
There are a lot of tools for fixing desynced subtitles, and many video players even have them inbuilt. Not knowing this at the time, I made a simple sync tool from the sheer exhaustion of having to always look for subtitles that correctly followed the content they’re for, whenever I had a desync problem. In this two-part walkthrough, l’ll explain how I did it.
Here, in this part, we’ll look at the underlying ideas behind the implementation, which we’ll see in the next part.
Let’s get started!

What's a subtitle?
It’s simply an on-screen textual representation of audio or dialogue, and other video cues. The texts that appear on the screen are called captions and, when we’re watching a video, they’re typically shown at the bottom of the screen to match the spoken words, either in the same language as the audio or in a different one.
Interestingly, a “subtitle” is also the actual file where the captions we see on screen are stored. We’re interested in the file, and how it’s structured, so we’ll understand how to modify it.
Subtitle synchronization
One reason for providing subtitles is to increase content accessibility, as they make it easier for people with hearing difficulties to follow up with the content. When they’re not synced, it really defeats their purpose, because you’ll see the captions coming up earlier or later than the audio.
So, in trying to sync a subtitle with audio we’re only looking to get the captions to appear at the correct time in playback, so they’re matched with audio.
For us to do this, we have to see what the file looks like and, in our case, this will be the SRT format.
The SRT file format
The SubRip Subtitle (.srt) is just one of many subtitle formats, and the most common one you’ll find. Its contents are in plain human-readable texts, structured in a way that makes it easy to understand and work with.
Here’s a quick look at how the contents of an SRT file are organized:
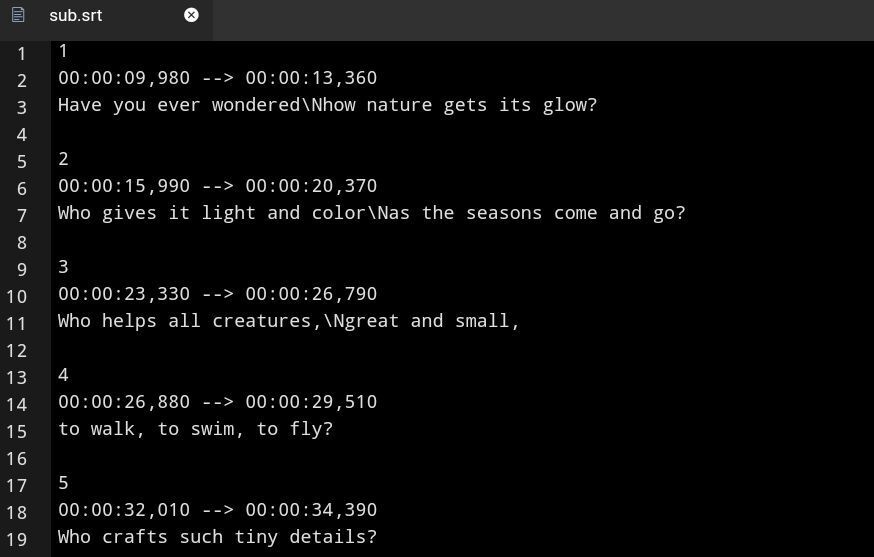
The contents are organized into blocks, each separated by an empty line. From the image, we can see that a block is split into three basic components: an integer index, a time frame string, and a caption.
1. Index:
Every block begins with an integer index. The index is an identifier that represents the ordinal importance or position of the block within the file, meaning that a block with an index of ‘1’ would be the first to have its caption shown on screen.
2. Time frame:
On the second line is where we’ll find the time frame. It’s split into two timestamps representing the start and end of the time frame, with a forward arrow (-->) separating them. The start timestamp is the time during playback when a block’s caption would appear on screen, while the end timestamp specifies when the caption will be taken off the screen. A timestamp is formatted as:
hours:minutes:milliseconds
e.g.: 00:03:23,050
When the milliseconds is in the thousands, the thousands part is separated from the hundreds with a comma (,).
Then the time frame is given as:
start timestamp --> end timestamp
e.g.: 00:03:23,050 --> 00:03:25,960
A block with this time frame will have its caption appear on screen when playback gets to 3 minutes, 23,050 milliseconds until 3 minutes, 25,960 milliseconds when it will be taken off the screen.
3. Caption:
The third line contains the text we typically see on screen. Normally, there’s just three lines to a block, but when the caption is lengthy it could be split into multiple lines, then anything from the third line onward would be a part of the caption until a block terminator is reached.
