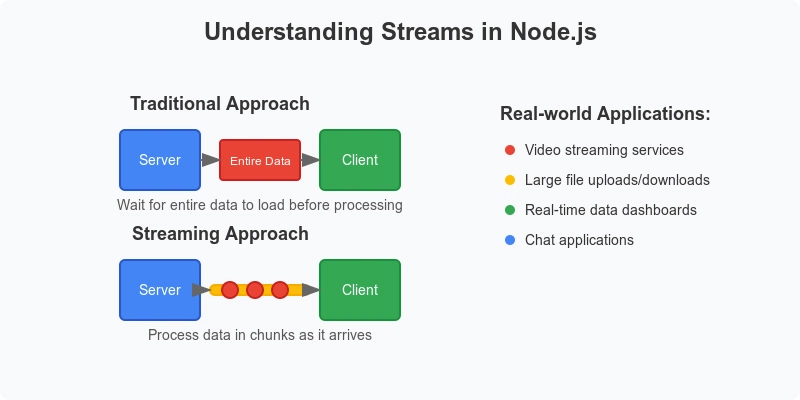
Streams in NodeJS are very effective way to send data from a source (or a network) to your browser bit-by-bit (or lets say chunks).
What does this mean?
Suppose you have two buckets, bucket A is filled with water and the other bucket is empty. You have to send the water from bucket A to bucket B.
There are two ways to do this.
- You can take another empty bucket C, take the water from bucket A and filled the bucket B
- Second option is take a pipe and make a connection between bucket A and B. The water will flow gradually.
The second option is exactly the same what streams mean.
Suppose you have data (text, video, etc) received from the server and you want to show the data in your frontend.
So to cut the long story short,
With the Streams API, you can start processing raw data with JavaScript bit by bit, as soon as it is available, without needing to generate a buffer, string, or blob
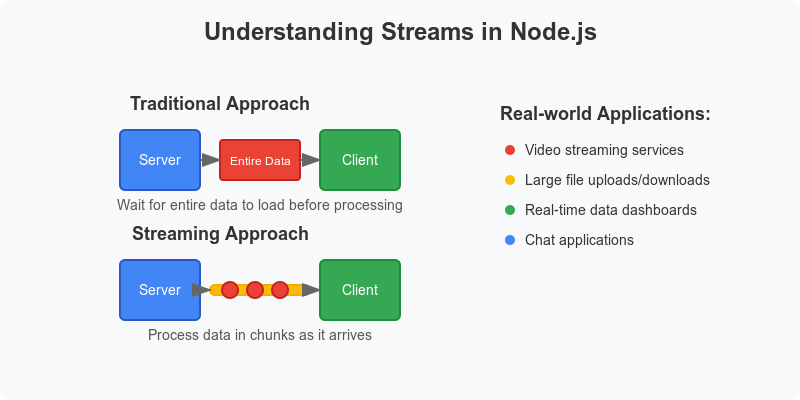
Usecases in real life application
- Video streaming services
- Large file uploads/downloads
- Real-time data dashboards
- Chat applications
- Audio processing applications
Enough motivation right? Lets move into technicals. Today I will talk about reading data in chunks and in the next day I will write about how you can process and use the data in chunks.
Using readable streams
- programmatically reading and manipulating streams of data received over the network, chunk by chunk
Lets write code .....
// Fetch the original image
fetch("https://images.pexels.com/photos/1229356/pexels-photo-1229356.jpeg?auto=compress&cs=tinysrgb&w=600")
// Retrieve its body as ReadableStream
.then((response) => console.log(response.body))
.catch((err) => console.log(err))We have made a request to access data from a specific URL. In this case this is an image.
Output:
ReadableStream { locked: false, state: 'readable', supportsBYOB: true }
Let me break it down what this output means
This is showing you the properties of the ReadableStream object that represents the image data:
- locked: false - The stream is not currently locked by a reader. When a stream is locked, it means a reader has exclusive access to it. Since your stream is unlocked, you could still attach a reader to consume its data.
- state: 'readable' - The stream is in a "readable" state, which means it contains data that can be read. Other possible states include "closed" (no more data available) and "errored" (an error occurred).
- supportsBYOB: true - This indicates that the stream supports "Bring Your Own Buffer" mode, which is an optimization that allows you to provide your own buffer for the stream to fill, reducing memory allocations.
What we have seen the "response.body" is an ReadableStream object but not the actual data i.e. the image. To get the the data we have to consume the stream by using a reader.
fetch("https://images.pexels.com/photos/1229356/pexels-photo-1229356.jpeg?auto=compress&cs=tinysrgb&w=600")
.then((response) => response.body)
.then((body) => {
const reader = body.getReader()
console.log(reader)})
.catch((err) => console.log(err))We have attached a reader to our response which we received to read the data here.
Output:
ReadableStreamDefaultReader {
stream: ReadableStream { locked: true, state: 'readable', supportsBYOB: true },
readRequests: 0,
close: Promise { }
}Invoking this method creates a reader and locks it to the stream — no other reader may read this stream until this reader is released.
