In a recent blog post, I explored statistics in PostgreSQL, with a focus on how the database engine builds histogram bounds during the ANALYZE process. These histograms are critical for query planning and optimization, as they give the planner a way to estimate data distributions across columns.
One part of the post demonstrated how to generate a skewed distribution and inspect the resulting histogram bounds using the pg_stats view. Here's the original setup:
create table t(n)
with (autovacuum_enabled = off)
as select generate_series(1, i)
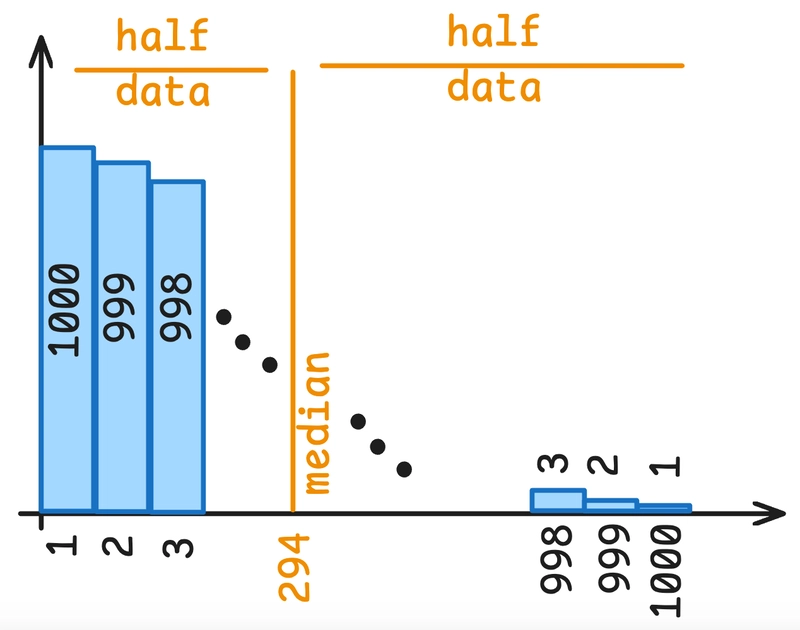
from generate_series(1, 1000) as i;This creates a table with 500,500 rows, where 1 is repeated 1000 times, 2 is repeated 999 times, and so on, until 1000 which is repeated only once. This distribution is shown in the following diagram:
The blog post also demonstrates the concept of histogram bounds in Postgres, which can be observed after analyzing the table:
analyze t;
select
histogram_bounds::text::int[] as histogram_bounds
from pg_stats
where tablename = 't';The output is based on a random sampling of the table, so your mileage may vary:
5, 18, 32, 40, 54, 68, 80, 100, 110, 119, 125, 136, 144, 149,
154, 160, 165, 171, 178, 182, 189, 195, 202, 211, 216, 222,
227, 234, 239, 245, 250, 256, 261, 268, 273, 278, 283, 289,
295, 301 307, 314, 320, 325, 332, 339, 346, 352, 358, 364,
370, 376, 383, 389, 396, 402, 409, 415, 422, 429 436, 443,
450, 458, 466, 473, 481, 489, 496, 503, 511, 519, 527, 536,
545, 555, 564, 573, 583, 593 603, 613, 623, 633, 645, 657,
668, 680, 693, 706, 721, 734, 749, 765, 783, 802, 824, 846,
873, 910, 994The expectation is that the histogram would reflect this skewed distribution, assigning more histogram buckets to regions with higher data density.
Reader Observation: Histogram Does Not Match Intuition
Chris Jones, a reader of the blog, made a sharp observation:
In your out of
histogram_boundsfor table t above, it shows that there are 7 buckets for values 0-100, and 17 buckets for 200-300, even though we know that there are more records with values in the 0-100 range. I got similar bounds when I ran the same example. I tried with lots of different statistics_target values and always got the same. It seems like this histogram implies a distribution that is not correct.