Block terminator
The empty lines separating each block make it easier to tell where one ends and where another begins. This is called a block terminator, and it indicates the end of a block. Each block has to be separated by a block terminator, otherwise it wouldn’t be a proper SRT file.
Thinking about what we want to do
What we’re really interested in is the time frame component in each block. We want to locate a block’s time frame, and modify it so the caption for that block appears at the same time as the corresponding audio for it. But the thing is, desynchronization occurs in two ways: fixed offset and non-fixed offset.
First, imagine a subtitle synced with audio looks like this:
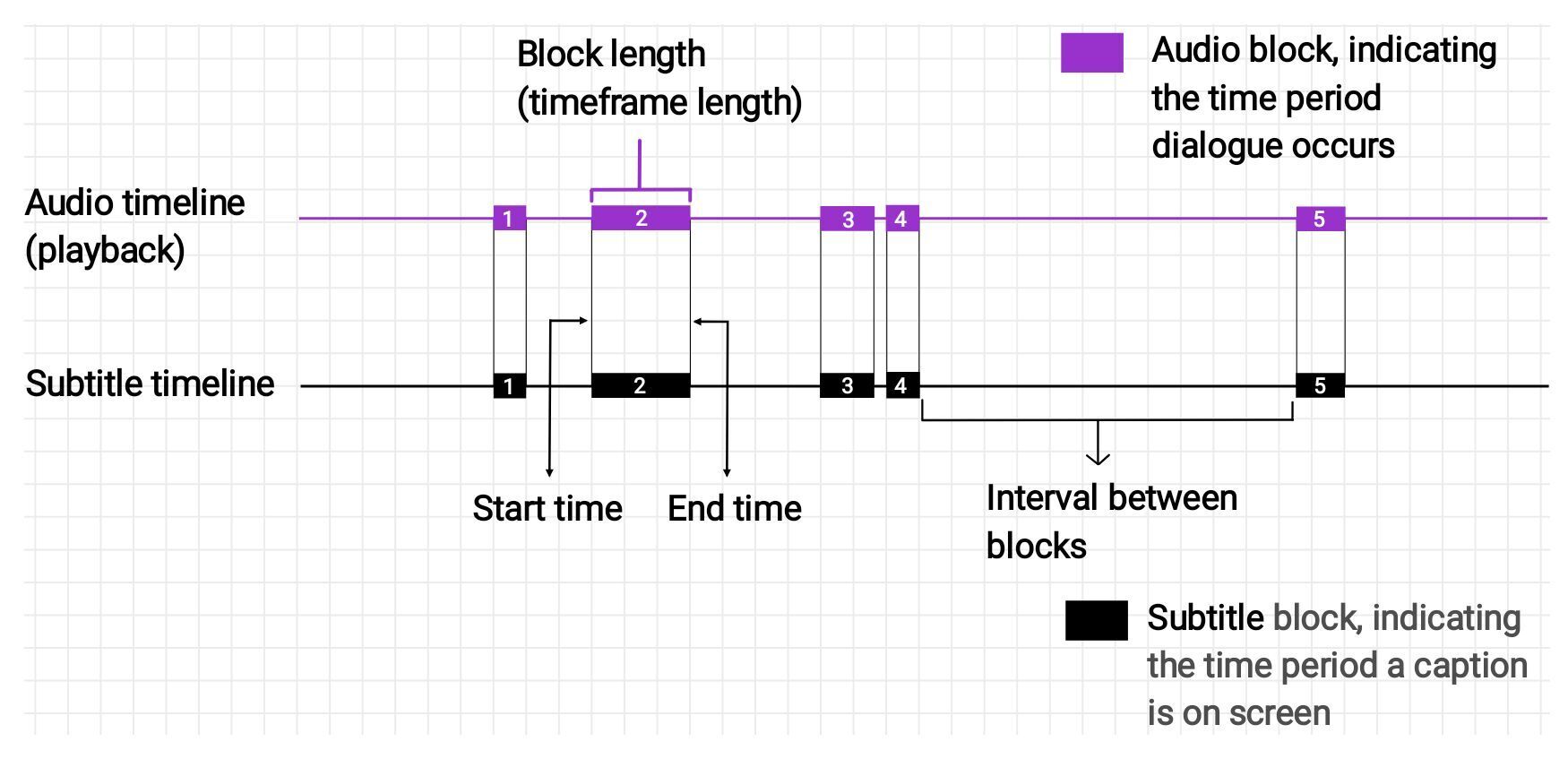
Comparing both timelines, we’ll easily see that the block lengths are similar and are placed on corresponding points, meaning audio and subtitle captions meet at the same points during playback.
