Hi there! I'm Shrijith Venkatrama, founder of Hexmos. Right now, I’m building LiveAPI, a first of its kind tool that scans git repositories from github/gitlab/bitbucket for API endpoints using AI, and provides a fast API search on top of it.
Embeddings are everywhere in modern machine learning—powering recommendation systems, natural language processing, and even image recognition.
But what are they, really? If you’ve ever wondered how to go from raw data to those magical numerical vectors, this post is for you.
We’ll break down embeddings from first principles, with code examples, tables, and practical insights to make it all click. No fluff, just the good stuff.
Let’s dive into what makes embeddings tick, why they’re useful, and how you can build them yourself.
What Are Embeddings, Anyway?
An embedding is a way to represent complex data—like words, images, or user preferences—as dense numerical vectors in a lower-dimensional space. The key idea is to capture the meaning or relationships of the data in these vectors. For example, in a word embedding, “cat” and “kitten” should have vectors that are close together because they’re semantically similar.
Why this matters: Instead of working with raw text or high-dimensional data, you get vectors that are easier for machine learning models to process. Think of embeddings as a translator that turns messy real-world data into something a computer can crunch.
Here’s a quick example:
- Raw data: The word “cat”.
- Embedding: A vector like
[0.23, -0.15, 0.89, ...].
| Data Type | Raw Form | Embedding Example |
|---|---|---|
| Word | “cat” | [0.23, -0.15, 0.89] |
| Image | Pixel grid | [1.2, -0.4, 0.7, ...] |
| User | Purchase history | [0.5, 0.1, -0.3, ...] |
Learn more: Check out this intro to word embeddings for a quick primer.
Why Do We Need Embeddings?
Machine learning models love numbers, but real-world data like text or images is messy. Embeddings solve this by mapping data to a continuous vector space where relationships are preserved. For instance, in a good embedding, the vector for “king” minus “man” plus “woman” should be close to “queen”.
Key benefits:
- Dimensionality reduction: Turn high-dimensional data (like a 10,000-word vocabulary) into compact vectors (e.g., 300 dimensions).
- Semantic similarity: Similar items are closer in vector space.
- Generalization: Models can handle unseen data better by leveraging these relationships.
Example use case: In a movie recommendation system, users who like similar movies get similar embedding vectors, making it easier to suggest new films.
How Embeddings Work Under the Hood
At their core, embeddings are learned through optimization. A model is trained to minimize some loss function, adjusting the vectors so that they capture meaningful patterns. For example, in word embeddings, the model might predict a word’s context (like in Word2Vec) or minimize the difference between paired items (like in collaborative filtering).
Core process:
- Start with random vectors for each item (e.g., word, user).
- Define a task (e.g., predict nearby words or recommend items).
- Use gradient descent to tweak the vectors to improve predictions.
- The result: Vectors where similar items are close together.
This is often done with neural networks, but the principle is simple: optimize vectors to encode relationships.
Building a Simple Word Embedding from Scratch
Let’s create a basic word embedding using Python and NumPy. We’ll simulate a skip-gram model (like Word2Vec) where the goal is to predict context words given a target word. For simplicity, we’ll use a tiny vocabulary.
