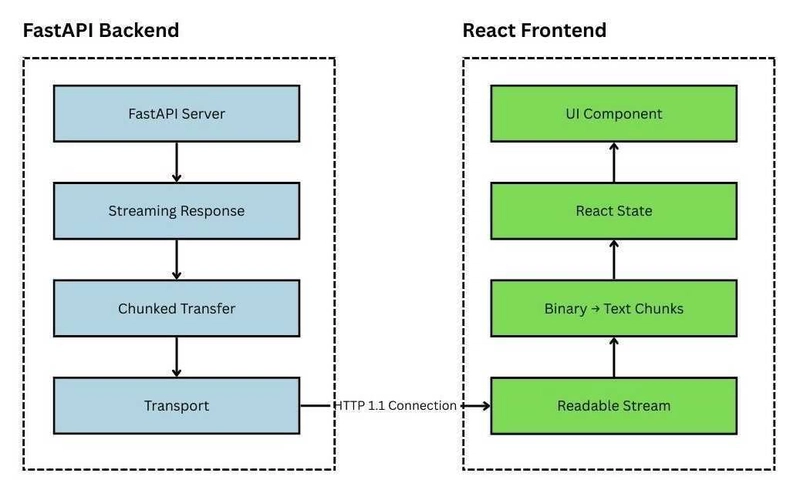
In Part 1, we explored how to stream data into a React component using modern browser APIs. Now it’s time to build the other half: the FastAPI backend that makes it all work.
In this post, we’ll walk through setting up a streaming endpoint using FastAPI and discuss how chunked transfer encoding works on the server side.
💡 Code Repository : The complete code is available on GitHub. You can clone it and run it locally to follow along.
🛠️ Building the Streaming Backend with FastAPI
FastAPI makes it really easy to return a streaming response using its StreamingResponse class from starlette.responses.
Let’s build a /stream endpoint in index.py that simulates real-time data like server logs or chat messages.
🚀 Simulating a Real-Time Log Stream
Here’s a minimal FastAPI app with a streaming endpoint:
# backend/index.py
from typing import Any, Generator
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import time
import os
import uvicorn # Import uvicorn for running the server
import threading
app = FastAPI()
# Add CORS middleware to allow cross-origin requests
# ...
LOG_FILE_PATH = "logs/server.log"
def log_stream(log_file_path: str) -> Generator[str, None, None]:
try:
with open(log_file_path, "r") as log_file:
# Move to the end of the file
_ = log_file.seek(0, os.SEEK_END)
while True:
line = log_file.readline()
if line:
yield line
else:
yield "Waiting for new log entries...\n" # Heartbeat message
time.sleep(1) # Wait for new lines to be written
except FileNotFoundError:
yield "Log file not found.\n"
except Exception as e:
yield f"Error reading log file: {str(e)}\n"
def simulate_log_generation():
"""Simulate log entries being written to the log file."""
while True:
with open(LOG_FILE_PATH, "a") as log_file:
log_file.write(f"Simulated log entry at {time.ctime()}\n")
time.sleep(5) # Write a new log entry every 5 seconds
@app.on_event("startup")
def start_log_simulation():
"""Start the log simulation in a background thread."""
threading.Thread(target=simulate_log_generation, daemon=True).start()
@app.get("/stream")
def stream():
return StreamingResponse(log_stream(LOG_FILE_PATH), media_type="text/plain")🧠 How It Works
Let’s break it down:
1. Synchronous Generator
def log_stream(log_file_path: str) -> Generator[str, None, None]:
try:
with open(log_file_path, "r") as log_file:
_ = log_file.seek(0, os.SEEK_END)
while True:
line = log_file.readline()
if line:
yield line
else:
yield "Waiting for new log entries...\n"
time.sleep(1)
except FileNotFoundError:
yield "Log file not found.\n"
except Exception as e:
yield f"Error reading log file: {str(e)}\n"We define a synchronous generator function that yields data one chunk at a time. Each yield becomes a chunk sent to the client. The time.sleep(1) simulates delay between events (like logs being written).
2. StreamingResponse
StreamingResponse(log_stream(LOG_FILE_PATH), media_type="text/plain")StreamingResponse tells FastAPI to send the data as it becomes available, rather than waiting for the entire response to be generated. The media_type is optional but helps inform the browser how to handle the content.
⚙️ Running the Server
To run the server:
make start-backendThen hit:
http://localhost:8000/stream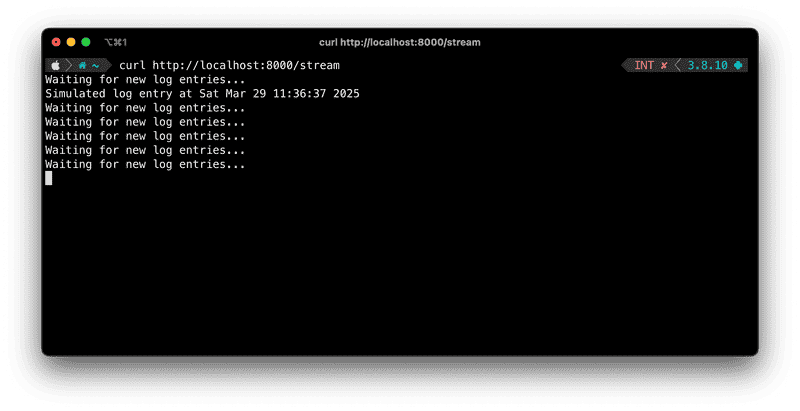
You should see logs appear one line at a time in the terminal or browser, depending on how you call the endpoint.
💡 Tips for Production
✅ Keep the Stream Alive
In a real app, your data stream might be longer-running. Our example already implements this with a heartbeat:
if line:
yield line
else:
yield "Waiting for new log entries...\n" # Heartbeat message
time.sleep(1) # Wait for new lines to be writtenThis ensures the client knows the connection is still alive even when there’s no new data.
🧹 Handle Disconnects Gracefully
If the client disconnects, your generator should stop yielding. Starlette handles this internally, but you can wrap the stream in a try/except block to catch cancellations if needed.
🔐 Secure Your Stream
- Add authentication if you’re streaming sensitive data.
- Rate-limit the endpoint to avoid abuse.
🧪 Testing with Curl
You can test the streaming endpoint with:
curl http://localhost:8000/streamYou should see each message appear line by line, every second.
🔗 Hooking it up with the Frontend
Now that our backend is streaming correctly, the frontend from Part 1 will handle it smoothly:
const response = await fetch("http://localhost:8000/stream");
const reader = response.body.getReader();
// ...As each yield in the backend emits data, your React UI will update in near real-time. ✨
🧠 Recap
In this post, we built a real-time streaming API using FastAPI with just a few lines of code. Here’s what we did:
- Built a synchronous generator to simulate streaming logs
- Used
StreamingResponseto stream text over HTTP - Connected it to our frontend from Part 1
Together, the backend and frontend make a simple but powerful full-stack streaming system.
🧱 Next Steps
- 🔌 Add dynamic data (e.g. logs from a file or DB)
- 📦 Stream structured data (like JSON Lines)
- 📈 Use this setup for real-time dashboards or log viewers
🛠️ Useful Links
If you enjoyed this series, feel free to star the repo ⭐ or share it with a friend. Got ideas or feedback? Hit me up on Twitter or drop an issue in the GitHub repo.
Happy streaming! 🚀