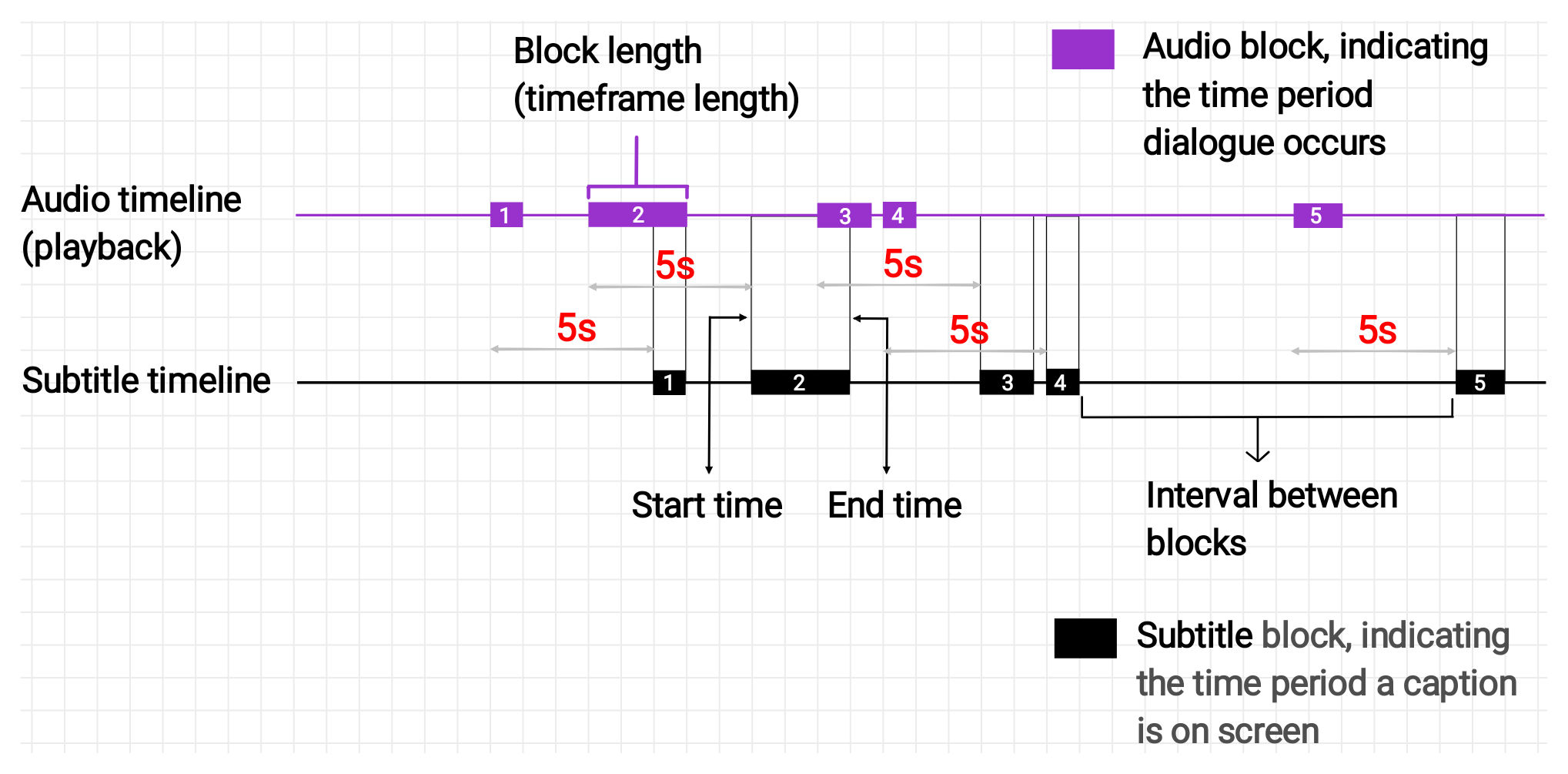
- Fixed offset: The subtitle timing is off by a fixed amount throughout playback. A fixed offset problem will look like the below:
Case (a): Captions appear a fixed distance later than their dialogue.
Case (b): Captions appear a fixed distance earlier than their dialogue.