- stream: This points back to the original ReadableStream from which the reader was created. Notice that now the stream has locked: true (whereas before it was false). This is because once you get a reader, it locks the stream for exclusive access.
- readRequests: This shows the number of pending read requests (currently 0). When you call reader.read(), this count would increment until the data is delivered.
- close: This is a Promise that will resolve when the stream is closed, either because all data was consumed or because the stream was explicitly canceled
Next step is to attach read() method to read data chunks out of the stream. This method returns a promise.
reader.read().then(({ done, value }) => {
/* … */
});The results can be one of three different types:
- If a chunk is available to read, the promise will be fulfilled with an object of the form { value: theChunk, done: false }.
- If the stream becomes closed, the promise will be fulfilled with an object of the form { value: undefined, done: true }.
- If the stream becomes errored, the promise will be rejected with the relevant error.
So now we have understood how the .read() works. Lets write down the code to read the full data in chunks.
First we will create a function to read all chunks from a reader.
// Function to read all chunks from a reader
function readAllChunks(reader) {
const chunks = [];
let totalSize = 0;
// Create a recursive function to read chunks
function pump() {
return reader.read().then(({ done, value }) => {
if (done) {
console.log("Stream complete. Total data size:", totalSize, "bytes");
return chunks;
}
// Store the chunk
chunks.push(value);
totalSize += value.length;
console.log("Received chunk of data, size:", value.length, "bytes");
// Continue reading
return pump();
});
}
// Start the reading process
return pump();
}Let me break this function
The readAllChunks function implements a technique for consuming a ReadableStream completely using recursion.
- chunks: An array that will store all the Uint8Array chunks read from the stream
- totalSize: A counter to track the total number of bytes read
- The pump() function: This inner function implements the recursive reading pattern. It calls reader.read(), which returns a Promise that resolves to an object with done and value properties. Each call reads the next available chunk from the stream
- When done is true, it means the stream has no more data
- Each chunk (in value) is a Uint8Array of binary data It's added to the chunks array and its length is added to the total The size of each chunk is logged for monitoring
- return pump(): This recursively calls pump() to read the next chunk The Promise chain ensures each read completes before the next one starts This continues until done becomes true
Return Value: A Promise that resolves to an array of Uint8Array chunks containing all the data from the stream.
We have written a function to recursively read data by chunks. Let see how we can incorporate this.
// Function to read all chunks from a reader
function readAllChunks(reader) {
const chunks = [];
let totalSize = 0;
// Create a recursive function to read chunks
function pump() {
return reader.read().then(({ done, value }) => {
if (done) {
console.log("Stream complete. Total data size:", totalSize, "bytes");
return chunks;
}
// Store the chunk
chunks.push(value);
totalSize += value.length;
console.log("Received chunk of data, size:", value.length, "bytes");
// Continue reading
return pump();
});
}
// Start the reading process
return pump();
}
/// Usage in our fetch example:
fetch("https://images.pexels.com/photos/1229356/pexels-photo-1229356.jpeg?auto=compress&cs=tinysrgb&w=600")
.then(response => {
const reader = response.body.getReader();
return readAllChunks(reader);
})
.then(chunks => {
// Combine all chunks into a single Uint8Array
const totalLength = chunks.reduce((total, chunk) => total + chunk.length, 0);
const combinedData = new Uint8Array(totalLength); // This creates a new Uint8Array with exactly the right size to hold all data
//For each chunk, we copy its data into the combined array and then advance the position. This builds a single contiguous array from all the separate chunks
let position = 0;
for (const chunk of chunks) {
combinedData.set(chunk, position); // Uint8Array.set() copies values from one array to another at a specific position
position += chunk.length;
}
console.log("Complete image data received:", combinedData.length, "bytes");
// Now you can work with the full image data
// For example, convert to base64 for display
return combinedData;
})
.catch(err => console.error("Error reading stream:", err));Ouput is:
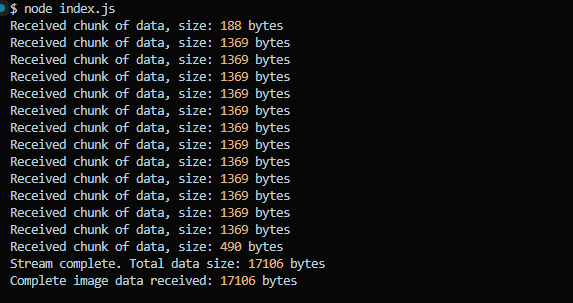
You can see how the data is read chunk by chunk.
What is exactly is happening finally here?
-The fetch() call returns a Promise that resolves to a Response object
From that Response, we extract the body ReadableStream and create a reader. We pass this reader to the readAllChunks function we discussed earlier. This returns a Promise that resolves to an array of Uint8Array chunks when the stream is fully read
Finally all of your data is read. Now you can process it furthur for your use. We will see next week.
So what we have understood today?
- Fetch a resource
- Read all chunks from its stream
- Combine those chunks into a complete dataset
- Process the complete data as needed
Thanks. Happy Reading...
Don't forget to share your thoughts....
