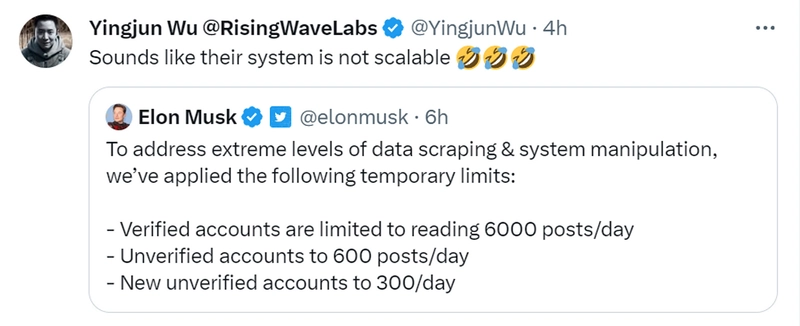
Elon Musk announced to put a strict cap on the number of tweets users can read each day. Specifically, verified accounts can read up to 6000 posts/day, unverified to 600 posts/day, and new unverified accounts to 300 posts/day.
While claiming that rate limits are meant to address issues of ‘data scraping and system manipulation,’ I have my doubts about the validity of this claim. Twitter, being one of the world’s largest social media platforms, already has a stringent policy in place to combat data scraping (refer to: developer terms and policy). They have been actively fighting against data scraping and system manipulation for over a decade. It is well-known that websites have the ability to block users’ IP addresses as a preventive measure against data scraping. While the concern regarding data scraping has grown with the emergence of large language models (LLMs) that require substantial training data, it doesn’t seem logical to impose rate limits on verified accounts. Verified accounts have already paid for the service and provided government-verified documentation, making the risk associated with these accounts quite low. As an experienced engineer, I believe that ‘data scraping and system manipulation’ are merely excuses. The actual reason behind the rate limits might be Twitter’s underlying data infrastructure not being scalable or the operational costs being too high.
Facts about Twitter and Its Underlying Data Infra
Let’s review some key events that have occurred since Elon Musk’s acquisition of Twitter on October 27, 2022:
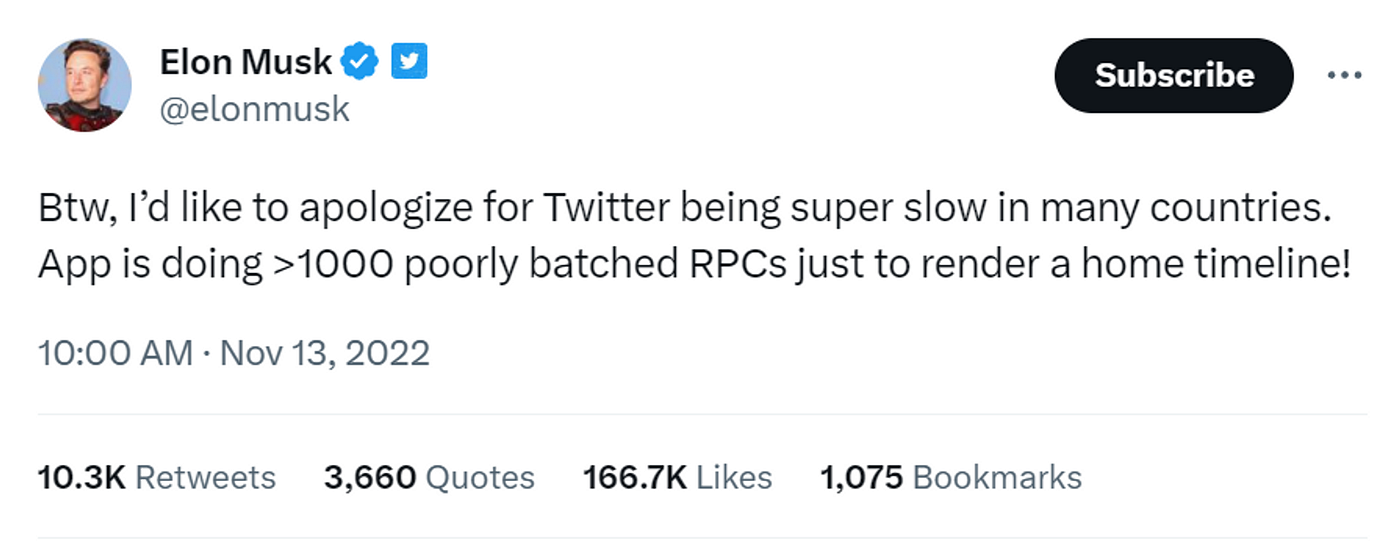
- Twitter App Performance Issues: Elon Musk publicly acknowledged that Twitter was experiencing slow performance in many countries. He attributed this issue to the app executing over 1,000 poorly batched RPCs just to render a home timeline.
