The Challenge:
How do we query data from DynamoDB, process it with SQL-like queries, and visualize it in QuickSight—all while keeping the solution scalable and cost-efficient?
Solution:
This serverless solution leverages Lambda for DynamoDB extraction, S3 for spill storage, Athena+Glue for SQL processing, and QuickSight for scalable visualizations—all without managing infrastructure.
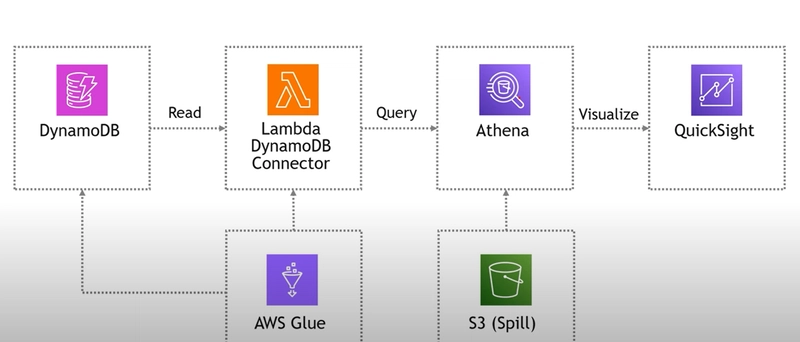
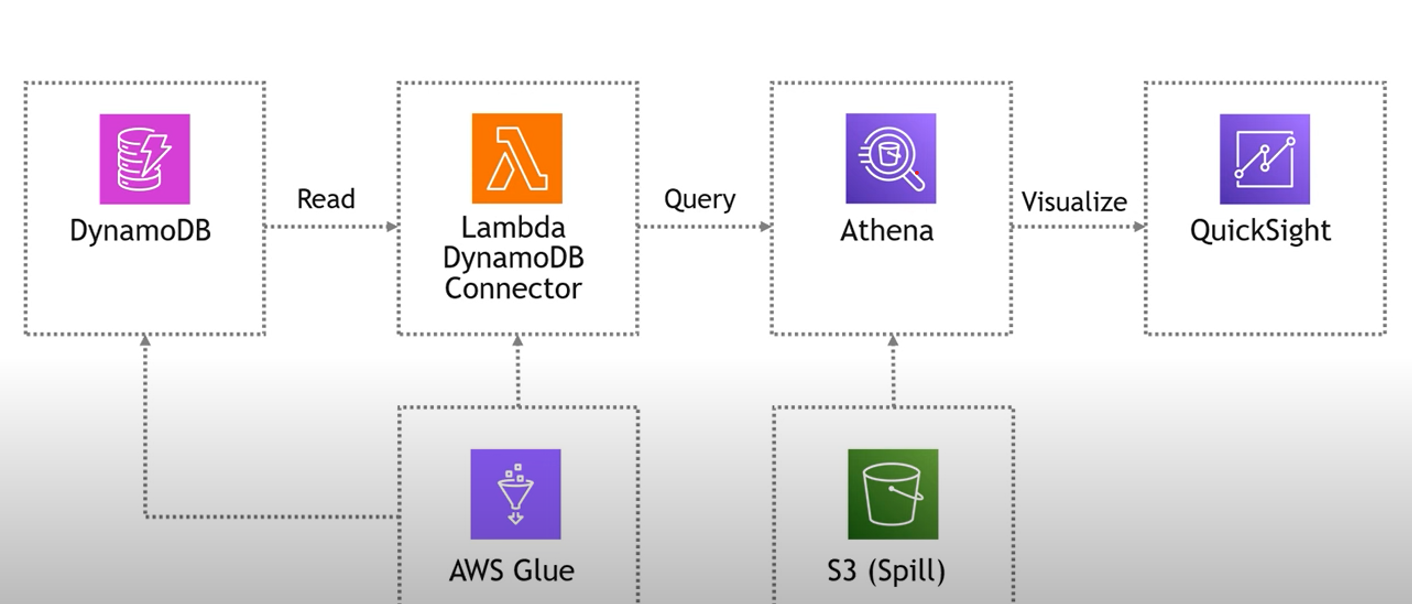
Architecture:
Create a quicksight account:
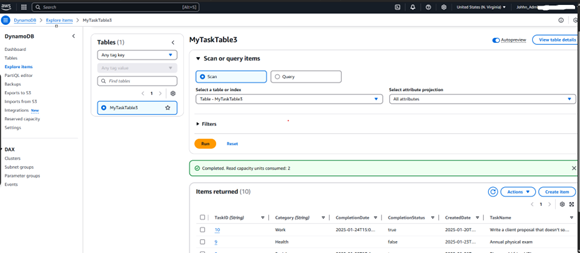
Setting Up DynamoDB:
• Created a DynamoDB table with partition and sort keys.
