Getting Started with TARDIS: A Friendly Guide for New Contributors
Have you ever looked up at the night sky and wondered how we decode the light from exploding stars? That’s exactly what TARDIS helps scientists do. In this post, we’ll explore what TARDIS is, how it works, and how you, as a future contributor, can become part of this open-source project.

TL;DR:
In this blog, I share my journey exploring and contributing to TARDIS-SN and CARSUS, open-source astrophysics tools used to simulate supernova spectra. I explain how TARDIS works in simple layman language, how Carsus supports it by generating atomic data, and detail my first contribution to Carsus through a pre-GSoC pull request. I also reflect on my GSoC interview experience where I excelled in behavioral questions but miserably failed with technical ones yet how it motivated me to keep learning and growing. This post is both a technical guide and a personal story for future contributors.
+ The storytelling will be written in this format or in quotes.
- If you want to skip my journey and focus only on technicals
+ feel free to do so.
+ However, I humbly request you read through all of it.🌌 What Is TARDIS?
TARDIS (Temperature And Radiative Diffusion In Supernovae) is an open-source Python-based radiative transfer code designed to simulate supernova spectra. Its primary aim is to provide a fast, flexible tool for researchers studying the light emitted by supernovae (stellar explosions).
Think of it as a virtual lab where you can recreate and analyze how a supernova would shine through space based on the physics of radiation, matter, and atomic interactions.
TARDIS : An open-science software to simulate and analyse supernovae and other transients
While exploring potential GSoC projects, I initially shortlisted exciting options like OHC and Google DeepMind. However, when I stumbled upon TARDIS, my childhood dream of diving into the mysteries of space and the cosmos reignited. As a Sci-Fi enthusiast, I felt an irresistible pull towards this project, convincing me that this is where I truly belong, channeling my passion for starry adventures into meaningful work.
I have mentioned this in my proposal as well.

Lets get back to some core concepts.
Core Concepts
Here are a few core concepts that TARDIS is built upon:
- Radiative Transfer guides the journey of light through cosmic chaos.
- The Monte Carlo Method harnesses the power of randomness to unravel these stellar explosions.
- Atomic Data the blueprint for understanding the interactions between photons and atoms.
Together, these concepts help us decode the celestial light show that reaches our telescopes. Lets understand them in detail.
🔁 Radiative Transfer
What is it?
Radiative transfer is the physical process that describes how light (or more generally, radiation) travels through a medium like the gas ejected from a supernova interacting with particles along the way.
Why it matters:
When a supernova explodes, it releases an enormous amount of energy in the form of photons. These photons travel through layers of hot, expanding gases, where they can be:
- Absorbed by atoms (which raises them to an excited state),
- Re-emitted at different energies (wavelengths),
- Scattered in different directions.
Understanding these interactions is key to interpreting what we see in a telescope. By simulating radiative transfer, we can recreate what a supernova’s light would look like from Earth and match it against real observations.
🎲 Monte Carlo Method
What is it?
The Monte Carlo method is a computational technique that uses random sampling to simulate complex processes. In TARDIS, it’s used to model the behavior of photon packets.
How TARDIS uses it:
- Imagine a huge number of photon packets being released from the core of a supernova.
- Each packet moves through the ejecta (outer layers of the star), and at each step, a random decision determines whether it’s absorbed, scattered, or continues on its path.
- These decisions are based on probabilities derived from physical laws and atomic data.
By simulating the paths of millions of these packets, TARDIS builds a statistical picture of the emerging spectrum—what an observer would see. It’s a powerful and efficient way to model the highly random, chaotic nature of radiative processes in space.
⚛️ Atomic Data
What is it?
Atomic data includes fundamental information about atoms and ions, such as:
- Ionization energies : How much energy it takes to remove an electron.
- Energy levels : The specific energies electrons can have.
- Transition probabilities : How likely it is for an electron to jump from one level to another.
- Spectral lines : The wavelengths of light emitted or absorbed when these transitions happen.
Why it’s crucial:
Without accurate atomic data, TARDIS wouldn’t know how photons should behave when they encounter different atoms in the supernova ejecta. Carsus plays a vital role here by compiling, cleaning, and formatting this data so TARDIS can use it.