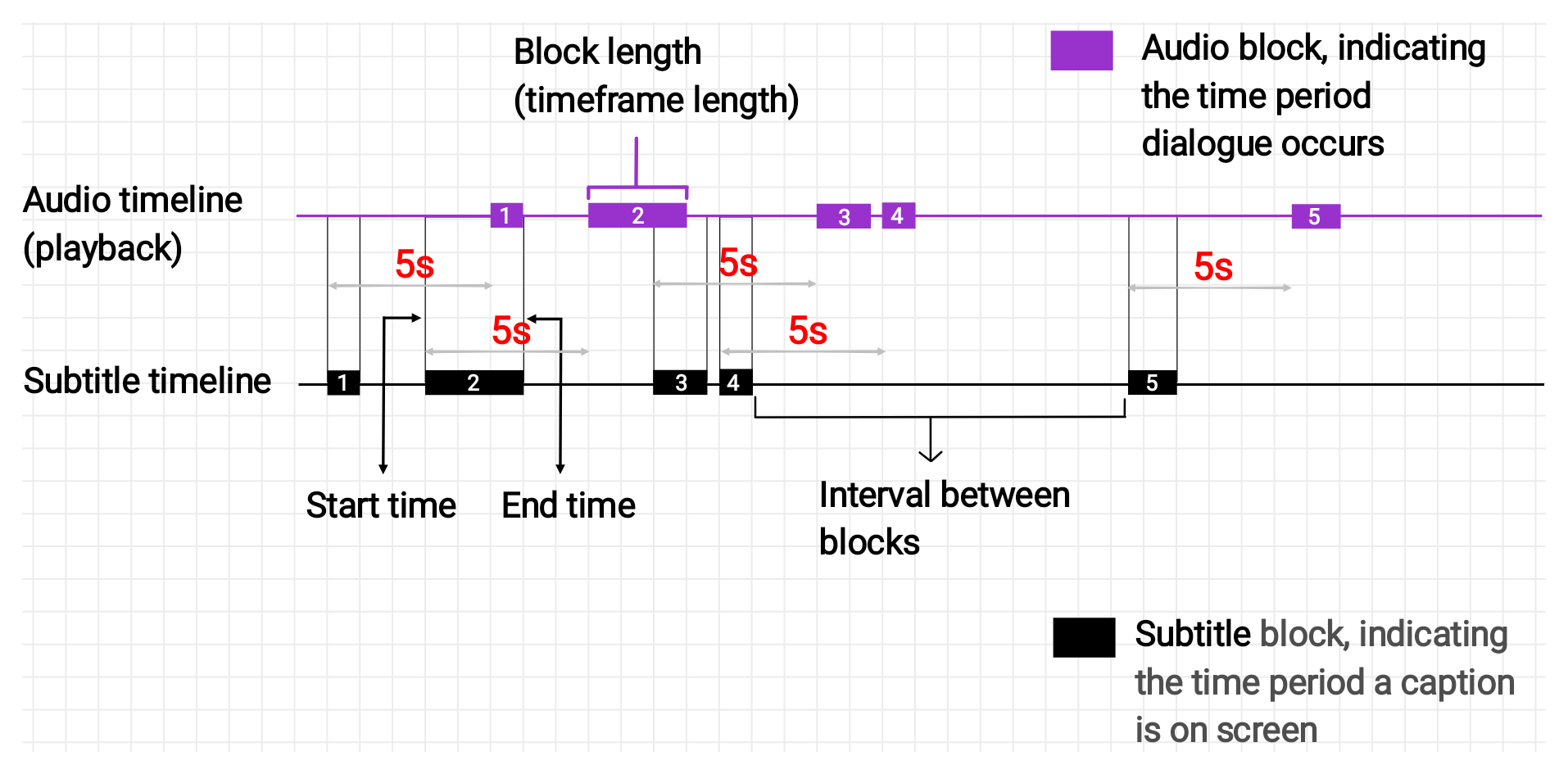
In a fixed offset problem, the subtitle time frames match the audio time frames in length, but not in playback position. There’s a fixed amount of time lag between where each block is on the subtitle timeline and where it would need to be in playback to be synced with audio.
To sync, we’ll need to shift the start and end timestamps of each block on the subtitle timeline by the fixed amount. Shifting only the start or only the end would cause the time frame to grow or shrink instead of move.
In case (a), we’d have to subtract 5 seconds from the start and end timestamps of each block’s time frame to effectively move the whole timeline 5 seconds backwards. For case (b) we’d do the same but perform an addition instead. That’s the kind of problem we’re going to fix.
