Banner image courtesy: Tudip Digital
Getting Started
LocalStack is a cloud service emulator that runs in a single container on your laptop or in your CI environment. With LocalStack, you can run your AWS applications or Lambdas entirely on your local machine without connecting to a remote cloud provider.
Installation
In this tutorial, we will install LocalStack CLI on our x86-64 Linux machine, for ARM64 kindly check the official documentation. The CLI starts and manages the LocalStack Docker container.
# Download the pre-built binary
curl --output localstack-cli-4.2.0-linux-amd64-onefile.tar.gz \
--location https://github.com/localstack/localstack-cli/releases/download/v4.2.0/localstack-cli-4.2.0-linux-amd64-onefile.tar.gz
# Extract the LocalStack CLI from the terminal
sudo tar xvzf localstack-cli-4.2.0-linux-*-onefile.tar.gz -C /usr/local/bin
# Verify installed version
localstack --version
4.2.0Configuring and Starting LocalStack
We need an API key from LocalStack to configure LocalStack on our local machine. Head over to LocalStack and signup. Within your LocalStack dashboard, go to WorkSpace → Auth Tokens and copy the personal auth token provided. This personal auth token will be used to activate the LocalStack pro hobby subscription which grants use access to all of LocalStack’s features such as the Resource Browser which will use in this tutorial. Now add the auth token to your local stack CLI and start LocalStack:
localstack auth set-token
# By default, LocalStack runs on port 4566. Make sure no service is running on this port otherwise LocalStack won't start
localstack start
__ _______ __ __
/ / ____ _________ _/ / ___// /_____ ______/ /__
/ / / __ \/ ___/ __ `/ /\__ \/ __/ __ `/ ___/ //_/
/ /___/ /_/ / /__/ /_/ / /___/ / /_/ /_/ / /__/ ,<
/_____/\____/\___/\__,_/_//____/\__/\__,_/\___/_/|_|
- LocalStack CLI: 4.2.0
- Profile: default
- App: https://app.localstack.cloud
[12:31:41] starting LocalStack in Docker mode 🐳 localstack.py:512
2025-03-27T12:31:41.282 INFO --- [ MainThread] l.p.c.b.licensingv2 : Successfully activated cached license :hobby from /home/user/.cache/localstack-cli/license.json 🔑✅
──────────────────────────────────── LocalStack Runtime Log (press CTRL-C to quit) ─────────────────────────────────────
LocalStack version: 4.2.1.dev87
LocalStack build date: 2025-03-26
LocalStack build git hash: c6fc9b010
2025-03-27T09:31:48.092 INFO --- [ MainThread] l.p.c.b.licensingv2 : Successfully activated cached license :hobby from /etc/localstack/conf.d/license.json 🔑✅
2025-03-27T09:31:52.329 INFO --- [ MainThread] l.p.c.extensions.platform : loaded 0 extensions
Ready.Installing AWS CLI and LocalStack’s AWS CLI
We now need to have both the AWS official CLI and LocalStack’s AWS CLI which is a thin wrapper of the AWS official CLI for LocalStack.
# Verify installation of the official AWS CLI
aws --version
aws-cli/2.25.4 Python/3.12.9 Linux/5.15.167.4-microsoft-standard-WSL2 exe/x86_64.ubuntu.24
# Install LocalStack's AWS CLI
pip install awscli-local
awslocal --version
aws-cli/2.25.4 Python/3.12.9 Linux/5.15.167.4-microsoft-standard-WSL2 exe/x86_64.ubuntu.24Creating S3 Storage Bucket in LocalStack
Before syncing the buckets, we need to create an S3 storage bucket within LocalStack in our local machine:
# Create bucket
awslocal s3api create-bucket \
--acl public-read \
--bucket test-s3-bucket \
--object-ownership BucketOwnerPreferred \
--region us-east-2 \
--create-bucket-configuration '{"LocationConstraint": "us-east-2"}'
# Sample output with bucket name set to test-s3-bucket
{
"Location": "http://test-s3-bucket.s3.localhost.localstack.cloud:4566/"
}Syncing S3 Storage Buckets
In this tutorial, we will focus on two keys methods for syncing our AWS S3 storage bucket with our LocalStack S3 storage bucket within our local machine.
Method 1: Sequential sync
The sequential sync approach is whereby we sync the bucket to a local temp folder in our local machine then sync our LocalStack S3 storage bucket with data in the local temp folder.