- Workforce Reduction: Twitter underwent a significant downsizing, resulting in the layoff of over 6,000 employees, which accounted for approximately 80% of the company’s staff.
- Introduction of Twitter Blue: Twitter launched a paid monthly subscription called “Twitter Blue.” Subscribers to Twitter Blue receive additional features, including a blue checkmark verification badge on their accounts.
- Enhanced Tweeting Capabilities: Twitter Blue users were granted extended tweeting capabilities, allowing them to compose tweets with up to 25,000 characters. Additionally, they gained the ability to upload longer videos, up to 2 hours in length at 1080p resolution.
Okay, then what about Twitter’s data infrastructure, the backbone supporting the world’s largest social media platform? Well, Twitter has started moving from its own data center to Google Cloud several years ago (according to this Twitter Engineering blog). They believed that moving from their own data center to GCP can help efficiently process billions of events in real time, ensuring a seamless experience for its massive user base.
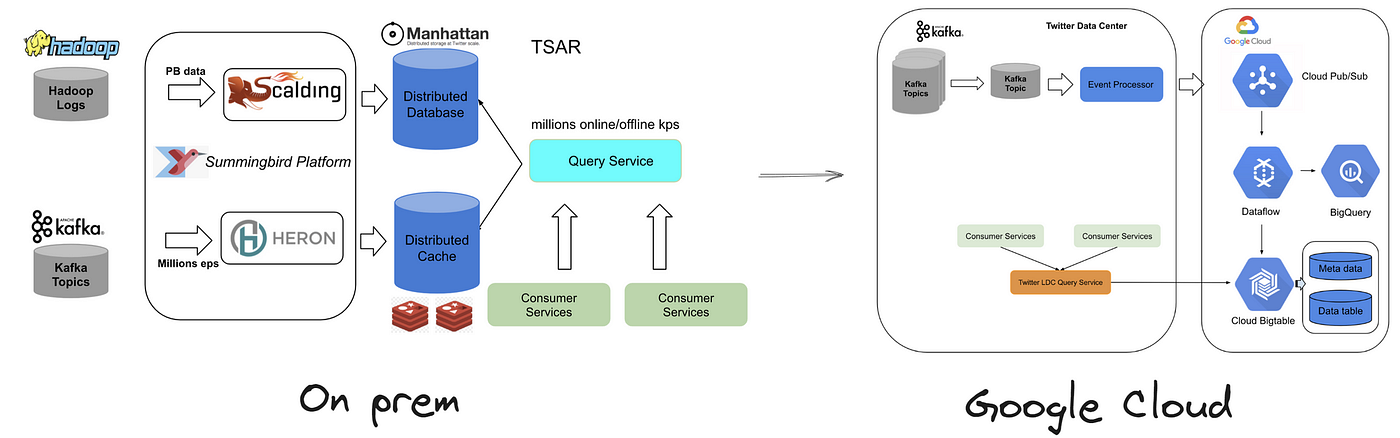
By examining all these interconnected elements, one could reasonably infer that Elon Musk had confidence in the scalability and cost-effectiveness of GCP’s services, leading to the belief that massive layoffs of Twitter engineers wouldn’t significantly impact the platform, despite existing technical debts. Concurrently, Twitter continued to introduce new features in an attempt to monetize its existing user base. However, the reality turned out to be harsh: GCP’s services proved to be prohibitively expensive and unable to deliver the desired high scalability at a reasonably low cost!
Open-Source Solutions That May Help Elon Out
To assist Elon in reducing costs and enable hundreds of millions of Twitter users to read more than 600 posts per day, I strongly recommend leveraging open-source technologies as alternatives to costly GCP-native services. Upon closer examination of Twitter’s internal architecture, we can identify four crucial components that are prime candidates for replacement.