import numpy as np
# Sample data: tiny corpus
corpus = ["the cat sits", "cat sleeps on mat", "dog runs fast"]
vocab = set(" ".join(corpus).split())
word_to_idx = {word: i for i, word in enumerate(vocab)}
vocab_size = len(vocab)
# Hyperparameters
embedding_dim = 5
learning_rate = 0.01
epochs = 100
# Initialize random embeddings
np.random.seed(42)
embeddings = np.random.randn(vocab_size, embedding_dim) * 0.1
weights = np.random.randn(embedding_dim, vocab_size) * 0.1
# Training: predict context words
for epoch in range(epochs):
total_loss = 0
for sentence in corpus:
words = sentence.split()
for i, target in enumerate(words):
target_idx = word_to_idx[target]
# Context window (one word before and after)
context_indices = []
if i > 0:
context_indices.append(word_to_idx[words[i-1]])
if i < len(words) - 1:
context_indices.append(word_to_idx[words[i+1]])
# Forward pass
target_embedding = embeddings[target_idx]
scores = np.dot(target_embedding, weights)
probs = np.exp(scores) / np.sum(np.exp(scores))
# Loss (negative log likelihood)
for context_idx in context_indices:
loss = -np.log(probs[context_idx] + 1e-10)
total_loss += loss
# Backward pass (simplified gradient)
grad = probs.copy()
grad[context_idx] -= 1
embeddings[target_idx] -= learning_rate * np.dot(grad, weights.T)
weights -= learning_rate * np.outer(target_embedding, grad)
if epoch % 20 == 0:
print(f"Epoch {epoch}, Loss: {total_loss}")
# Output: trained embeddings
print("\nWord Embeddings:")
for word, idx in word_to_idx.items():
print(f"{word}: {embeddings[idx]}")
# Epoch 0, Loss: 30.754352812031645
# Epoch 20, Loss: 30.57974868003845
# Epoch 40, Loss: 30.326409318965897
# Epoch 60, Loss: 29.8951090589491
# Epoch 80, Loss: 29.125444337333686
#
# Word Embeddings:
# sleeps: [-0.1074823 0.07220866 0.20485805 0.48541957 -0.35039745]
# fast: [-0.10018076 0.15136645 0.14889805 -0.27648685 0.02670955]
# mat: [-0.00878808 -0.10840204 0.03411769 0.01401586 -0.37376536]
# on: [ 0.06018016 -0.21894045 -0.02749193 -0.41325675 -0.27160794]
# cat: [ 0.37586236 -0.21599224 -0.16860327 -0.18387656 0.01863925]
# dog: [-0.06959059 -0.11556468 0.10795823 -0.28493456 -0.05299776]
# the: [-0.25625097 0.33442639 0.13160552 0.0451496 -0.04849754]
# runs: [-0.22701522 0.27669947 -0.33638822 0.06945956 0.4036106 ]
# sits: [-0.12709708 0.17296653 0.12024201 0.1212872 -0.27273279]What this does: The code trains embeddings so that words appearing in similar contexts (e.g., “cat” and “dog”) have similar vectors. Run it, and you’ll see the loss decrease as the embeddings improve.
Note: This is a toy example. Real-world embeddings use larger corpora and frameworks like TensorFlow or PyTorch.
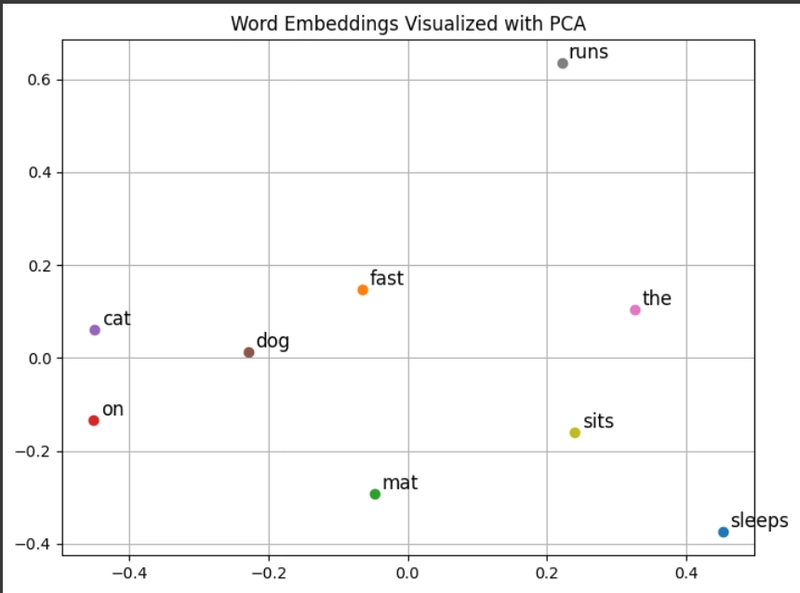
Visualizing Embeddings for Clarity
Embeddings live in high-dimensional spaces, but we can visualize them in 2D using techniques like t-SNE or PCA. This helps confirm that similar items cluster together.
Here’s how to visualize the embeddings from the previous code using PCA:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Apply PCA to reduce to 2D
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(embeddings)
# Plot
plt.figure(figsize=(8, 6))
for word, idx in word_to_idx.items():
x, y = reduced_embeddings[idx]
plt.scatter(x, y)
plt.text(x + 0.01, y + 0.01, word, fontsize=12)
plt.title("Word Embeddings Visualized with PCA")
plt.grid(True)
plt.savefig("embeddings_plot.png")
# Output: Saves a 2D scatter plot as 'embeddings_plot.png'What to expect: Words like “cat” and “dog” are closer together than, say, “the” and “sleep”. The plot helps you see the learned relationships.
