This is a Plain English Papers summary of a research paper called Self-Training Boosts Code Generation: RewardRanker Outperforms GPT-3.5 & Rivals GPT-4. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Better Code Generation Through Self-Training
Code generation models have struggled with the highly stochastic nature of token-by-token generation. Even minor errors in a program can break the entire solution. This challenge shows up in standard benchmarks, where the disparity between Pass@1 and Pass@100 metrics can exceed two-fold.
To address these issues, researchers from MTS AI introduce RewardRanker, a novel approach that enhances code generation by pairing a code generation model with a reranker model. The reranker selects the best solution from multiple generated samples, significantly improving output quality.
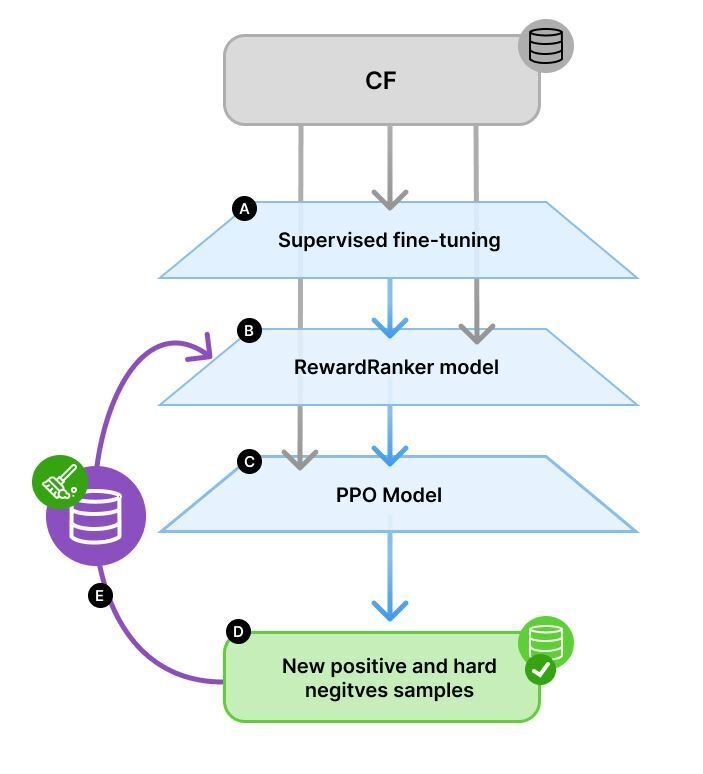
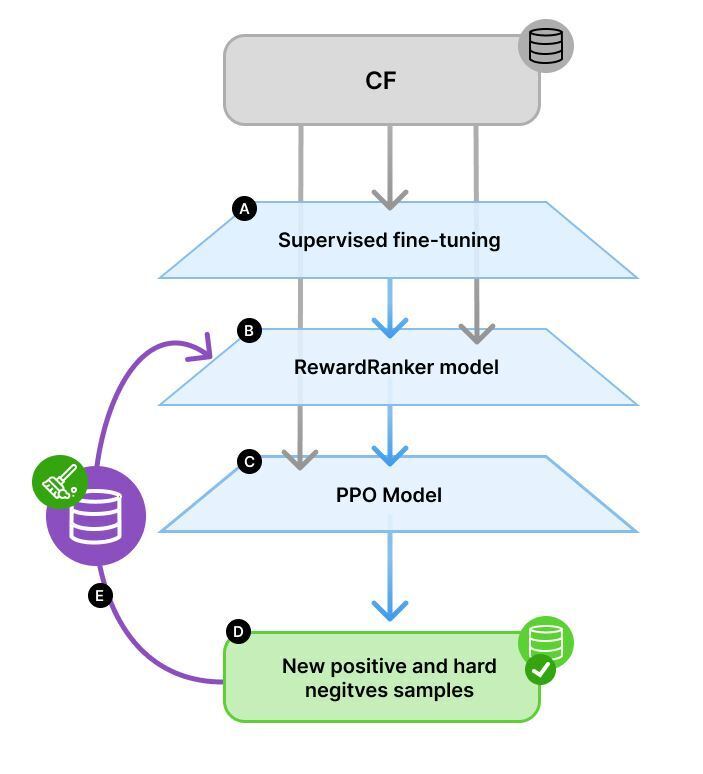
Iterative Self-Training Workflow for RewardRanker showing the complete training cycle from supervised fine-tuning through feedback incorporation.
Related Work: Advances in Code Generation and Reinforcement Learning
Code generation using large language models has evolved through specialized models like CodeBERT, Codex, CodeT5, and StarCoder. These models demonstrate that incorporating code into training data enables effective program synthesis.
Reinforcement learning approaches have further refined code generation. Notable examples include CodeRL and PPOCoder, which use actor-critic deep RL to optimize functional correctness through test case validation.
Similar work includes LEVER, which trains verifiers to assess generated code based on execution results. While LEVER focuses on reranking using execution results, RewardRanker takes a different approach by leveraging reinforcement learning to enhance the generation process itself. Crucially, RewardRanker doesn't require predefined tests during inference—tests are only needed during training, making it more flexible and scalable.
Datasets: Training and Evaluation Data
The researchers created their dataset from CodeContests and public Codeforces solutions, enriched with metadata. For supervised fine-tuning, they structured the data as prompt-completion pairs, using problem statements as prompts and solutions as completions. The balanced dataset contained 1.2 million samples, each averaging 1,500 tokens.