This data lets TARDIS:
- Predict which colors of light will be emitted or absorbed.
- Simulate spectral lines that appear in real telescope observations.
- Help astronomers identify the chemical composition of the supernova.
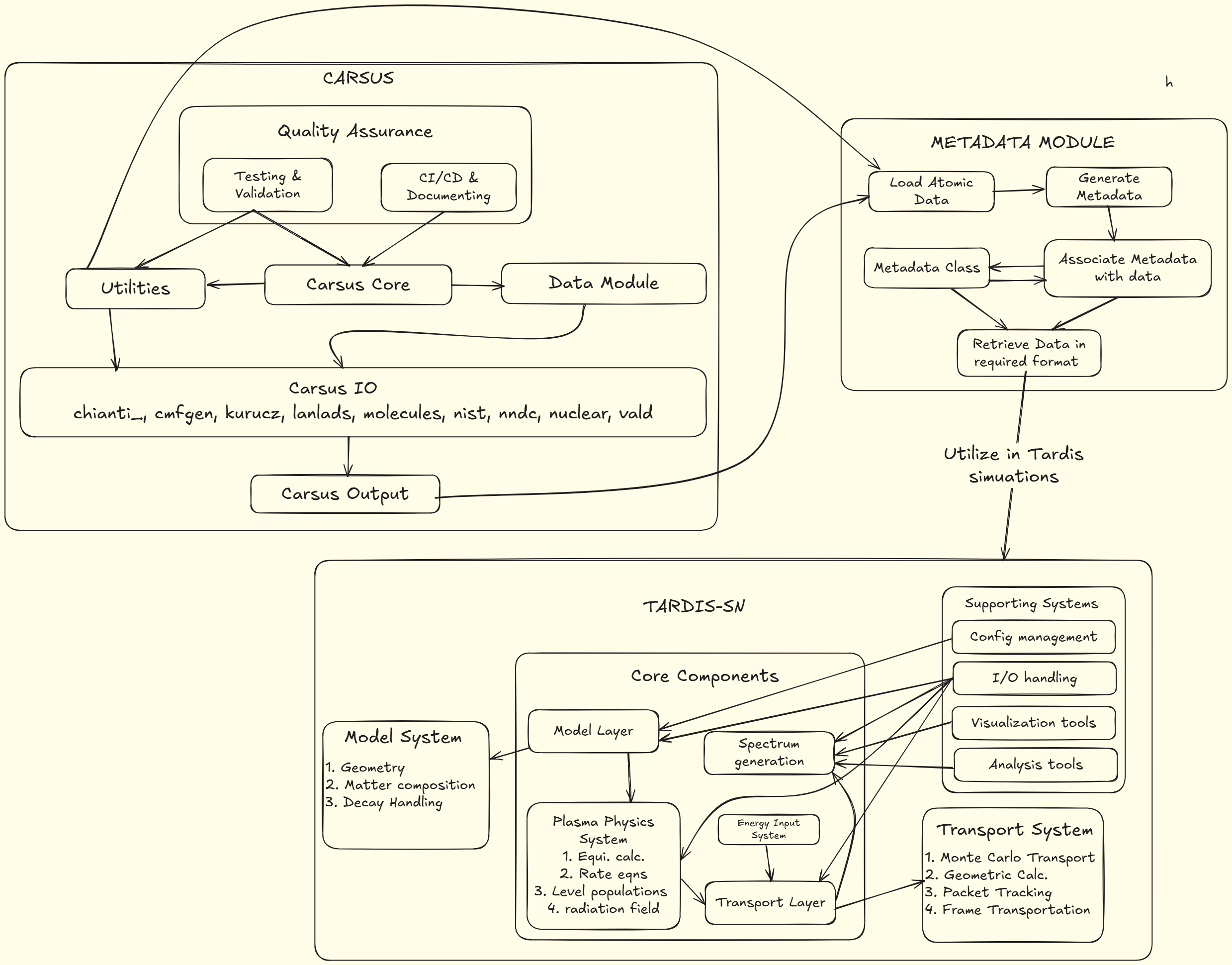
TARDIS-SN Architecture
