In our last discussion, we explored how Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by fetching external information to improve their responses.
Today, let's dive deeper into a key retrieval technique used inside RAG systems: Reciprocal Rank Fusion (RRF).
✨ What is Reciprocal Rank Fusion (RRF)?
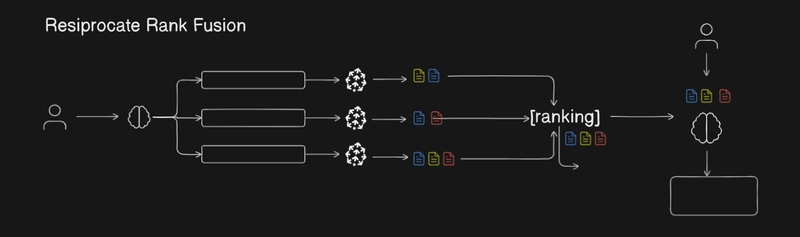
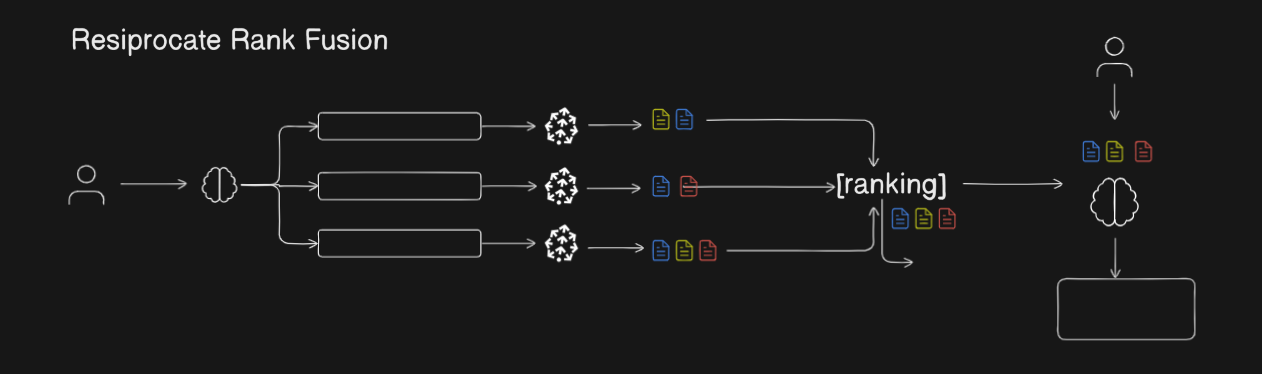
Reciprocal Rank Fusion is a simple yet powerful algorithm used to combine search results from multiple queries.
Instead of depending on just a single query to retrieve documents, RRF:
- Fans out multiple subqueries
- Retrieves results separately for each
- Merges them so that higher-ranked results are prioritized across the different searches
🔥 In short: RRF combines multiple search results intelligently so that the most relevant documents rise to the top.
🤔 Why Use RRF?
Sometimes a single query can't capture everything the user needs.
For example, if a user asks:
"What are the challenges of task decomposition?"
Depending on how it's phrased, you might miss out on some valuable documents!
✅ By generating multiple sub-questions,
✅ Retrieving documents for each sub-question, and
✅ Merging the results using RRF,
—you ensure broader coverage without losing precision.
🛠 How Does RRF Work?
Let's break it down step-by-step:
| Stage | What Happens |
|---|---|
| Subquery Generation | Create multiple focused sub-questions based on the main query. |
| Parallel Retrieval | Retrieve relevant documents separately for each sub-question. |
| Reciprocal Rank Fusion | Merge documents intelligently based on their ranks (using the RRF formula). |
| Final Selection | Select top-scoring documents for context or generation. |
🧮 The RRF Formula
Each document's RRF score is computed as:
RRF_score = ∑ (1 / (k + rank))- rank = Position of the document in the retrieval list (starting from 0)
- k = A small constant (commonly 60) that dampens the impact of lower-ranked documents.
⚡ Thus, documents that consistently rank higher across different queries will be scored higher and surfaced earlier!
🔥 Flowchart for Visual Understanding
🧩 Simple Code Snippet for Learning
Here’s a mini Python function showing how RRF merging happens:
def reciprocal_rank_fusion(subquestions, k=60):
all_ranked_results = []
# Retrieve chunks for each sub-question
for subq in subquestions:
chunks = retrieve_chunks(subq["question"])
all_ranked_results.append(chunks)
score_dict = {}
# Apply RRF scoring
for chunks in all_ranked_results:
for rank, doc in enumerate(chunks):
key = (doc.metadata.get("page"), doc.page_content.strip())
if key not in score_dict:
score_dict[key] = {"doc": doc, "score": 0}
score_dict[key]["score"] += 1 / (k + rank)
# Sort by score
fused_docs = sorted(score_dict.values(), key=lambda x: x["score"], reverse=True)
return [entry["doc"] for entry in fused_docs]📌 Highlights:
- Retrievals happen in parallel for each subquery.
- Rank and reciprocal scores intelligently merge the results.
- Final documents are sorted and fused based on their scores.
🎯 Conclusion
Reciprocal Rank Fusion (RRF) is a powerful technique that broadens context intelligently without introducing too much irrelevant information.
It ensures:
- Broader and more accurate retrieval
- Preference for high-quality, semantically rich documents
- Better context for LLMs to generate superior outputs
🌟 What's Next?
Stay tuned!
In future articles, we'll cover more advanced retrieval techniques like:
🔹 Step-Back Prompting
🔹 Chain-of-Thought Retrieval
🔹 Hybrid Search
🔹 Hierarchical Decomposition (HyDE)
