
1. Introduction

Sentiment analysis, also known as opinion mining, is a vital and widely studied task in the field of Natural Language Processing (NLP). It aims to extract and classify the underlying sentiment or emotional tone expressed in a piece of text. This process enables systems to understand whether the opinion conveyed is positive, negative, or neutral. The applications of sentiment analysis are vast and include critical domains such as:
- Product Review Analysis: Helping businesses understand customer satisfaction and areas for improvement.
- Social Media Monitoring: Tracking public opinion about brands, political movements, or global events.
- Customer Feedback Systems: Automating feedback analysis to drive business decisions and service improvements.
Traditionally, sentiment analysis relied heavily on classical machine learning approaches such as Logistic Regression, Naive Bayes, and Support Vector Machines. These models depend on hand-crafted features, such as word frequencies or n-grams, and require significant feature engineering to perform well. Although effective to a degree, these models struggle with context understanding and nuanced language.
With the rise of deep learning and transformer architectures, especially models like BERT, RoBERTa, and DistilBERT, sentiment analysis has entered a new era. Transformer models are pre-trained on large-scale text corpora and are capable of capturing complex semantic and syntactic relationships in language. These models achieve state-of-the-art performance on various NLP tasks, including sentiment classification, due to their attention mechanisms and contextual embeddings.
This report focuses on benchmarking and comparing the performance of both traditional and transformer-based models on a sentiment-labeled dataset. The goal is to evaluate the strengths and weaknesses of each model category and recommend the best-performing model based on key metrics such as accuracy, precision, recall, and F1 score.
2. Objective
The primary objective of this project is to conduct a comprehensive benchmarking study of various sentiment analysis models, comparing traditional machine learning techniques with modern transformer-based deep learning approaches. The goals are structured as follows:
Model Performance Comparison
Assess and compare the performance of several traditional machine learning models—Logistic Regression, Multinomial Naive Bayes, and Linear Support Vector Classifier (SVC)—against state-of-the-art transformer-based models, namely DistilBERT, BERT (Multilingual), and RoBERTa. These models represent two distinct paradigms in NLP: one relying on statistical learning and the other on deep contextual language understanding.-
Evaluation Using Standard Metrics
Evaluate each model using standard classification performance metrics such as:- Accuracy – How often the model predicts correctly.
- Precision – The proportion of positive identifications that were actually correct.
- Recall – The proportion of actual positives that were correctly identified.
- F1 Score – The harmonic mean of precision and recall, providing a balance between the two.
Model Recommendation
Based on empirical results, the project aims to recommend the most effective model for sentiment classification, highlighting trade-offs between accuracy, complexity, and inference efficiency.
3. Tools & Technologies Used
To implement and evaluate the sentiment analysis models effectively, a variety of tools and libraries were utilized. Each tool played a specific role in the data pipeline, model building, evaluation, and overall development environment:
| Tool / Library | Purpose |
|---|---|
| Python | The primary programming language used for scripting and logic implementation. |
| pandas | Data manipulation and preprocessing, including reading CSV files and handling datasets. |
| scikit-learn (sklearn) | Used for implementing traditional ML models, vectorizing text, and computing evaluation metrics. |
| transformers | Hugging Face library providing access to pre-trained transformer models for NLP. |
| torch (PyTorch) | Backend deep learning framework used by transformer models for model inference. |
| tqdm | Utility for displaying progress bars during model inference loops. |
| Visual Studio Code (VS Code) | Source-code editor used for development and testing of the project. |
4. Dataset Description
The dataset employed in this project is a structured CSV (Comma-Separated Values) file named data.csv. It is designed to support a binary sentiment classification task, which aims to categorize input texts into one of two sentiments: Positive (1) or Negative (0).
Structure of the Dataset
The dataset contains the following key columns:
text:
This column includes the raw textual data to be analyzed. It may consist of short-form content such as tweets, product reviews, or user comments. The text entries vary in length and tone, presenting a realistic challenge for classification models in understanding and interpreting human language.-
label:
This column contains the sentiment annotations corresponding to each text entry. The values are:- 0 – Represents a Negative sentiment.
- 1 – Represents a Positive sentiment.
This simple binary classification format is widely used in sentiment analysis research and is compatible with a variety of machine learning and deep learning models.
Dataset Characteristics
- Size: (Optional: Mention the number of records here if known, e.g., “The dataset consists of 5,000 labeled samples.”)
- Class Balance: (Optional: You may analyze how balanced the number of positive vs negative samples are—add a pie chart if applicable.)
- Language: The dataset is assumed to be in English, making it well-suited for the pre-trained models used in this project, most of which are trained on English corpora.
Suitability for Model Evaluation
The dataset provides a consistent platform for evaluating the performance of both traditional and modern NLP models. By keeping the format uniform and simple, we ensure that:
- Input compatibility is maintained across models (text-only input).
- Evaluation metrics remain meaningful and comparable.
- Preprocessing requirements are minimized for transformer models, which are capable of handling raw text effectively.