For alignment training, data was formatted as prompt-preferred-disfavored triplets. CodeContests' mix of correct and incorrect solutions provided a natural structure, with "OK" verdicts marking preferred solutions and others as disfavored. This approach yielded 2 million robust training triplets.
Evaluation used two key datasets:
- MultiPL-E: A system for translating unit test-driven code generation benchmarks into multiple programming languages
- MBPP: A dataset of 974 Python programming problems designed for evaluating program synthesis models
Method: The RewardRanker Approach
RewardRanker enhances code generation through an iterative self-training cycle that continually refines the reward model. The process includes:
Supervised Fine-Tuning (SFT): The generator model is fine-tuned on the dataset using causal language modeling to adapt to the code domain.
Reward Model Training: A reward model scores generated code outputs, using a loss function inspired by the Bradley-Terry model to prioritize correct solutions over incorrect ones.
Proximal Policy Optimization (PPO): Further optimization maximizes rewards from the reward model, guiding the model to generate better code.
Self-Training Cycle: After PPO training, the model generates new solutions evaluated on task test cases. Incorrect but highly ranked solutions (hard negatives) are included in an updated training set to refine the reward model's accuracy.
Retraining and Iterative Refinement: With the updated reward model, a new PPO model is trained from scratch, resulting in better alignment with reward model evaluations.
The researchers developed several model variants:
- RewardRanker (1.3B + 6.7B): Uses 1.3B model as code generator and 6.7B model as reranker
- RewardRanker (6.7B + 6.7B): Both generator and reranker use 6.7B model
- RewardRanker 2 iter.hardnegatives: Trained with hard negatives
- RewardRanker 2 iter.selftraining: Refined with self-training examples
Results: Performance Analysis
The experiments validate RewardRanker's effectiveness in improving code generation quality. For evaluation, the model ranks the top 10 generated solutions per task based on reranker scores.
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Close models | ||||||||||
| GPT-3.5-Turbo [22] | - | 76.2 | 63.4 | 69.2 | 60.9 | 69.1 | 70.8 | 42.4 | 67.1 | 64.9 |
| GPT-4 [17] | - | 84.1 | 76.4 | 81.6 | 77.2 | 77.4 | 79.1 | 58.2 | 78.0 | 76.5 |
| Open models | ||||||||||
| DeepSeek-Coder-Instruct [11] | 1.3 B | 65.2 | 45.3 | 51.9 | 45.3 | 59.7 | 55.1 | 12.7 | 52.2 | 48.4 |
| DeepSeek-Coder-Instruct [11] | 6.7 B | 78.9 | 63.4 | 68.4 | 68.9 | 67.2 | 72.8 | 36.7 | 72.7 | 66.1 |
| DeepSeek-Coder-Instruct [11] | 33B | 79.3 | 68.9 | 73.4 | 72.7 | 67.9 | 74.1 | 43.0 | 73.9 | 69.2 |
| RewardRanker $(1.3 \mathrm{~B}+6.7 \mathrm{~B})$ | 8B | 77.3 | 72.3 | 70.6 | 66.3 | 66.0 | 74.4 | 35.8 | 73.9 | 67.1 |
| RewardRanker $(6.7 \mathrm{~B}+6.7 \mathrm{~B})$ | 13.4B | 78.9 | 75.7 | 74.6 | 72.1 | 66.4 | 75.1 | 41.4 | 74.3 | 69.9 |
| RewardRanker 2 iter.-hardnegatives | 13.4B | 80.2 | 77.9 | 73.4 | 71.6 | 66.4 | 75.8 | 38.2 | 73.8 | 69.7 |
| RewardRanker 2 iter.-selftraining | 13.4B | 81.7 | 79.2 | 77.4 | 71.6 | 67.0 | 75.2 | 39.6 | 75.1 | 70.9 |
Table 1. Model performance comparison on MultiPL-E. Best result is in bold, second best is in italic. Percentage of solved tasks.
As shown in Table 1, RewardRanker substantially improves average performance across languages. The RewardRanker 1.3B model, paired with DeepSeek-Coder-Instruct 6.7B, achieves 67.1% accuracy, rivaling larger 33B models. The RewardRanker 6.7B model further increases accuracy to 69.9%, outperforming GPT-3.5-turbo.
When compared to the LEVER approach on the MBPP dataset, RewardRanker consistently delivers better results:
| Model | Parameters (Billion) | Performance (%) |
|---|---|---|
| codex-davinci-002 | - | 62.0 |
| DeepSeek-Coder-Instruct | 6.7 | 65.4 |
| Lever [15] | - | 68.9 |
| Lever (DeepSeek-Coder) | $6.7+1.3$ | 69.4 |
| RewardRanker | $6.7+1.3$ | $\mathbf{69 . 9}$ |
Table 2. Model performance on MBPP
Conclusion: Achievements and Future Directions
RewardRanker demonstrates that combining a code generation model with a reranker model through iterative self-training can significantly enhance code generation quality. By leveraging Proximal Policy Optimization in a self-training loop, the approach refines both reranking accuracy and overall code quality.
The most impressive achievement is that the 13.4B parameter RewardRanker model outperforms larger models like a 33B parameter model while being three times faster. It even achieves performance comparable to GPT-4 and surpasses it in C++ programming.
Future work will explore additional domains for pretraining to further investigate the combined capabilities of RewardRanker and the PPO-based generation model in a self-training setup. This aims to improve overall quality across a broader range of coding tasks.