- Non-fixed offset: The subtitle timing is off by a non-fixed amount throughout playback. It would look like the below:
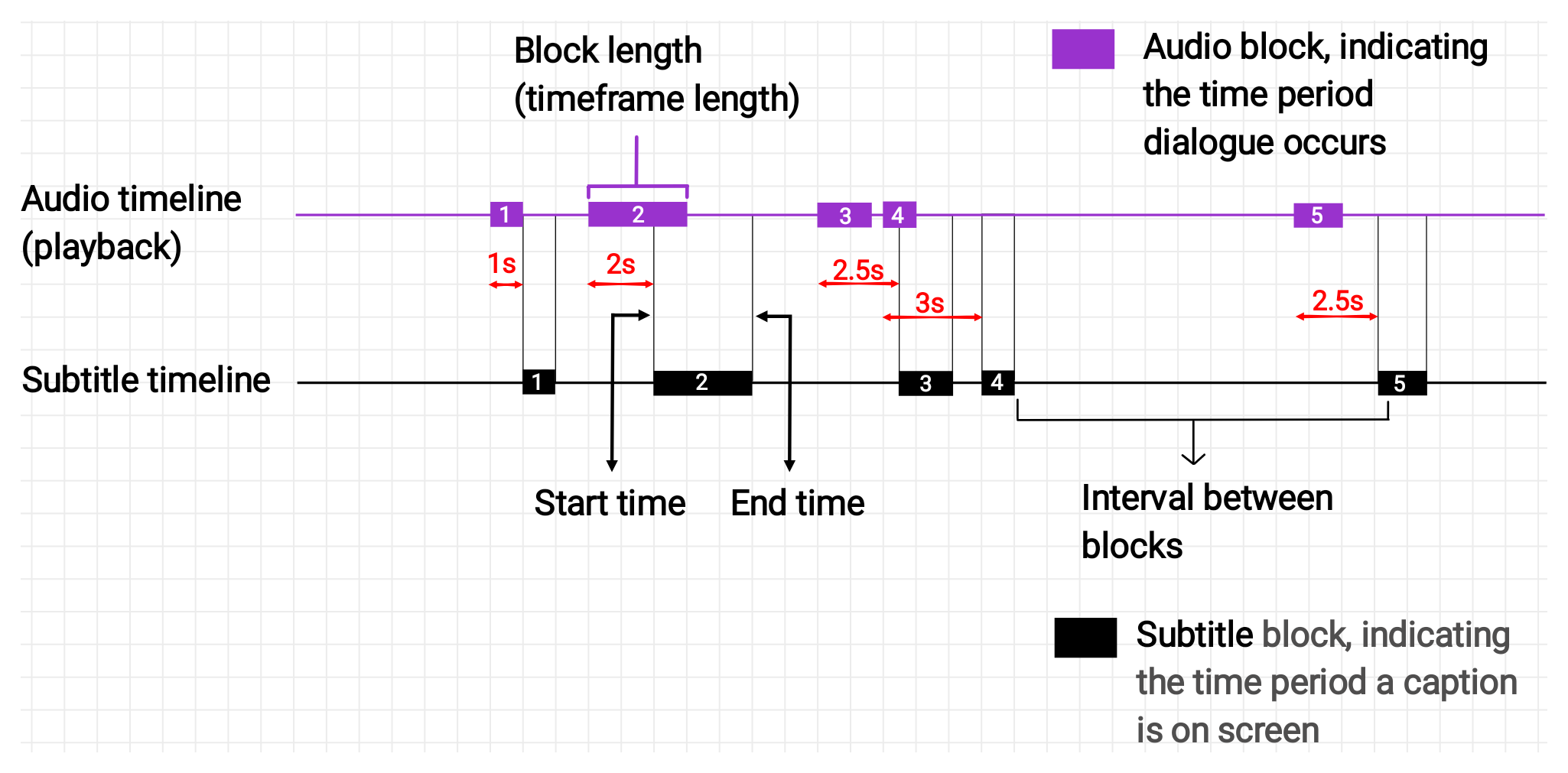
On the subtitle timeline, the first block is 1 second away from sync, the second is 2 seconds away, and the third is 2.5 seconds away. There’s no fixed offset, and If you look closely, particularly at blocks 1–2 and 3–4, you’ll see that the intervals between the blocks on the subtitle timeline do not perfectly correspond to the ones on the audio.
We can’t sync the timeline with the audio using a fixed offset, because it doesn’t apply here.