# Syncing bucket data to local temp folder
aws s3 sync s3:// ./local-folder --region
# Syncing local folder to LocalStack S3 bucket
aws s3 sync ./local-folder s3:// --endpoint-url http://localhost:4566
# Verify upload
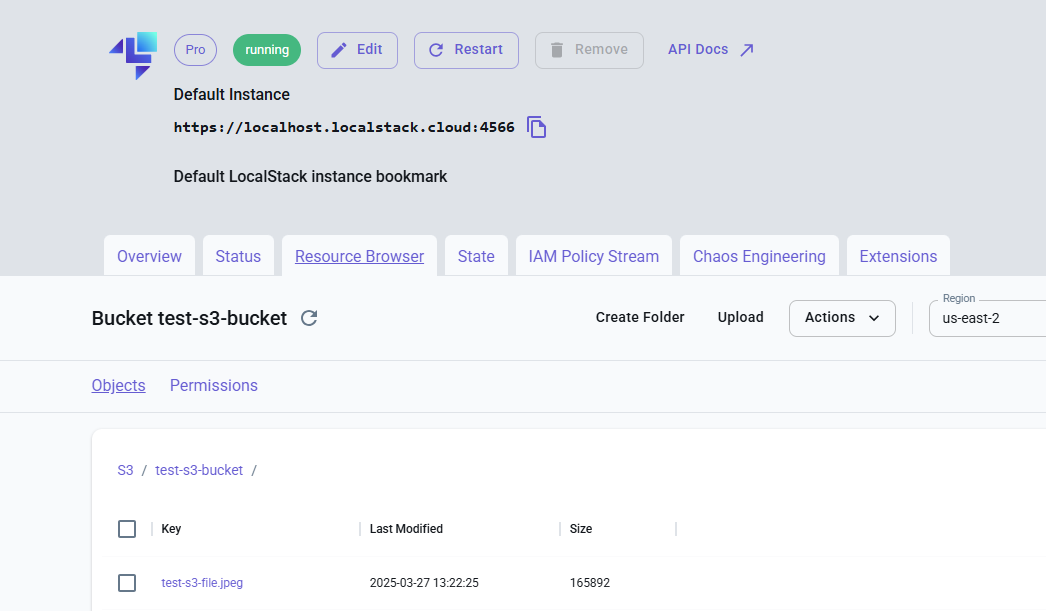
awslocal s3 ls s3://test-s3-bucket
2025-03-27 13:04:21 165892 test-s3-file.jpegMethod 2: Direct Sync (Without Local Storage)
The direct sync approach avoids syncing the bucket data to local storage first but rather syncs the bucket data directly to the LocalStack S3 storage bucket. In this tutorial, we will use a bash script to sync the buckets. You can create a python script and use boto3 and LocalStack’s python client to sync the buckets.
aws s3 ls s3:// --recursive | awk '{print $4}' | \
xargs -P 10 -I {} sh -c 'aws s3 cp --debug "s3:///{}" - | awslocal s3 cp - "s3:///{}" --debug'
# Sample output in terminal running localstack
2025-03-27T10:12:24.654 INFO --- [et.reactor-0] localstack.request.aws : AWS s3.PutObject => 200
2025-03-27T10:12:27.443 INFO --- [et.reactor-0] localstack.request.aws : AWS s3.PutObject => 200
2025-03-27T10:12:37.219 INFO --- [et.reactor-0] localstack.request.aws : AWS s3.PutObject => 200
2025-03-27T10:12:41.503 INFO --- [et.reactor-0] localstack.request.aws : AWS s3.PutObject => 200
2025-03-27T10:12:45.346 INFO --- [et.reactor-0] localstack.request.aws : AWS s3.PutObject => 200After the upload is complete, you can head to your LocalStack dashboard navigate to local instances, go to resource browser, search for S3, choose bucket and browse your files or folders in your bucket.
Conclusion
The local storage first approach is more performant as compared to the direct approach since the direct approach relies on xargs to achieve parallel transfers using sub-processes. One can spawn multiple separate sub processes using xargs -P N when N is the number of sub processes required. The sub process parallelism is great for S3 sync as this is an I/O bound task. In terms of speed, using xargs even with tuned parallelism can be slow. If you are looking to speed up syncs, you can use tools such as s5cmd which supports true multithreading. I will sure do a tutorial on s5cmd and do a benchmark to check how it compares to using xargs in parallel mode. The approach in this tutorial was not created with the context of large S3 storage buckets. If you have a tutorial on this please share. Thanks again for reaching to the end of this tutorial. Cheers!