🎯 Introdução
A experiência do usuário com chatbots é diretamente impactada pelo tempo de espera. Quando um usuário envia uma mensagem e fica observando um indicador de carregamento sem feedback imediato, a sensação de lentidão no sistema é inevitável - mesmo que o tempo total de resposta seja OK.
É aqui que entra o streaming de respostas: em vez de aguardar que a IA termine de gerar a resposta completa, é possível exibir o conteúdo progressivamente, o que proporciona uma experiência mais dinâmica para o usuário.
Neste tutorial, vamos implementar streaming em tempo real para respostas de IA usando server-sent events (SSE) com FastAPI e Vue.js. Vamos transformar o uso de um chatbot comum em uma interação fluida.
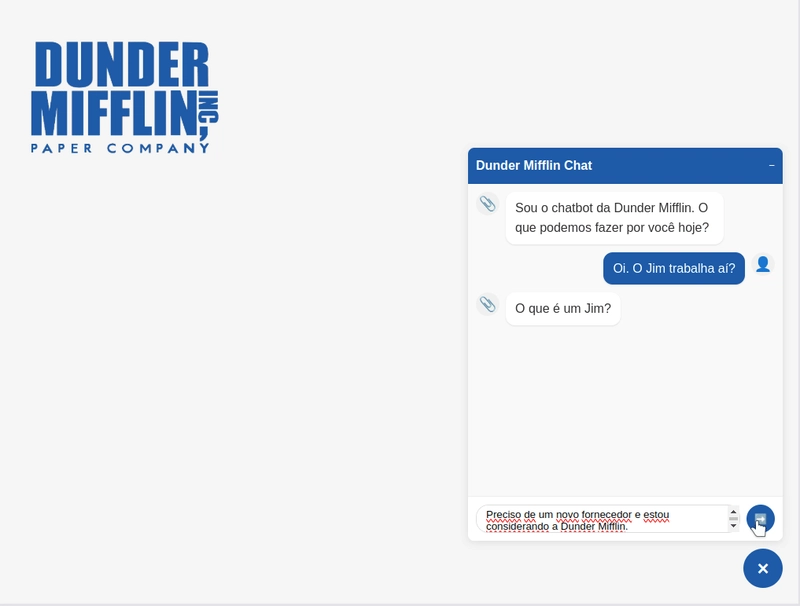
Nosso exemplo é um assistente virtual da Dunder Mifflin Paper Company, empresa da série "The Office". E, caso você não seja fã de "The Office", um aviso sobre a resposta na imagem abaixo: o chatbot não é burro - é só uma piada da série. 🤓
📚 Entendendo conceitos fundamentais
O chatbot usa uma tecnologia de resposta em tempo real que torna a conversa mais natural e fluida.
🌊 Como funciona o streaming no chatbot
Quando a usuária envia uma mensagem pelo chatbot:
- O frontend estabelece uma conexão que permanece aberta com o backend
- O backend inicia uma conexão que também permanece aberta com o LLM
- Conforme o LLM gera o texto, cada pedaço é enviado imediatamente: LLM → Backend → Frontend → Tela do usuário
Esta "ponte" de dados contínua elimina esperas e cria a experiência de ver o texto sendo digitado em tempo real.
🔄 Streaming vs. requisições tradicionais
Requisições tradicionais:
- O cliente envia um pedido e espera a resposta completa
- A usuária vê uma indicação de carregamento ou espera
- Só depois de pronta, a resposta inteira aparece
Com streaming:
- O texto começa a aparecer em segundos
- A usuária vê a resposta sendo construída em tempo real
- A interface nunca fica "travada" esperando
📡 O que são server-sent events (SSE)?
SSE é a tecnologia que usamos para criar o streaming entre o backend e o frontend. Com o SSE:
- O backend envia atualizações contínuas ao cliente
- Uma única conexão HTTP permanece aberta
- O navegador gerencia a conexão (reconexão automática, manutenção do canal)
- O frontend processa e formata o conteúdo dos eventos
- Os dados fluem em um formato simples e padronizado
Cada pequeno pedaço de texto gerado pelo LLM é formatado como um "evento" SSE:
data: {"text": "Olá, como"}\n\n
data: {"text": " posso ajudar?"}\n\n
data: [DONE]
🚀 Benefícios do streaming com IAs
O chatbot aproveita o streaming oferecido pelos LLMs modernos para:
- Resposta imediata: O usuário vê o texto aparecendo em segundos
- Experiência mais natural: Simula uma pessoa digitando em tempo real
- Controle melhorado: É possível interromper respostas inadequadas rapidamente
- Leitura antecipada: O usuário lê o início da resposta enquanto o restante ainda está sendo gerado
Esta abordagem cria uma experiência de conversa muito mais dinâmica e interativa do que sistemas de chat tradicionais.