There are other ways a non-fixed offset problem could look like (e.g., differences in time frame length for corresponding blocks on both timelines), but we’re not focused on that. Usually, the kind of synchronization problems you’d run into are fixed-offset.
The core algorithm
We’re set on solving fixed-offset desynchronization, so how do we do it? First, we’ll need to make an educated guess about the offset value. When watching a video, we can do this by closely looking at when the captions appear and when words are spoken. The algorithm will only handle applying the offset to the time frames.
A broad description of what we want to do is:
1. Open an existing subtitle file for reading.
2. Create a new file to store the synced subtitle.
3. Find a block within the subtitle file:
- Locate the time frame(start and end timestamp strings) within the block.
- Convert the start and end timestamps from string format to representations in milliseconds, so we’ll have a start milliseconds and an end milliseconds.
- Adjust the start and end milliseconds by adding the offset value, which is given in milliseconds. The offset can either be positive(forward adjustment) or negative(backward adjustment).
- Convert the adjusted start and end milliseconds back into timestamp strings, and join both strings to form an adjusted time frame.
- Write the contents of the block, including the adjusted time frame, into the output file created in step (2).
4. Repeat step (3) until the end of the subtitle file.
The main tasks within the algorithm
Much of what we’ll be doing is in step 3, so let’s take a closer look at some parts that’ll make implementation easier later on.
1. Locating a block:
As we’ve seen, the first line in any block within an SRT file is an integer index, so as soon as we can successfully find a line containing an integer, we know we’ve found a block. The time frame is located just on the next line.
2. Converting a timestamp from string format to milliseconds:
We’ll need to write a simple parser for this task. We know a timestamp is in the format hours:minutes:milliseconds. All we have to do is split the timestamp into integer parts representing the hours, minutes, and milliseconds components, then convert the hours and minutes into their representation in milliseconds using math. The milliseconds component of the timestamp is already in milliseconds, so there’d be no need to modify it. Afterwards, we’d sum up the results.
For example, the timestamp 00:03:23,050 reads as 0 hours, 3 minutes, and 23,050 milliseconds. There’s 3,600,000 milliseconds in an hour, and 60,000 milliseconds in a minute, so the hours and minutes can be converted to milliseconds this way:
hours as milliseconds = hours × 3,600,000ms
= 0hrs × 3,600,000ms
= 0ms
minutes as milliseconds = minutes × 60,000ms
= 3mins × 60,000ms
= 180,000ms
total milliseconds = hours as milliseconds + minutes as milliseconds + the portion already in milliseconds
= 0ms + 180,000ms + 23,050ms
= 203,050ms
3. Converting milliseconds to timestamp string:
We’ll write another parser. Here, we’ll need to determine the exact amount of hours, minutes, and milliseconds that make up the given total milliseconds altogether and, for this, we’ll need something called “integer division”. It’s a mathematical division where the fractional part of a quotient is completely discarded, as we only use the integral (whole number) part.
This is how we’ll do it:
total milliseconds = 203,050 (from earlier)
1. Getting the hours:
hours = total milliseconds / 3,600,000ms
hours = 203,050ms/3,600,000ms
= 0hrs* (This will be the timestamp’s hours).
2. Getting the minutes:
Step 1: Subtract the number of hours(as milliseconds) from the total milliseconds to get the remainder time:
hours as milliseconds = 0ms (from earlier)
remainder = total milliseconds – hours as milliseconds
= 203,050ms – 0ms
= 203,050ms
Step 2: Calculate the number of minutes within the remainder time:
remainder = 203,050ms
minutes = remainder / 60,000ms
minutes = 203,050ms / 60,000ms
= 3mins* (This will be the timestamp’s minutes).
3. Getting the milliseconds:
Subtract the number of minutes(as milliseconds) from the remainder time to get the remaining milliseconds:
minutes as milliseconds = 180,000ms (from earlier)
milliseconds = remainder – minutes as milliseconds
= 203,050ms – 180,000ms
= 23,050ms (This will be the timestamp’s milliseconds).
Putting it all together in timestamp format we have:
00:03:23,050
*The fractional parts were discarded from the hours and minutes.
Conclusion
Now, we know all we need to and are ready to implement the solution in C#, based on what we’ve established here. Even if you’re not familiar with C#, don’t worry. Before diving into any code, we’ll get to see the structure behind it, and even see the pseudocode for the core algorithm. It should help you out in translating it to the programming language of your choice.
Thanks for reading!
Originally posted here on Medium.