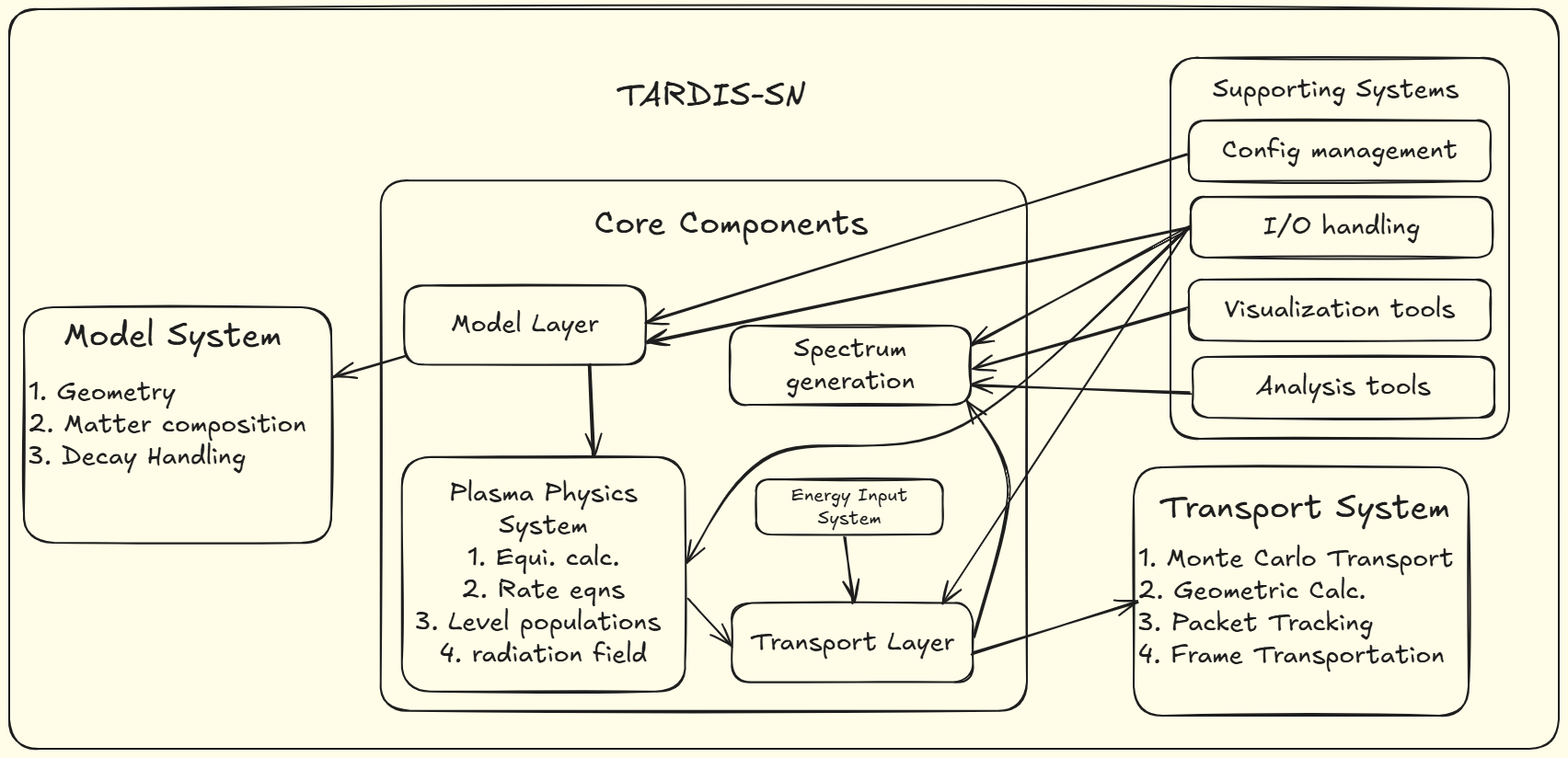
This architectural diagram has been generated using GitDiagram and reflects my current understanding and interpretation. For authoritative information, reference to official documentation or direct consultation with project maintainers is recommended.