Fluxo de streaming com SSE

🛠️ Implementação do backend (FastAPI)
🔧 Estrutura do Backend
O backend está organizado da seguinte forma:
dunder_mifflin_py/
├── app/
│ ├── api/ # Endpoints da API
│ ├── core/ # Configurações centrais
│ ├── data/ # Dados e prompts
│ └── services/ # Serviços de negócio
└── requirements.txt
📊 Classe de Serviço SSE
Primeiro, criamos um serviço dedicado para lidar com as respostas SSE:
# app/services/sse_service.py
from fastapi.responses import StreamingResponse
import json
from typing import AsyncGenerator
class SSEService:
"""Service for managing Server-Sent Events (SSE)."""
def create_stream_response(self, generator: AsyncGenerator) -> StreamingResponse:
"""
Creates an SSE streaming response from an async generator.
Args:
generator: An async generator producing text fragments
Returns:
A configured StreamingResponse object for SSE
"""
return StreamingResponse(
generator,
media_type="text/event-stream"
)
async def create_error_event(self, message: str) -> AsyncGenerator[str, None]:
"""
Creates error events to send via SSE.
Args:
message: Error message
Returns:
An async generator with the error event
"""
async def error_generator():
yield f"data: {json.dumps({'error': message})}\n\n"
yield "data: [DONE]\n\n"
return error_generator()
Essa classe encapsula a criação de respostas SSE, o que facilita gerar tanto respostas normais quanto de erro no formato SSE.
🧠 Serviço de IA com Streaming
Agora, vamos olhar para o cerne da implementação: a integração com a API de IA da Google com suporte a streaming.
Escolhi a API da Google porque ela oferece um limite alto pra teste gratuito sem a necessidade de inserir um cartão de crédito. Mas é importante ter em mente que existe um motivo pelo qual é gratuito.
⚠️ Lembre-se: Se você não paga pelo produto, você é o produto.
# app/services/ai_service.py - versão simplificada
async def generate_response(self, message: str, company_data: Dict[str, Any]):
try:
# Configuração do streaming com a API do Google
response_stream = self.model.generate_content(
contents=[/* configuração */],
stream=True # Ativa o streaming!
)
async def response_generator():
try:
for chunk in response_stream:
if hasattr(chunk, 'text') and chunk.text:
# Formata cada pedaço como um evento SSE
yield f"data: {json.dumps({'text': chunk.text})}\n\n"
# Sinaliza o fim do stream
yield "data: [DONE]\n\n"
except Exception as e:
# Tratamento de erro omitido
return response_generator()
except Exception as e:
# Tratamento de erro omitido
Pontos importantes:
- Definir
stream=Trueao chamar a API de IA - Criar um gerador assíncrono que converte cada fragmento de resposta em um evento SSE
- Sinalizar o fim do stream com uma mensagem
[DONE]
🌐 Endpoint de chat com SSE
Finalmente, vamos juntas as peças no endpoint da API:
# app/api/chat.py
@router.post("/",
summary="Send a message to the Dunder Mifflin chatbot"
)
async def chat(request: ChatRequest):
"""
Process user messages and return chatbot responses via SSE.
"""
try:
if not request.message:
raise HTTPException(status_code=400, detail="Message cannot be empty")
dunder_mifflin_data = get_dunder_mifflin_data()
response_generator = await ai_service.generate_response(
request.message, dunder_mifflin_data
)
return sse_service.create_stream_response(response_generator)
except Exception as e:
logger.error(f"Error processing chat request: {str(e)}")
error_generator = await sse_service.create_error_event(f"Error: {str(e)}")
return sse_service.create_stream_response(error_generator)Este endpoint recebe a mensagem do usuário, passa a mensagem para o serviço de IA e retorna a resposta como um stream SSE.
Bom demais! Python entregando tudo e mais um pouco!
🖥️ Implementação do frontend (Vue.js)
Agora, vamos consumir o stream no lado do cliente usando meu amado Vue.js.