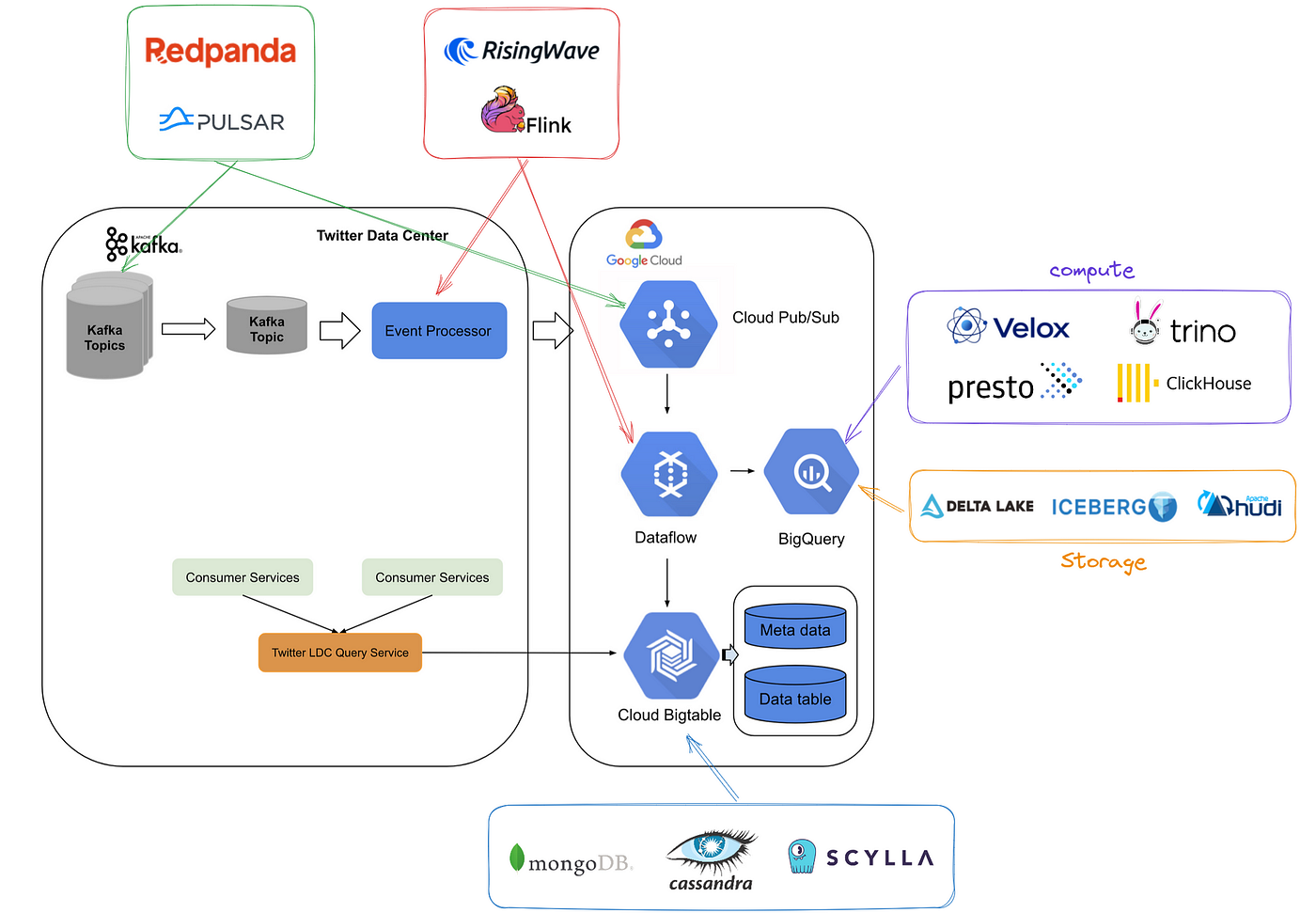
Cloud Pub/Sub
Although Twitter internally uses Apache Kafka (Apache Kafka), they also utilize Google’s Cloud Pub/Sub service. However, Twitter has the flexibility to replace Cloud Pub/Sub with alternative open-source systems, such as:
- Apache Pulsar: Pulsar is a distributed messaging platform developed under the Apache Foundation. Its notable features include extremely low latency, support for multi-tenancy, geo-replication across regions, and tiered storage capabilities.