Key Components and their Interactions:
Model System: Defines the basic attributes of the supernova environment, including geometry, matter composition, and decay handling.
Plasma Physics System: Focuses on detailed plasma calculations such as equilibrium calculations, rate equations, level populations, and radiation field characterization.
Transport System: Utilizes the Monte Carlo method to simulate how photons travel through the supernova's ejecta, performing geometric calculations, packet tracking, and frame transportation.
Core Components:
- Model Layer: Integrates data from the Model System and Plasma Physics System, guiding the simulation process.
- Transport Layer: Handles photon transport based on inputs from the Plasma Physics System.
- Spectrum Generation: Converts simulated photon interactions into observable spectra.
- Supporting Systems: Provide essential utilities for efficient simulation, including configuration management, input/output handling, visualization, and analysis tools.
🧩 Modular Design
TARDIS is neatly divided into modules:
-
simulation: Coordinates the overall simulation. -
plasma: Manages physical states like ionization and temperature. -
transport: Handles Monte Carlo radiative transport. -
io: Reads and validates configuration and atomic data. -
spectrum: Produces and stores the final synthetic spectrum. -
visualization: Offers helpful plots and interactive widgets.
Each module is independently testable and designed for plug & play enhancements, making it ideal for contributors.
🛠 How TARDIS Works -> A Simple Workflow
Here’s a high-level overview of what happens when TARDIS runs:
1️⃣ Input Setup:
Users prepare a YAML configuration file describing the supernova model: density, composition, time since explosion, etc.
TARDIS also uses external atomic data provided in HDF5 format.
HDF5 (Hierarchical Data Format version 5) is a file format and set of tools designed for managing complex data. It allows you to store large amounts of numerical data and metadata in a single, highly organized file that's both scalable and efficient. HDF5 supports a variety of data types and is ideal for handling large datasets, making it widely used in fields like scientific research, engineering, and data analysis. Key features include support for multidimensional arrays, efficient storage and retrieval, data compression, and the ability to store metadata alongside the data.
2️⃣ Initialization:
The model grid (usually 1D spherical shells) and plasma conditions are set up.
Photon packets are initialized with starting positions and directions.
3️⃣ Monte Carlo Simulation:
These packets are tracked as they interact with the matter: being absorbed, re-emitted, or scattered.
This process continues until the packet escapes the system or its energy is fully absorbed.
4️⃣ Spectrum Generation:
The emergent photon packets are collected to form a synthetic spectrum.
This output can then be compared with actual observations.
5️⃣ Output & Analysis:
Users can analyze the generated spectra, convergence behavior, and plasma states.
TARDIS provides utilities for visualization and diagnostic plots
▶️ A small Demo for TARDIS
Installation
1) Install Miniconda (if not already installed):
Download from https://docs.conda.io/en/latest/miniconda.html and follow the installation instructions for your operating system.
2) Create a new conda environment:
conda create -n tardis-env python=3.10
conda activate tardis-env3) Install TARDIS:
pip install tardis-snNote: For the latest development version or to contribute, consider cloning the repository from GitHub: https://github.com/tardis-sn/tardis
Running a Basic Simulation
1) Download a sample configuration file:
wget https://raw.githubusercontent.com/tardis-sn/tardis/master/tardis/io/configuration/tests/data/tardis_configv1.yml2) Run the simulation:
tardis tardis_configv1.ymlThis command will process the configuration and generate a synthetic spectrum based on the provided parameters.
3) Visualize the output:
After the simulation completes, you can visualize the generated spectrum using Python:
import matplotlib.pyplot as plt
from tardis.io.output import read_spectrum
spectrum = read_spectrum('tardis_configv1.yml')
plt.plot(spectrum.wavelength, spectrum.luminosity_density_lambda)
plt.xlabel('Wavelength (Angstrom)')
plt.ylabel('Luminosity Density')
plt.title('Synthetic Spectrum')
plt.show()Ensure you have
matplotlibinstalled in your environment. If not, install it usingpip install matplotlib.