🔧 Estrutura do Frontend
O frontend está organizado da seguinte forma:
dunder_mifflin_vue/
├── src/
│ ├── assets/ # Arquivos estáticos e estilos CSS
│ ├── components/ # Componentes Vue reutilizáveis
│ ├── composables/ # Lógica de negócios e gerenciamento de estado
│ └── ultils/ # Funções utilitárias (como o parser SSE)
├── public/ # Arquivos estáticos públicos
└── index.html # Ponto de entrada HTML
🔍 Parser de SSE
Primeiro, criamos uma classe para processar os eventos (SSE) recebidos:
// src/ultils/sseParser.js - versão simplificada
export class SSEParser {
constructor() {
this.buffer = '';
this.fullResponse = '';
}
processChunk(chunk, onMessage, onComplete, onError) {
try {
this.buffer += chunk;
// Dividir o buffer em mensagens individuais (separadas por \n\n)
const messages = this.buffer.split('\n\n');
this.buffer = messages.pop() || '';
// Processar cada mensagem
for (const message of messages) {
if (!message.trim()) continue;
const result = this.parseSSEMessage(message);
if (result === '[DONE]') {
if (onComplete) onComplete(this.fullResponse);
} else if (result) {
if (onMessage) onMessage(result);
this.fullResponse += result;
}
}
return this.fullResponse;
} catch (error) {
// Tratamento de erro simplificado
if (onError) onError('Error processing server response');
return this.fullResponse;
}
}
// Resto da implementação omitido
}
Este parser:
- Acumula dados recebidos em um buffer
- Divide o buffer em mensagens SSE individuais (separadas por
\n\n) - Processa cada mensagem, extraindo seu conteúdo
- Fornece callbacks para diferentes eventos (nova mensagem, conclusão, erro)
🔌 Serviço de API
Em seguida, precisamos de um serviço para lidar com as chamadas de API e o processamento de stream:
// src/composables/useAPI.js - trecho principal
const sendMessage = async (message, onChunk, onComplete, onError) => {
try {
// Configuração da requisição omitida
const response = await fetch(apiUrl, { /* configuração */ });
// Importante: configuração do streaming
const reader = response.body.getReader();
const decoder = new TextDecoder();
const parser = new SSEParser();
// Loop de leitura do stream
while (true) {
const { value, done } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
parser.processChunk(chunk, onChunk, onComplete, onError);
}
} catch (err) {
// Tratamento de erro omitido
}
};
Este serviço:
- Aproveita o
response.body, que já é umReadableStreamretornado pela APIFetch - Usa o método getReader() para consumir o stream chunk por chunk
- Utiliza
TextDecoderpara converter os bytes recebidos em texto, mantendo contexto entre chunks com o parâmetro{ stream: true } - Processa cada fragmento com o parser SSE
Essa abordagem elimina a necessidade de esperar a resposta completa, e permite o processamento dos dados à medida que chegam do servidor.
📱 Composable de chat
Finalmente, vamos gerenciar o chat com um composable:
// src/composables/useChat.js
import { ref } from 'vue'
import { useAPI } from './useAPI'
export function useChat() {
const { isLoading, error, sendMessage: apiSendMessage } = useAPI()
const messages = ref([])
const userInput = ref('')
const isChatOpen = ref(false)
if (messages.value.length === 0) {
messages.value.push({
sender: 'bot',
text: 'Sou o chatbot da Dunder Mifflin. O que podemos fazer por você hoje?'
})
}
const toggleChat = () => {
isChatOpen.value = !isChatOpen.value
}
const sendMessage = async () => {
if (!userInput.value.trim() || isLoading.value) return
messages.value.push({
sender: 'user',
text: userInput.value
})
const messageToSend = userInput.value
userInput.value = ''
const botMsgIndex = messages.value.length
messages.value.push({
sender: 'bot',
text: '',
streaming: true
})
await apiSendMessage(
messageToSend,
(chunk) => {
// Callback para cada novo fragmento recebido
if (messages.value[botMsgIndex]) {
messages.value[botMsgIndex].text += chunk;
}
},
() => {
// Callback para conclusão do stream
if (messages.value[botMsgIndex]) {
messages.value[botMsgIndex].streaming = false;
}
},
(errorMsg) => {
// Callback para erros
if (messages.value[botMsgIndex]) {
messages.value[botMsgIndex].text = 'Connection error. Please try again later.';
messages.value[botMsgIndex].streaming = false;
}
}
)
}
return {
messages,
userInput,
isLoading,
error,
isChatOpen,
toggleChat,
sendMessage
}
}
O composable de chat:
- Prepara o estado inicial do chat
- Adiciona uma mensagem do bot quando criado
- Gerencia o estado de streaming para cada mensagem
- Atualiza progressivamente o texto da mensagem conforme novos fragmentos chegam
- Altera o status de streaming quando a resposta completa é recebida
⌨️ Bônus: componente de efeito de digitação
Para melhorar a experiência do usuário, vamos criar um efeito que faz com que o texto pareça estar sendo digitado em tempo real.
