpointing
📥 Source Configuration (MySQL CDC)
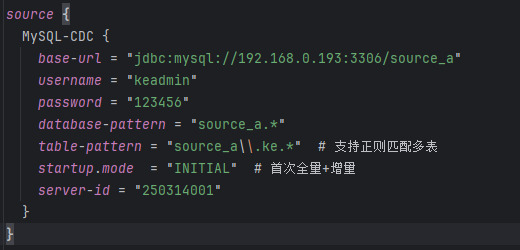
Essential parameters include:
- Connection details (host, port, user, password)
-
database-names,table-names -
startup.mode: Default is "initial" (full + incremental) -
server-id: Must be unique if multiple jobs are used
💡 Ensure
_binlog_is enabled and configured as mentioned earlier.
🔄 Transform Configuration (Optional)
We use a**sql**transformto add a constant fielddata_source:
transform {
sql {
sql = "SELECT *, 'source_a' AS data_source FROM source_table"
}
}
-
source_tableis a built-in keyword referencing the upstream data - Each source table can apply its own transformation logic
📤 Sink Configuration (JDBC)
sink {
jdbc {
url = "jdbc:mysql://target-db:3306/db_c"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
table = "target_table"
primary_keys = ["id", "data_source"]
support_upsert_by_query_primary_key_exist = true
}
}
Other optional settings:
- schema_save_mode: e.g.,
create-if-not-exist - data_save_mode: e.g.,
append
🧪 Sink Optimization & Performance Tips
- Batching: Use
batch_sizeandbatch_interval_msto balance latency and throughput. - Primary Key Handling: Make sure to define the right composite primary key.
✅ Conclusion
With this setup, we achieved:
- Real-time synchronizationof data from two independent MySQL sources
- Unified target table, augmented with source identifiers
- Scalability for schema changesand multiple use cases
This approach provides a*flexible and production-ready pattern for data integration*, especially when dealing with decentralized microservices or multi-business-line architectures.