📚 Learn More
For detailed guidance on customizing simulations, understanding configuration parameters, and exploring advanced features, refer to the official TARDIS documentation: https://tardis-sn.github.io/
✨ Do give it a star: TARDIS-SN ⭐
CARSUS: The Atomic Data Engine Behind TARDIS
If TARDIS is the telescope through which we view supernovae, Carsus is the database behind the lens.
🧾 What Is Carsus?
Carsus is a Python package designed to process, standardize, and output atomic data for use in radiative transfer simulations, especially those run by TARDIS. It is a package to manage atomic datasets. It can read data from a variety of sources and output them to file formats readable by radiative transfer codes.
It acts as the bridge between raw atomic datasets (from databases like NIST, Kurucz, Chianti, CMFGEN, etc.) and the HDF5-formatted atomic files that TARDIS understands.
🔍 Why Is It Important?
Supernova simulations require precise atomic data: energy levels, line transitions, ionization potentials, and more. These values affect how light moves through supernova ejecta, and therefore, how accurately we can model spectra.
Carsus ensures:
- ♻️ Consistency across data sources,
- ⚙️ Customizability for research needs,
- 💾 Output in HDF5 format for TARDIS,
- 📚 Provenance and reproducibility with citation tracking and version control.
CARSUS Architecture
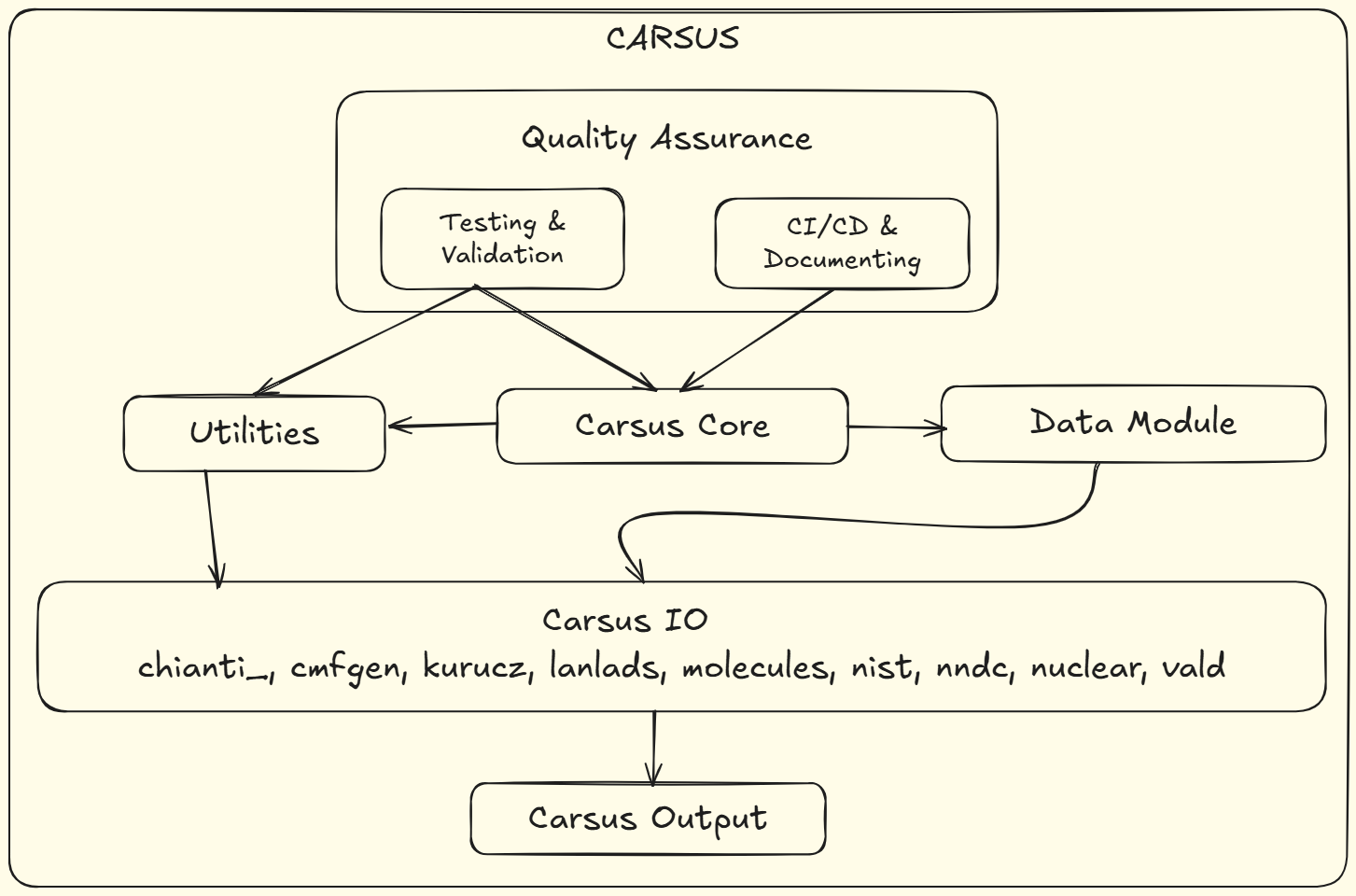
Key Components:
- Carsus Core: The central component that orchestrates data processing, ensuring seamless interaction between utilities and the data module.