// src/components/TypeWriter.vue
<script setup>
// Imports e setup inicial omitidos
const typeNextCharacter = () => {
if (textIndex.value < props.text.length) {
// Exibe o texto progressivamente
displayedText.value = props.text.substring(0, textIndex.value + 1)
textIndex.value += 1
// Programa a próxima letra
timer.value = setTimeout(typeNextCharacter, props.speed)
}
}
// Resto omitido
script>
<template>
class="typewriter-text">{{ displayedText }}
template>
Este componente:
- Recebe o texto completo do stream
- Exibe o texto gradualmente, simulando alguém digitando
- Emite eventos de atualização para permitir ajustes de UI (como rolar para baixo)
Resumo do fluxo no frontend
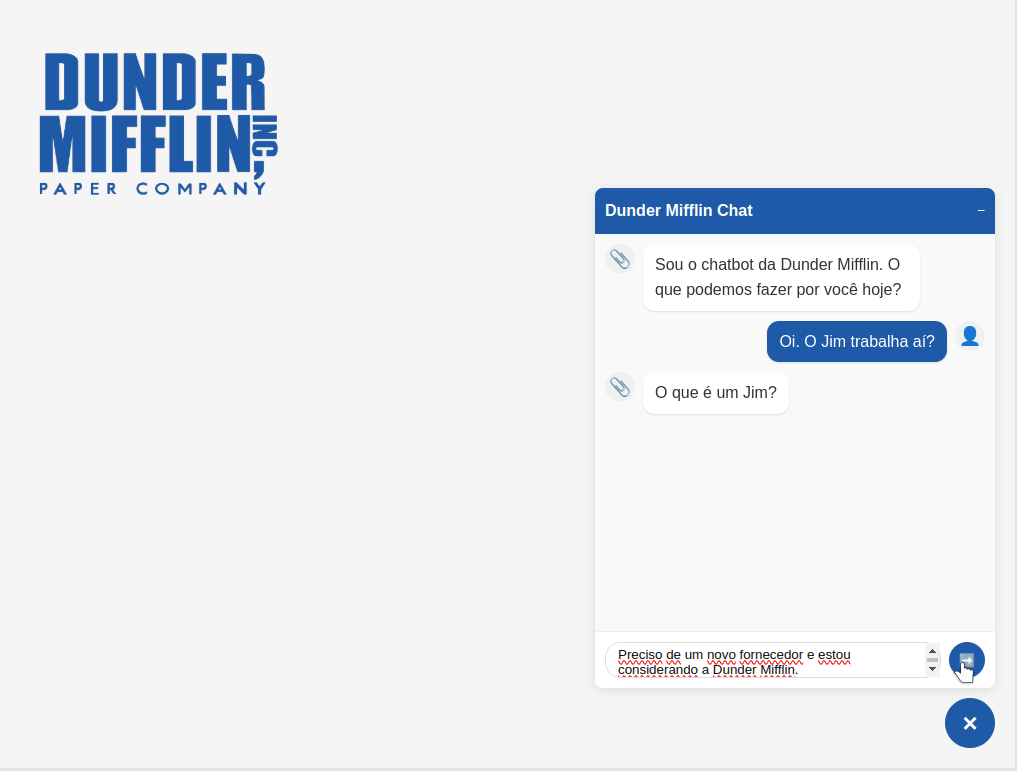
Entrada do usuário: No componente de chat, o usuário digita uma mensagem e clica no botão de envio.
Processamento da mensagem: O composable de chat adiciona imediatamente a mensagem do usuário ao array de mensagens e cria uma mensagem vazia do bot com flag
streaming: true, para indicar que a resposta está em andamento.Preparação da requisição: No composable da API, a requisição HTTP POST para o endpoint do backend é preparada.
Estabelecimento de conexão SSE: O frontend abre uma conexão HTTP com o backend e configura o modo de stream para ficar escutando eventos. O parser de SSE, utilitário, permanece ativo, monitorando continuamente o fluxo de dados recebidos.
Processamento do stream: À medida que o backend envia eventos no formato SSE, o parser de SSE captura cada chunk de dados, processa as informações e mantém a conexão aberta para continuar recebendo mais dados.
Atualização gradual da interface: Cada fragmento de texto extraído é imediatamente adicionado à mensagem do bot no array
messages, sem esperar a resposta completa.Renderização em tempo real: O componente de digitação renderiza cada fragmento de texto recebido na interface, criando o efeito de digitação progressiva que simula uma resposta sendo digitada em tempo real.
Finalização da conexão: Quando o backend envia o evento especial
[DONE], o parser detecta o fim da transmissão, a flagstreamingé alterada parafalsee a conexão HTTP é encerrada.
📝 Conclusão
Implementar streaming de respostas com SSE para chatbots de IA traz benefícios significativos para a experiência do usuário, tempo de resposta percebido e eficiência geral do sistema. Neste tutorial, exploramos uma implementação completa usando:
- 🐍 FastAPI
- 🟢 Vue.js
- 🌊 Streaming eficiente de respostas em tempo real
O código completo está disponível no repositório do projeto. Se você tiver dúvidas ou sugestões, deixe um comentário abaixo!
Esta foi a minha contribuição para a Dunder Mifflin Infinity 3.0.
📄 Papel ilimitado em um mundo sem papel...
E agora com respostas em streaming!
