
Introduction: The New Era of AI Operations
The AI landscape has evolved dramatically with the rise of large language models (LLMs), retrieval-augmented generation (RAG), and multimodal AI systems. Traditional MLOps frameworks struggle to handle:
- Billion-parameter LLMs with unique serving requirements
- Vector databases that power semantic search
- GPU resource management for cost-effective scaling
- Prompt engineering workflows that require version control
- Embedding pipelines that process millions of documents
In this article I will be providing a blueprint on different development tools for different components of building an AI/MLOps infrastructure capable which supports the recent advanced AI applications.
Core Components of AI-Focused MLOps
- LLM Lifecycle Management
- Vector Database & Embedding Infrastructure
- GPU Resource Management
- Prompt Engineering Workflows
- API Services for AI Models
1. LLM Lifecycle Management
a) Tooling Stack:
- Model Hubs: Hugging Face, Replicate
- Fine-tuning: Axolotl, Unsloth, TRL
- Serving: vLLM, Text Generation Inference (TGI)
- Orchestration: LangChain, LlamaIndex
b) Key Considerations:
- Version control for adapter weights (LoRA/QLoRA)
- A/B testing frameworks for model variants
- GPU quota management across teams

2. Vector Database & Embedding Infrastructure
Database Choice
- Pinecone
- Weaviate
- Milvus
- PGVector
- QDrant
Embedding Pipeline Best Practices:
- Chunk documents with overlap (512-1024 tokens)
- Batch process with SentenceTransformers
- Monitor embedding drift with Evidently AI
3. GPU Resource Management
Deployment Patterns:
| Approach | Use Case | Tools |
|---|---|---|
| Dedicated Hosts | Stable workloads | NVIDIA DGX |
| Kubernetes | Dynamic scaling | K8s Device Plugins |
| Serverless | Bursty traffic | Modal, Banana |
| Spot Instances | Cost-sensitive | AWS EC2 Spot |
Optimization Techniques:
- Quantization (GPTQ, AWQ)
- Continuous batching (vLLM)
- FlashAttention for memory efficiency
4. Prompt Engineering Workflows
MLOps Integration:
- Version prompts alongside models (Weights & Biases)
- Test prompts with Ragas evaluation framework
- Implement canary deployments for prompt changes

5. API Services for AI Models
Production Patterns:
| Framework | Latency | Best For |
|---|---|---|
| FastAPI | <50ms | Python services |
| Triton | <10ms | Multi-framework |
| BentoML | Medium | Model packaging |
| Ray Serve | Scalable | Distributed workloads |
Essential Features:
- Automatic scaling
- Request batching
- Token-based rate limiting
End-to-End Reference Architecture
Below will be the whole infrastructure diagram for an AIOps Infrastructure, feel free to take a pause to go over as it could be overwhelming :)
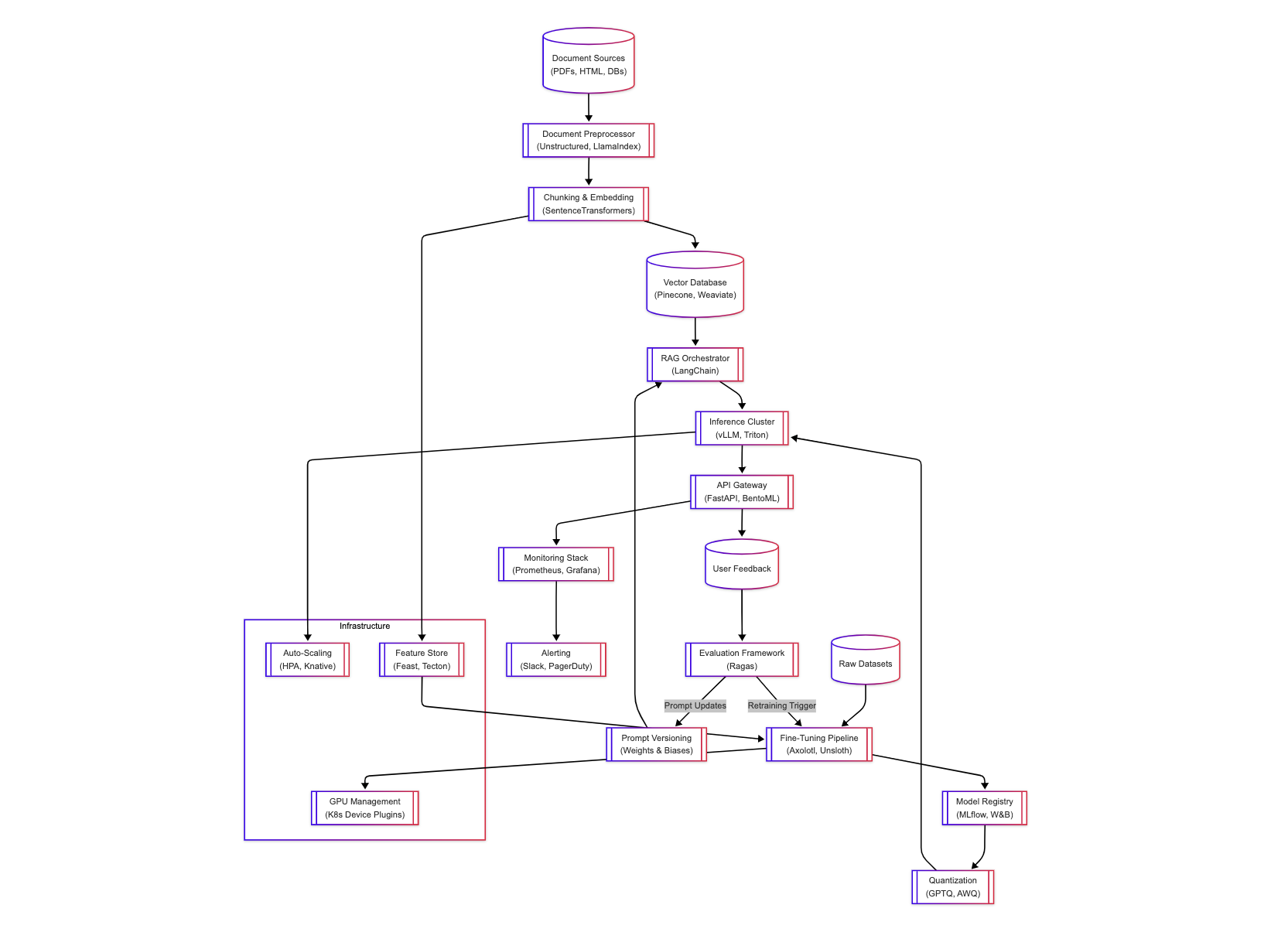
Final Takeaways
Quick lessons for production,
- Separate compute planes for training vs inference
- Implement GPU-aware autoscaling
- Treat prompts as production artifacts
- Monitor both accuracy and infrastructure metrics
This infrastructure approach enables organizations to deploy AI applications that are:
- Scalable (handle 100x traffic spikes)
- Cost-effective (optimize GPU utilization)
- Maintainable (full lifecycle tracking)
- Observable (end-to-end monitoring)
References for Further Learning
- Hugging Face Production Guide
- LoRA Fine-Tuning Tutorial
- MLOps Community Resources
- PgVector vs PineCone
- LlamaIndex RAG Best Practices
- vLLM
- NVIDIA TensorRT-LLM Tutorial
- Prometheus for ML Monitoring
Thanks for reading— I hope this guide helps you tackle those late-night MLOps fires with a bit more confidence. If you’ve battled AI infrastructure quirks at your own, I’d love to hear your war your solutions! :)