- Redpanda: Redpanda is a straightforward, high-throughput, and cost-efficient messaging service. It is implemented in C++, compatible with Kafka, and claims to be 6 times more cost-effective than Kafka while achieving 10 times faster performance.
Dataflow
If Twitter chooses to replace Dataflow, they have two prominent open-source options available:
- Apache Flink: Flink is a unified streaming and batching platform developed under the Apache Foundation. It provides support for Java API and a SQL interface. Flink boasts a large ecosystem and can seamlessly integrate with various services, including Kafka, Pulsar, HDFS, Iceberg, Hudi, and other systems.
- RisingWave: RisingWave is a distributed SQL database designed specifically for stream processing. It aims to simplify the complexity and reduce the cost of building real-time applications. Written in Rust, RisingWave is recognized for its exceptional performance (10 times faster than Flink!) and cost-efficiency, especially in modern cloud environments. Notably, RisingWave is compatible with PostgreSQL, which makes it particularly user-friendly for those new to stream processing.
BigQuery
Here are some open-source systems that can potentially be considered as alternatives to BigQuery’s computation layer:
- Presto: Presto is an open-source distributed SQL query engine that enables querying data from various sources. It provides fast and interactive analytics capabilities, supporting a wide range of data formats and integration with different storage systems.
- Trino: Trino (formerly known as PrestoSQL) is a high-performance distributed SQL query engine designed for data analysis. It offers efficient querying capabilities across multiple data sources, including various file formats, databases, and data lakes. These are some interesting background story between Trino and Presto: Presto was the original name of the project, and it was developed by Facebook. In December 2020, a significant portion of the Presto community decided to fork the project and renamed it Trino. Read more here: Trino Blog.
- Velox: Velox is a high-performance, distributed SQL query engine developed by Facebook as a rebuild of Presto, but implemented in C++. It offers remarkable speed and has gained adoption by tech giants such as Facebook and ByteDance.
- ClickHouse: ClickHouse is an open-source columnar database management system designed for high-performance analytics. It excels at processing large volumes of data and offers real-time querying capabilities. It’s probably the world’s fastest real-time data analytics system: ClickHouse Benchmark.
BigQuery’s storage layer may be replaced by the following open-source systems:
- Apache Hudi: Apache Hudi is a distributed data lake storage system that offers near real-time data ingestion and efficient data management for big data workloads. It provides features like record-level updates and deletes, incremental data processing, and data lifecycle management.
- Apache Iceberg: Apache Iceberg is an open-source table format for large-scale data processing that focuses on providing fast and efficient analytics on huge datasets. It supports ACID transactions, schema evolution, and time-travel capabilities, making it suitable for managing and querying large volumes of data.
- Delta Lake: Delta Lake is an open-source storage layer that provides ACID transactions, scalable metadata management, and data versioning on top of existing data lakes. It aims to bring reliability and performance optimizations to big data workloads while ensuring data integrity and consistency.
Bigtable
If Twitter is looking for open-source alternatives to Bigtable, there are a few options available:
- MongoDB: MongoDB is a popular NoSQL database that provides flexibility and scalability. It offers a document-oriented data model and can handle a variety of use cases. MongoDB is known for its ease of use and rich query capabilities.
- Cassandra: Cassandra is a highly scalable and fault-tolerant NoSQL database. It is designed to handle large amounts of data across multiple commodity servers, making it suitable for high-availability and data-intensive applications.
- ScyllaDB: ScyllaDB is a NoSQL database that is compatible with Cassandra. It offers a drop-in replacement for Cassandra with improved performance and lower resource utilization. ScyllaDB claims to provide 2x to 8x better performance while requiring fewer nodes, resulting in cost savings and reduced overhead.
Conclusion
Elon shouldn’t limit read rates. There are numerous ways to achieve scalability and reduce costs. Restricting read rates, whether for paid or unpaid users, can have a profound negative impact on Twitter’s thriving ecosystem. Instead, Elon should explore open-source alternatives to Google Cloud services and work towards making Twitter a better, free, unlimited social media platform!