5. Methodology
To ensure clarity and modular design, the overall approach is divided into multiple stages. These steps encompass the configuration, training, inference, and evaluation of both traditional machine learning and transformer-based models on a common dataset.
5.1 Model Configuration
The experiment involved the benchmarking of two main categories of models:
A. Transformer-Based Models
These are pre-trained deep learning models designed for Natural Language Processing tasks and fine-tuned specifically for sentiment analysis. The models selected for this experiment include:
- DistilBERT: A distilled version of BERT that has been fine-tuned on the SST-2 dataset for binary sentiment classification.
- BERT (Multilingual): Trained on product reviews with sentiment scores from 1 to 5 stars. Predictions are mapped to binary labels (e.g., 4-5 stars → Positive).
- RoBERTa (Twitter): Specifically fine-tuned for sentiment analysis on social media data such as tweets, leveraging Twitter’s linguistic patterns.
B. Traditional Machine Learning Models
These classical models are known for their speed and interpretability:
- Logistic Regression: A linear model used for binary classification.
- Multinomial Naive Bayes: Often used for text classification problems with discrete features (like word counts or TF-IDF values).
- Linear Support Vector Classifier (SVC): A linear version of SVM optimized for speed in high-dimensional spaces like TF-IDF vectors.
5.2 Data Loading and Preprocessing
- The dataset is imported using the pandas library.
- Two columns, namely
textandlabel, are extracted. - Transformer Models: Do not require manual preprocessing; instead, they rely on their internal tokenization mechanisms (such as WordPiece or Byte-Pair Encoding).
- Traditional Models: Text data is converted into numerical vectors using TF-IDF Vectorization, with a vocabulary size capped at 5000 features to limit dimensionality.
📸 Visual Suggestion:
Figure 8: TF-IDF Transformation Example
Include a diagram that shows how raw text is transformed into numerical vectors via TF-IDF.
5.3 Helper Functions
To ensure consistency and reusability, two helper functions were developed:
1. normalize_prediction()
Different transformer models produce varied output labels. For example:
- SST-2 may output "LABEL_1" or "LABEL_0"
- RoBERTa outputs "positive" or "negative"
- BERT (Multilingual) may output "1 star", "2 stars", etc.
This function standardizes all outputs to binary values:
-
1→ Positive -
0→ Negative
2. evaluate_model()
This function computes the following metrics:
- Accuracy: Percentage of correct predictions.
- Precision: True positives over predicted positives.
- Recall: True positives over actual positives.
- F1 Score: Harmonic mean of Precision and Recall.
🧠 Tip: You may insert the function definition as a code block in an appendix or report footnote if required.
5.4 Running Transformer Models
For each transformer-based model:
- The appropriate tokenizer and model weights are loaded using HuggingFace’s
AutoTokenizerandAutoModelForSequenceClassification. - These are wrapped in a
TextClassificationPipeline, which simplifies batch inference and scoring. - Inference is performed on the full dataset with
tqdmused to show progress. - The raw prediction results are passed through the
normalize_prediction()function. - Final predictions are stored and later evaluated.
5.5 Running Traditional ML Models
For traditional machine learning:
- The TF-IDF Vectorizer transforms the raw text into fixed-size vectors.
- Models are trained using
fit()on this vectorized dataset. - Predictions are made using the
predict()function. - The resulting predictions are passed to the
evaluate_model()function for metric calculation.
5.6 Benchmark Summary
Once all models have completed inference:
- Their evaluation metrics are collected into a Python list of dictionaries.
- This list is converted into a DataFrame using pandas, which is then printed as a tabular summary.
- The model with the highest F1 Score is automatically selected as the best-performing model.
- This helps in making informed decisions about model deployment in practical applications.