• Insert sample data in JSON format.
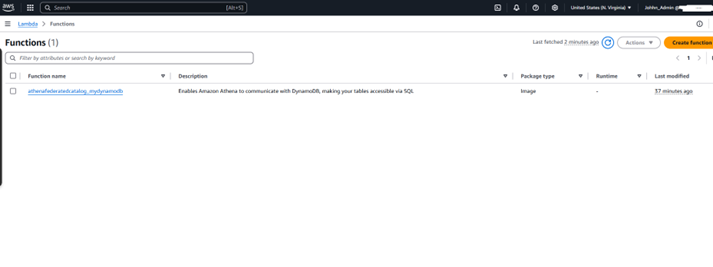
Configuring Lambda as a Data Connector:
• Set up an AWS Lambda function to query DynamoDB and return data in Athena-compatible format.
• Set up IAM roles to allow Lambda to read from DynamoDB and write to S3.
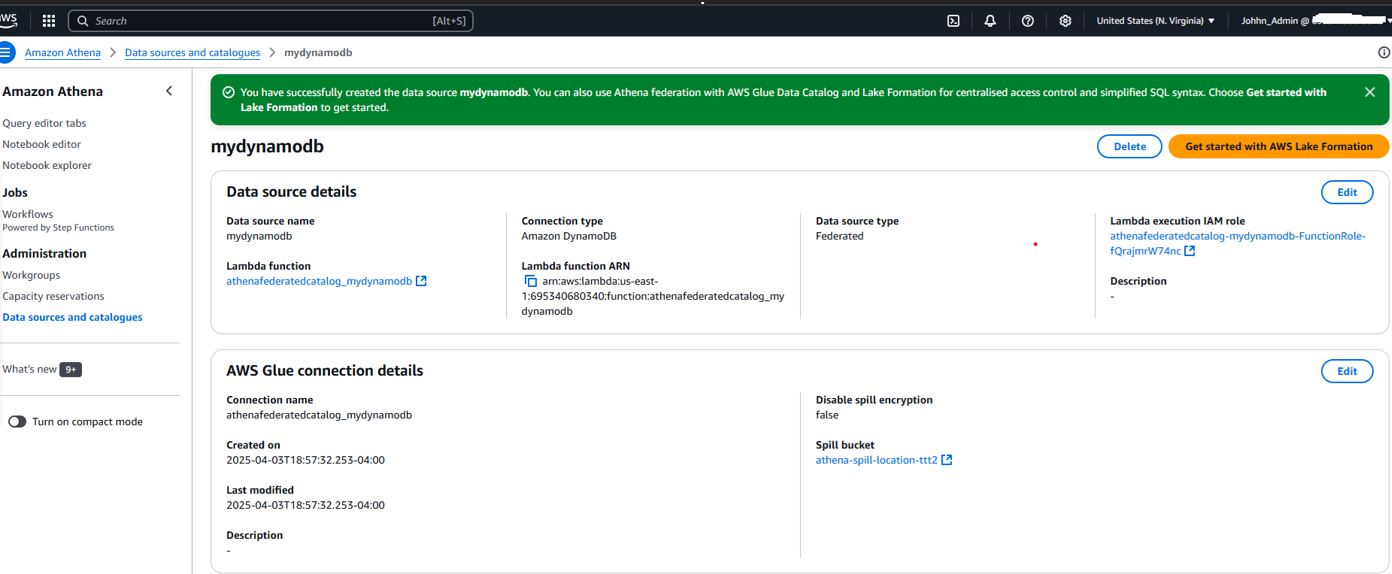
Querying Data in Athena:
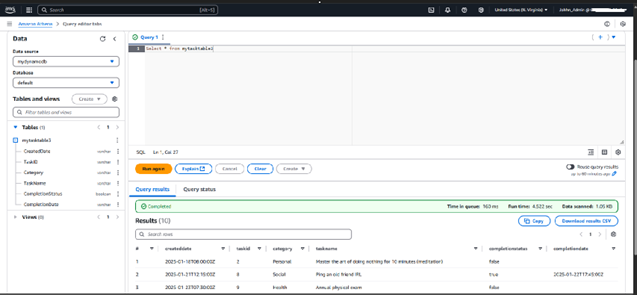
• Executed Athena SQL queries to filter and process data.