Let's demonstrate his point with actually drawing the bucket distribution for the histogram bounds (using this Python script):
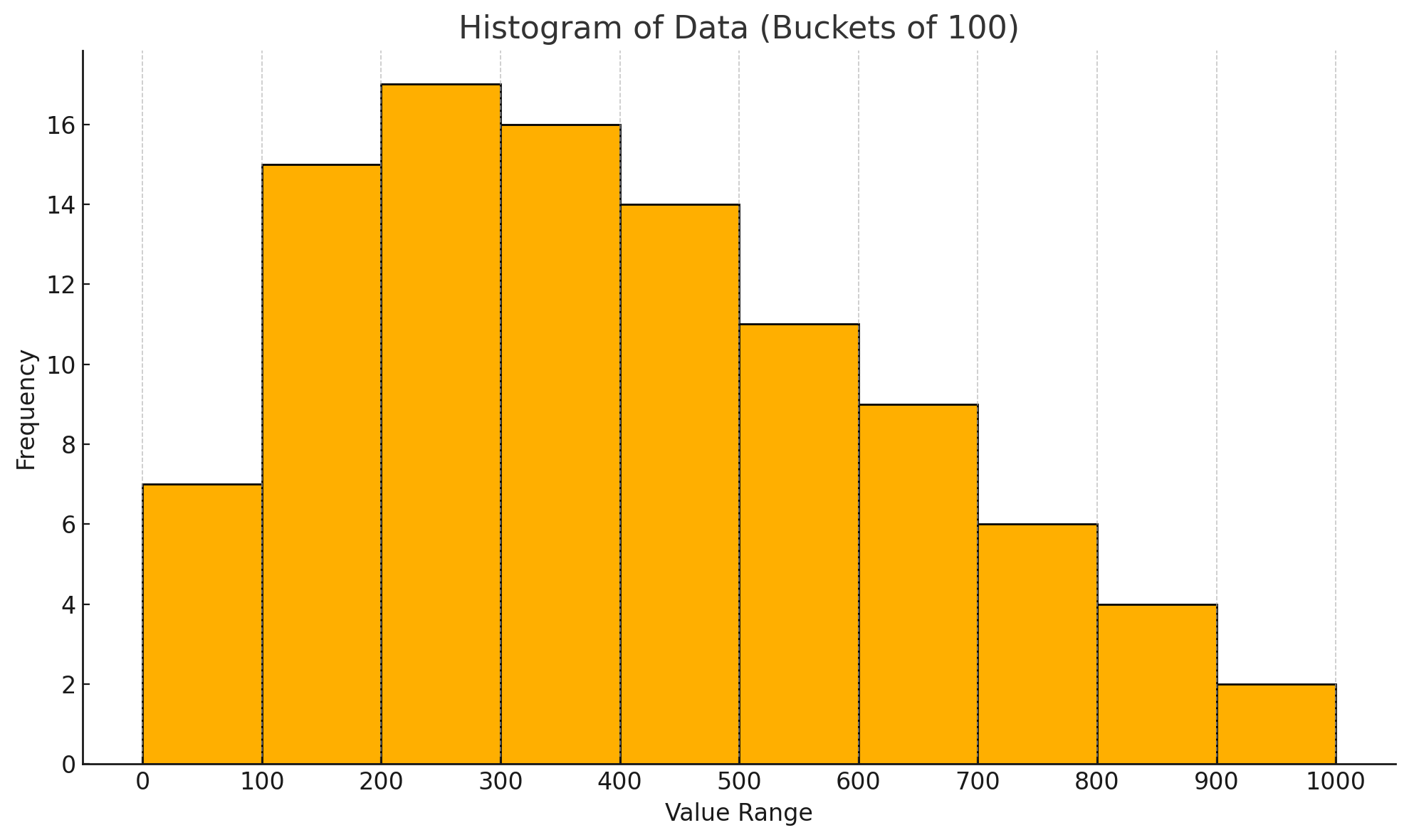
This is an important point. If histogram bounds are used for cardinality estimation, shouldn't denser regions have finer granularity?
Digging Deeper: Why Is the Histogram Counterintuitive?
To understand this, I looked at the PostgreSQL source code. Specifically, this comment in analyze.c explains part of the logic:
/*
* Generate a histogram slot entry if there are at least two distinct
* values not accounted for in the MCV list. (This ensures the
* histogram won't collapse to empty or a singleton.)
*/This suggests that histogram bounds are only created when:
- The bucket contains at least two distinct elements;
- The values are not in the MCV (most common values) list.
In the above distribution, high-frequency values like 1 and 2 have a higher chance of being in the MCV list than low-frequency values like 900.
Verifying the Hypothesis
To test this explanation, I modified the data by adding a small random offset to each value. This ensures that every value is unique (or nearly unique), avoiding the issue of MCV elimination during histogram generation.
drop table if exists t;
create table t(n)
with (autovacuum_enabled = off)
as select generate_series(1, i) + random() / 1000.0
from generate_series(1, 1000) as i;
analyze t;
select
histogram_bounds::text::float[] as histogram_bounds
from pg_stats
where tablename = 't';With this change, the histogram bounds now behave as expected: the 0–100 range contains many more histogram boundaries than the 100–200 and 200–300 ranges. This better reflects the actual density of the data.