- Data Module: Responsible for accessing and organizing atomic data from various sources, such as chianti, Kurucz, NIST, and others.
- Utilities: Provides auxiliary functions that aid in data manipulation and processing, integrating closely with the Carsus Core.
- Carsus IO: Handles input/output operations, facilitating the conversion of raw data from multiple repositories into a usable form.
- CARSUS Architecture: Ensures data reliability through testing and validation, along with continuous integration, continuous deployment (CI/CD), and documentation processes.
How Carsus Works —> A Simplified Workflow
1) Data Parsing:
- Carsus supports multiple databases (e.g., NIST, Kurucz, CMFGEN, Chianti).
- Parsers in
carsus/io/read raw data and convert it into Pandas DataFrames.
2) Data Transformation:
- Values are cleaned, standardized, and sometimes enhanced (e.g., adding weights, correcting formats).
- Intermediate DataFrames are managed with clear units and structure.
3) Output Generation:
- The cleaned and unified data is exported into HDF5 files using
carsus.io.output. - These files include levels, lines, ionization energies, collisions, macro-atom data, and more.
- Integration with TARDIS:
- Once the data is exported, TARDIS can load these files to run radiative transfer simulations.
🗂 Carsus Codebase
-
io: Home to all input/output parsers (e.g.chianti_,kurucz,nist,vald,cmfgen). -
io/output: Generates final HDF5 datasets. -
data: Contains test and default input data. -
util: Helper functions for logging, hashing, unit management, and more. -
tests: Ensures reliability via pytest-based unit tests.
✨ Do give it a star: CARSUS ⭐
Note: I haven’t explored the STARDIS module yet, but if I do in the future, I’ll be sure to update this blog with my insights.
My Pre-GSoC Contribution
The Problem statement / Idea
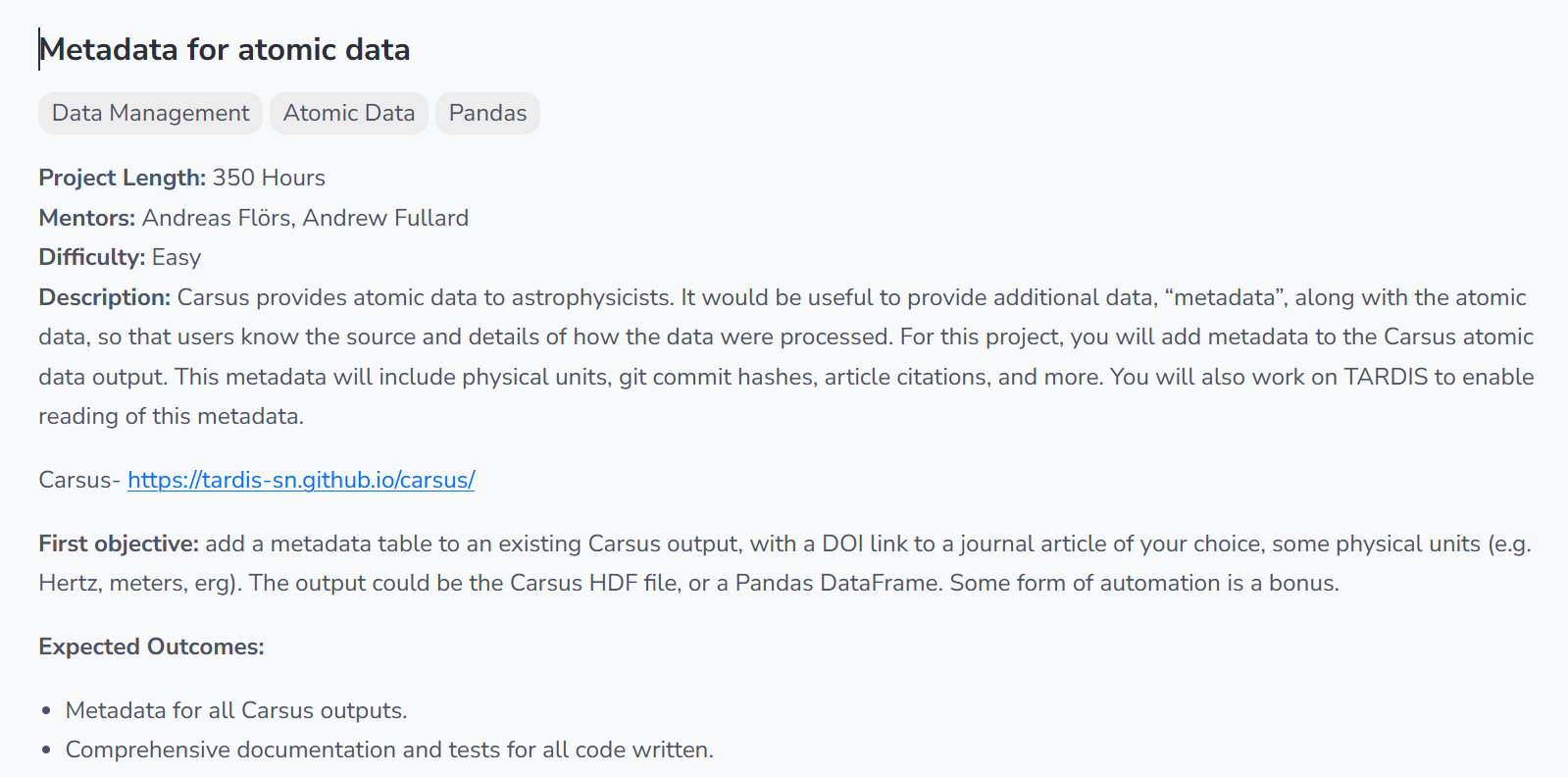
The Solution
How I approached the problem
1) Understanding the Data Structure: Delving into the HDF5 atomic data files to comprehend how ionization energies are stored and accessed.
2) Function Implementation: Writing the functions required to perform the tasks.

3) Testing and Validation: Ensuring the function's reliability through unit tests and comparing results with known values.