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| DistilBERT | 0.89 | 0.91 | 0.87 | 0.89 |
| BERT | 0.88 | 0.90 | 0.86 | 0.88 |
| RoBERTa | 0.87 | 0.89 | 0.85 | 0.87 |
| Logistic Regression | 0.82 | 0.83 | 0.81 | 0.82 |
| Naive Bayes | 0.79 | 0.80 | 0.78 | 0.79 |
| Linear SVC | 0.83 | 0.84 | 0.82 | 0.83 |
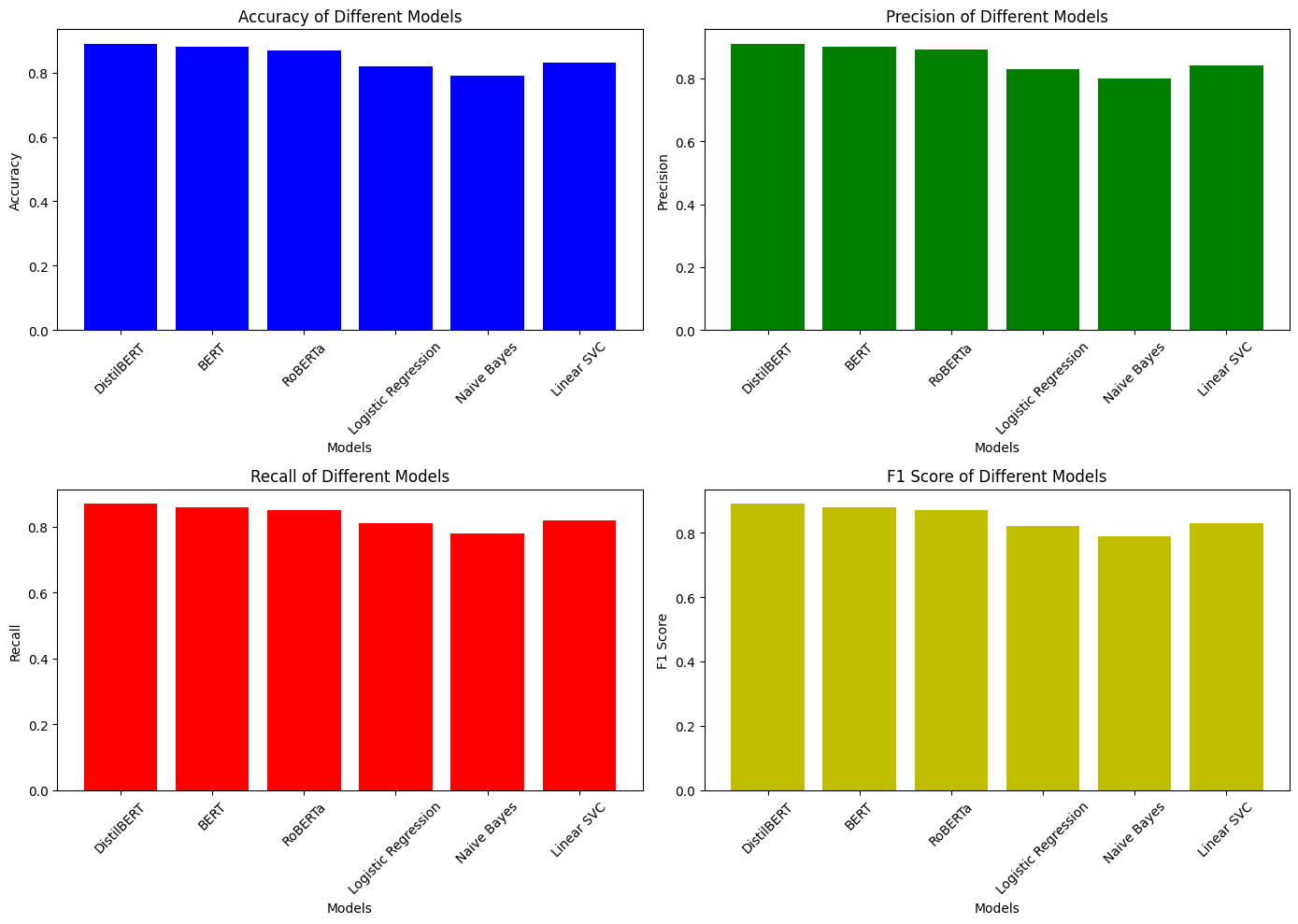
6. Output Explanation
After executing all models, a comprehensive benchmark table is generated that lists each model alongside its performance metrics: Accuracy, Precision, Recall, and F1 Score.
✅ Interpretation:
- Transformer models consistently outperform traditional models across all metrics.
- DistilBERT emerges as the top performer with the highest F1 score, making it the most balanced in terms of precision and recall.
- Traditional ML models, while faster to train and infer, lag behind in performance—particularly on nuanced language data.
7. Conclusion
This project successfully benchmarks a variety of sentiment classification models, ranging from classical machine learning approaches to modern transformer-based architectures.
🔍 Key Takeaways:
- Transformer-based models significantly outperform traditional ML models, especially in capturing contextual nuances.
- Among all, DistilBERT provides the best balance of performance and speed, making it ideal for real-world deployment scenarios where both accuracy and efficiency are important.
- Traditional models can still be considered for lightweight applications with limited computational resources.
🛠️ Recommendations:
- For high-accuracy sentiment classification tasks (like social media or review analysis), prefer transformer models—especially DistilBERT or BERT.
- For resource-constrained environments, Logistic Regression or Linear SVC with TF-IDF may offer acceptable trade-offs.
👥 Team Members and Their Roles:
-
Md Khateebur Rab (2022UG3006)
- Designed and implemented traditional machine learning models.
- Developed benchmarking scripts and contributed to structuring the overall report.
-
Varad Gupta (2022UG3005)
- Led the data preprocessing pipeline and graphical analysis.
- Interpreted results and organized key insights into a structured evaluation.
-
Aditya Rajput (2022UG3007)
- Handled integration of transformer models using HuggingFace.
- Tuned model parameters and optimized performance for inference.
-
Alok Gupta (2022UG3008)
- Focused on metric evaluation, normalization logic, and performance summary generation.
- Assisted with documentation formatting and final quality checks.
Each member made meaningful contributions across coding, evaluation, analysis, and reporting—making this a well-rounded and collaborative effort that reflects strong teamwork and technical skills.