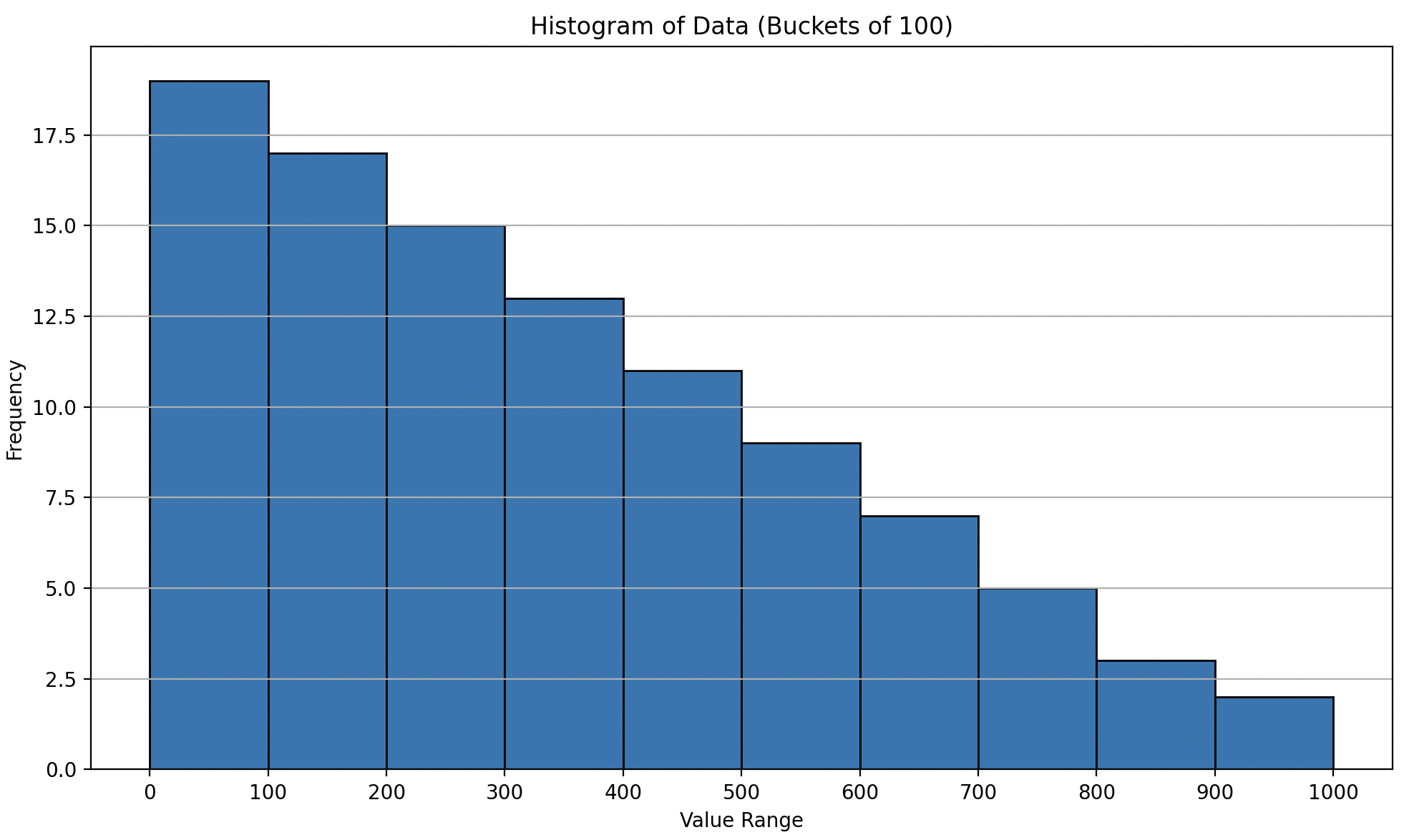
Conclusion
PostgreSQL's histogram statistics do account for data distribution, but the internal logic excludes MCV values when selecting histogram boundaries. As Rober Haas put it, "histogram is intended to be a histogram of non-MCVs".
Thanks to Chris Jones for the sharp observation that triggered a deeper dive into how PostgreSQL builds histograms, and to Rober Haas for commenting on the blog with the above useful insight on PostgreSQL Hacking Discord.