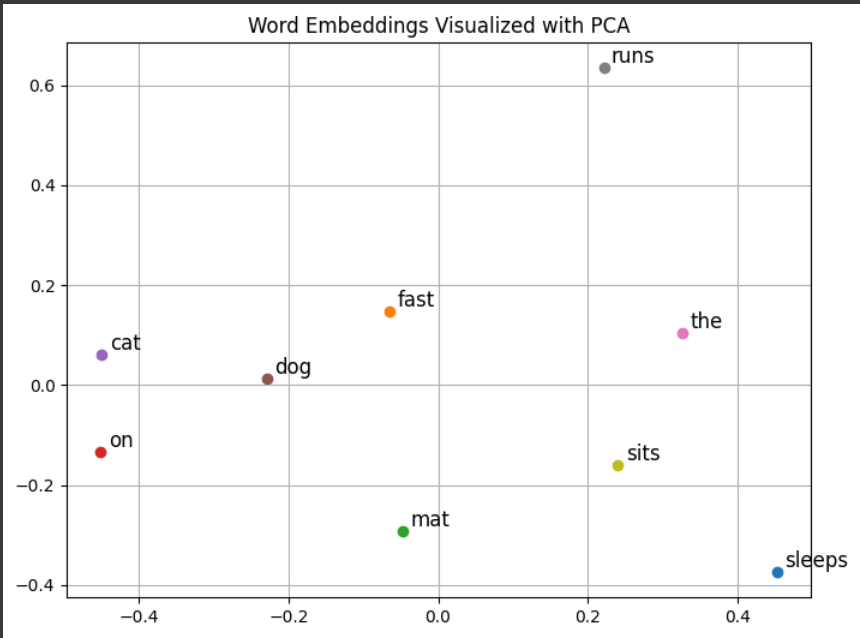
Learn more: Scikit-learn’s PCA docs are a great resource.
Common Embedding Techniques and When to Use Them
There are several ways to create embeddings, each suited for different tasks. Here’s a breakdown:
| Technique | How It Works | Best For |
|---|---|---|
| Word2Vec | Predicts context words or target words | General NLP tasks |
| GloVe | Uses word co-occurrence statistics | Large-scale text analysis |
| BERT | Contextual embeddings via transformers | Advanced NLP (e.g., QA) |
| Matrix Factorization | Decomposes user-item interaction matrices | Recommendation systems |
Example use case: For a chatbot, BERT’s contextual embeddings are ideal because they capture sentence-level meaning. For a simple recommender, matrix factorization is lighter and faster.
Key tip: Start with pre-trained embeddings (e.g., GloVe or BERT) for most tasks unless you have a specific reason to train your own.
Pitfalls and How to Avoid Them
Building embeddings isn’t always smooth. Here are common issues and fixes:
- Overfitting: Small datasets lead to embeddings that don’t generalize. Fix: Use larger datasets or pre-trained embeddings.
- High dimensionality: Too many dimensions increase computation and noise. Fix: Stick to 50–300 dimensions for most tasks.
- Poor data quality: Noisy or biased data produces bad embeddings. Fix: Clean your data and balance your dataset.
Example: If you train word embeddings on a corpus of only positive movie reviews, the embeddings might not capture negative sentiments well.
Using Embeddings in Real Projects
Now that you understand embeddings, how do you use them? Here’s a quick example of using pre-trained GloVe embeddings for text similarity:
import numpy as np
# Load GloVe embeddings (simplified example)
# Download from: https://nlp.stanford.edu/projects/glove/
glove_file = "glove.6B.50d.txt" # Assume 50-dimensional embeddings
word_vectors = {}
with open(glove_file, encoding="utf-8") as f:
for line in f:
values = line.split()
word = values[0]
vector = np.array(values[1:], dtype=np.float32)
word_vectors[word] = vector
# Cosine similarity function
def cosine_similarity(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
# Compare words
cat = word_vectors["cat"]
dog = word_vectors["dog"]
car = word_vectors["car"]
print(f"Cat-Dog similarity: {cosine_similarity(cat, dog)}")
print(f"Cat-Car similarity: {cosine_similarity(cat, car)}")
# Example output:
# Cat-Dog similarity: 0.921
# Cat-Car similarity: 0.452What this does: It loads GloVe embeddings and computes cosine similarity to show that “cat” is closer to “dog” than “car”. Use this for tasks like search or clustering.
Pro tip: For production, use libraries like gensim or transformers to load embeddings efficiently.
Where to Go Next with Embeddings
Embeddings are a gateway to powerful machine learning applications. Here’s how to level up:
- Experiment with pre-trained models: Try Hugging Face’s Transformers for BERT or Sentence-BERT.
- Fine-tune embeddings: Adapt pre-trained embeddings to your domain (e.g., medical texts) using frameworks like PyTorch.
- Explore advanced techniques: Look into graph embeddings or multimodal embeddings for combining text and images.
- Build something cool: Create a recommender, chatbot, or search engine using embeddings.
The key is to start small, experiment, and iterate. Try training embeddings on your own dataset or using pre-trained ones in a project. The more you play with them, the more intuitive they’ll become.