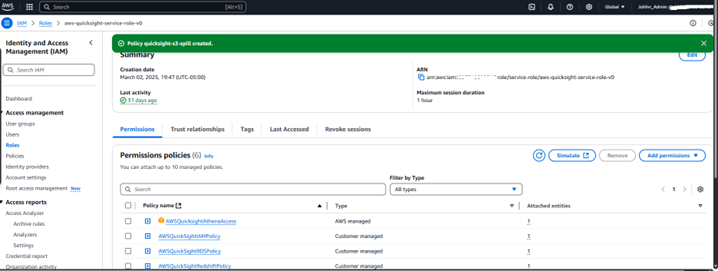
IAM Role Configuration for QuickSight:
• Granted QuickSight permissions to invoke Lambda and read from S3.
• Updated IAM role policies for secure access.
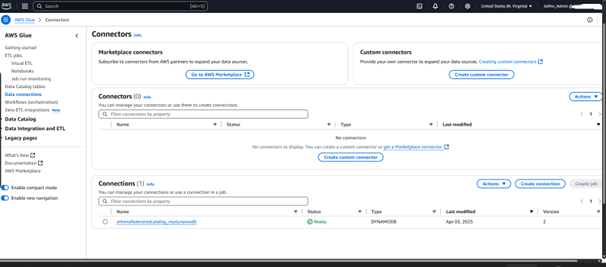
Glue’s background setup:
Lambda extracts DynamoDB data to S3, with Glue automatically managing schema metadata for Athena querying.
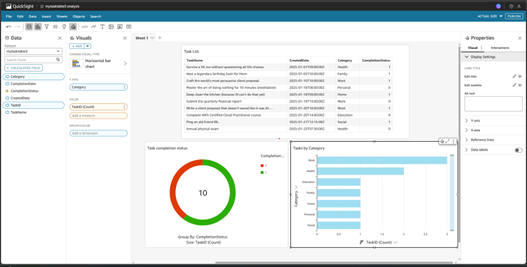
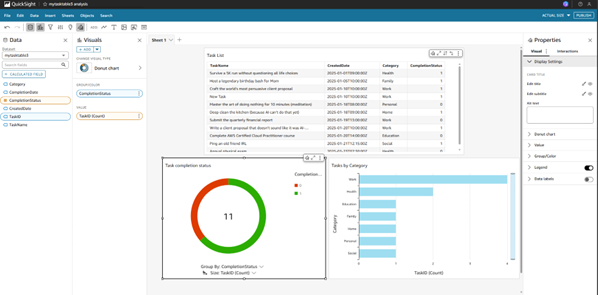
Building Interactive QuickSight Dashboards:
• Created donut charts, bar charts, and tables to visualize task completion status.
• Enabled live data updates from DynamoDB → Athena → QuickSight.
Summary: From DynamoDB to dashboards in minutes
- Lambda transforms streams
- S3 stores efficiently
- Athena queries via Glue
- QuickSight visualizes All serverless. All cost-optimized