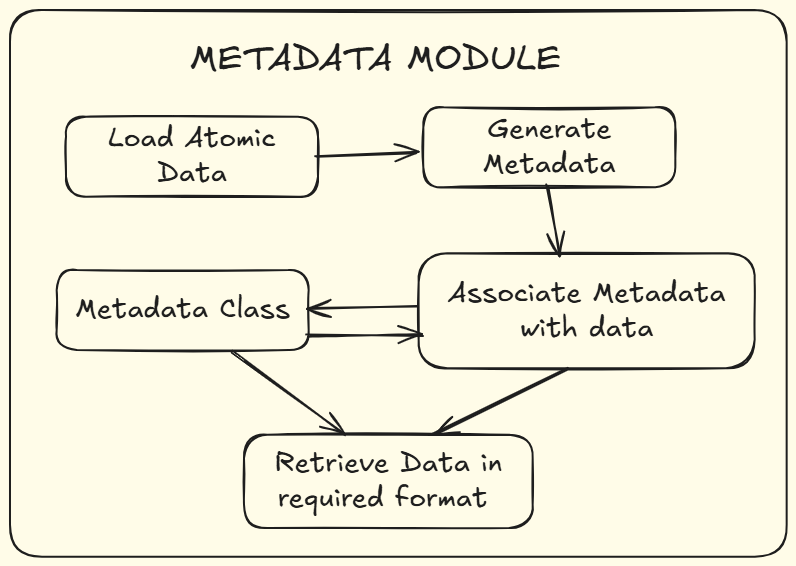
 [GSOC]-Metadata for atomic data
#442
[GSOC]-Metadata for atomic data
#442
Type: 🚀 feature
Implements metadata support for Carsus atomic data outputs as specified in the first project objective:
-
Metadata Table
- New
MetadataHandlerclass stores:- Physical units (validated via Astropy, e.g.,
"angstrom","Hz") - Journal article references (DOIs, manual entry)
- Git commit hashes (automated when run in a repository)
- Physical units (validated via Astropy, e.g.,
- New
-
Output Formats
-
HDF5: Metadata stored in
/metadatagroup (units, references, git info) -
Pandas DataFrame: Metadata accessible via
read_hdf_with_metadata()
-
HDF5: Metadata stored in
-
Automation (Bonus)
- Git commit hash auto-detection
- Unit validation (rejects invalid units like
"not_a_unit")
from carsus.io import save_to_hdf, MetadataHandler
# Initialize with manual metadata
handler = MetadataHandler(data_source="NIST")
handler.add_units("wavelength", "angstrom") # Physical unit
handler.add_reference(
doi="10.1051/0004-6361/201526937", # Journal article DOI
description="NIST Atomic Spectra Database"
)
# Save to HDF5 (or use with Pandas)
save_to_hdf(
df=atomic_data,
path="output.h5",
metadata_handler=handler
)
Unit Tests: pytest tests/test_metadata.py (100% coverage)

Manual Verification:
- Confirmed HDF5 metadata structure with h5ls
- Validated unit enforcement
- Verified reference persistence
- [x] Requested reviewers: @AndreasFlörs @AndrewFullard
- [x] I updated the documentation according to my changes
- [x] Added comprehensive docstrings
Note: If you are not allowed to perform any of these actions, ping (@) a contributor.
In March, I embarked on an exciting journey by raising a PR and eagerly seeking feedback on Gitter. Determined to make a mark, I tried tackling additional issues and launched into crafting my GSoC proposal. With the proposal being a pivotal factor for selection, I devoted more than 25 hours over several days to ensure it was robust and compelling.

My confidence surged when I received the delightful news that I was shortlisted for an interview.
But my excitement quickly turned to disappointment; although I aced the behavioral questions, I stumbled over the technical ones even those that were straightforward.
The technical questions included:
- What library is used to interact with HDF5 files?
- What is an HDF5 file?
- What is a subprocess in Python?
- What are class methods in Python?
- Which functions are used to read, write, and perform other operations on HDF5 files?
The behavioral inquiries were such as:
- What would you do if you believe there's a better solution to a problem than the one suggested by the maintainer?
- How do you approach fixing bugs and errors?
- How would you handle a situation where differing opinions within the team lead to conflict?
After the interview, I felt disheartened and spent the entire day grappling with the thought that I could have performed better. I should have focused more on strengthening my Python skills instead of solely diving deep into the codebase. My advice: don't repeat this mistake. The next day, surrounded by thoughts of wasted effort and missed opportunities, clarity struck
What was the true purpose? It wasn't just about GSoC; the true aim was to contribute to something meaningful, impactful, and genuinely valuable.
This realization lifted my spirits, and I decided to pen this blog post, hoping future contributors won't make the same mistakes.
If you're working on the Carsus metadata component, I'd be happy to share my proposal with you. Regardless of the outcome of the GSoC results, my commitment remains strong as I will continue to contribute in the true spirit of open source. And with renewed focus and determination, I'm confident that I will succeed in next year's selection.
I'm always open to lending a hand, whether you have questions, need guidance, or just want to chat about your own experiences. Feel free to reach out to me with any inquiries or requests for assistance as you navigate your own path within the open-source community. Together, we can learn, grow, and make meaningful contributions. I look forward to hearing from you!